在数据平台里,“调度跑起来”从来不是一句轻描淡写的话。
当你在 UI 上点击 Start,或者一个 Cron 时间点悄然到达,背后发生的并不是“顺序执行一串任务”,而是一套 长期运行、持续决策、状态驱动的系统行为。
DolphinScheduler 的调度机制,本质上更像一个工作流操作系统内核,而不是一个定时器。
理解这一点,是理解它所有架构设计的前提。
在 DolphinScheduler 中,Trigger 只是一个“信号源”。
无论是定时触发、手动触发,还是依赖触发,最终都会被统一处理为一件事:
创建一个 Workflow Instance,并进入调度循环。
这一步非常关键,因为从这一刻起,系统关注的对象不再是 Workflow Definition,而是一个带完整运行状态的实例。
在逻辑上可以简化为:
WorkflowInstance instance = workflowInstanceService.create( workflowDefinitionId, triggerType, executionContext);
调度系统真正“跑起来”的起点,并不是任务执行,而是状态被写入元数据存储。
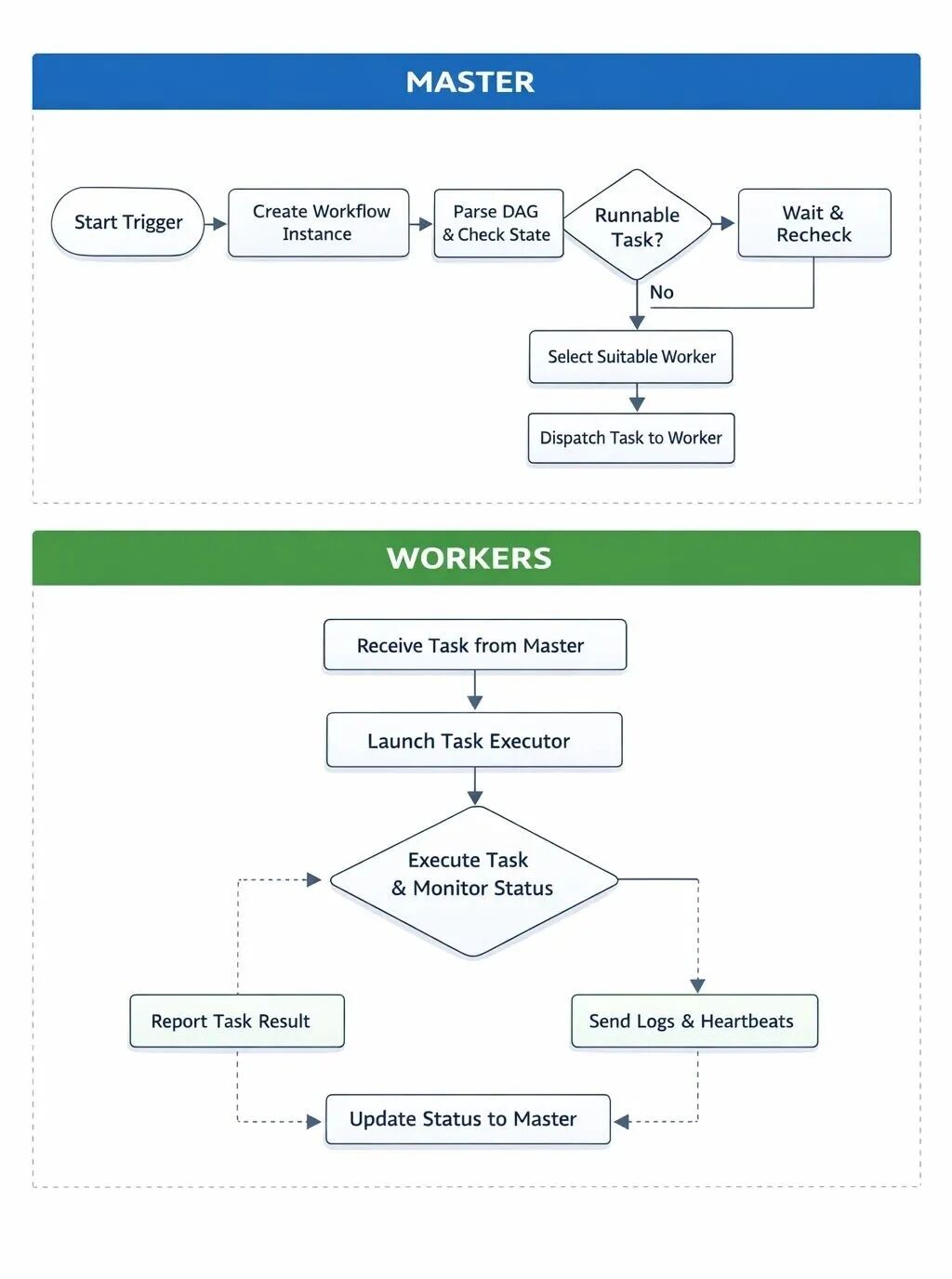
Master不是在“跑任务”,而是在“不断做判断”
很多调度系统会把大量逻辑堆进执行节点里,但 DolphinScheduler 刻意让 Master 保持“轻”。
Master 启动后,会进入一个持续运行的调度循环,本质类似这样:
while (workflowInstance.isRunning()) { List<TaskInstance> readyTasks = dag.findRunnableTasks(); for (TaskInstance task : readyTasks) { dispatch(task); } sleep(scheduleInterval);}注意这里的重点不在 dispatch,而在 findRunnableTasks()。
调度的核心不是“派发”,而是“判断”。
在定义阶段,Workflow 是一个 DAG;
但在运行阶段,它更像一张 状态不断变化的图。
每个 Task 节点至少包含以下状态维度:
- 当前运行状态(SUBMITTED / RUNNING / SUCCESS / FAILURE)
Master 在每一次调度循环中做的事情,本质是:
在当前状态快照下,重新计算“哪些节点此刻是合法可运行的”。
伪逻辑可以抽象为:
boolean canRun(TaskInstance task) { return task.state == INIT && allUpstreamTasksSuccess(task) && conditionSatisfied(task) && retryPolicyAllows(task);}这也是为什么 调度是状态驱动的,而不是事件驱动的。
事件只负责“改变状态”,而调度决策永远基于“当前全局状态”。
Master/Worker协作:
边界被刻意画得很清楚
一旦 Master 决定某个 Task Instance 可以运行,它并不会关心“怎么跑”。
它只做一件事:为这个任务选择一个合适的 Worker,并发送执行指令。
Worker worker = workerManager.select(task);workerClient.submit(task);
从这一刻起,Master 与任务的直接关系就断开了。
这条边界非常重要,它意味着:
Worker 才是真正“跑任务”的地方。
当 Worker 接收到 Task Instance 后,它会:
- 拉起对应的执行器(Shell / Spark / Flink / Python)
