"设计一个能支撑万亿级数据同步的系统挑战有多大?来告诉你一个从0到1的故事..."
一个深夜的求助
2021年的一个深夜,正准备关电脑休息,一个运维电话打了进来:
"救命!整个数据同步系统都崩溃了,3000多张表的同步全部积压,业务系统已经开始报警了..."
电话那头是业务线技术负责人,声音中带着焦虑。这不是数据平台第一次接到类似求助,但这次的规模确实让人吃惊:
经过通宵紧急补丁程序发布才算临时解决,事后进行复盘加上跟社区的用户们进行交流后,发现类似的问题在社区也经常被大家遇到,这不仅仅是一个技术问题,更是整个行业的痛点。
经过分析,团队发现传统数据同步系统存在几大致命问题:

我们仔细梳理了数据同步与集成业务的场景