典型执行流程类似:
export DS_TASK_ID=12345export DS_EXECUTION_DATE=2026-02-09/bin/bash run.sh > task.log 2>&1
Worker 的世界是混乱、异构、不可预测的,这也是它必须被彻底隔离的原因。
在真实生产环境中,任务具有极强的异质性:
如果 Worker 是中心化或强绑定的,调度系统会迅速失控。
DolphinScheduler 选择了 完全对等的 Worker 模型:
- Master 只通过心跳和负载感知 Worker 状态
这使得执行层具备了天然的 弹性与容错能力。
调度系统最危险的不是任务失败,而是失败向系统核心蔓延。
如果调度线程被执行阻塞,如果 Master 需要感知执行细节,那么:
DolphinScheduler 通过强制解耦,把复杂性锁死在 Worker 侧:
这是一个非常工程化、非常成熟的系统设计选择。
如果从更高一层抽象来看,DolphinScheduler 的运行并不是“任务在跑”,而是:
状态在系统中不断流转,而调度逻辑只是对状态变化的持续响应。
Trigger 只是状态的起点,
Worker 只是状态的制造者,
Master 则是状态的裁判。
理解这一点,你就会明白为什么:
很多人用调度系统,只关心“能不能跑”;
真正长期维护调度系统的人,关心的是:
DolphinScheduler 的调度机制,正是为这些长期问题而设计的。
下一篇我们继续深入,了解调度系统真正的灵魂:状态机。
Apache DolphinScheduler 3.3.2 正式发布!性能与稳定性有重要更新- GitHub: https://github.com/apache/dolphinscheduler
- 官网:https://dolphinscheduler.apache.org/en-us
- 订阅开发者邮件:dev@dolphinscheduler@apache.org(向邮箱发送任意内容,收到邮件后回复同意订阅即可)
- YouTube:https://www.youtube.com/@apachedolphinscheduler
- Slack:https://join.slack.com/t/asf-dolphinscheduler/shared_invite/zt-1cmrxsio1-nJHxRJa44jfkrNL_Nsy9Qg
同样地,参与Apache DolphinScheduler 有非常多的参与贡献的方式,主要分为代码方式和非代码方式两种。
非代码方式包括:
完善文档、翻译文档;翻译技术性、实践性文章;投稿实践性、原理性文章;成为布道师;社区管理、答疑;会议分享;测试反馈;用户反馈等。
代码方式包括:
查找Bug;编写修复代码;开发新功能;提交代码贡献;参与代码审查等。
贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/pulls?q=is%3Apr+is%3Aopen+label%3A%22first+time+contributor%22优先级问题列表:https://github.com/apache/dolphinscheduler/pulls?q=is%3Apr+is%3Aopen+label%3Apriority%3Ahigh如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/docs/3.2.2/%E8%B4%A1%E7%8C%AE%E6%8C%87%E5%8D%97_menu/%E5%A6%82%E4%BD%95%E5%8F%82%E4%B8%8E_menuhttps://github.com/apache/dolphinscheduler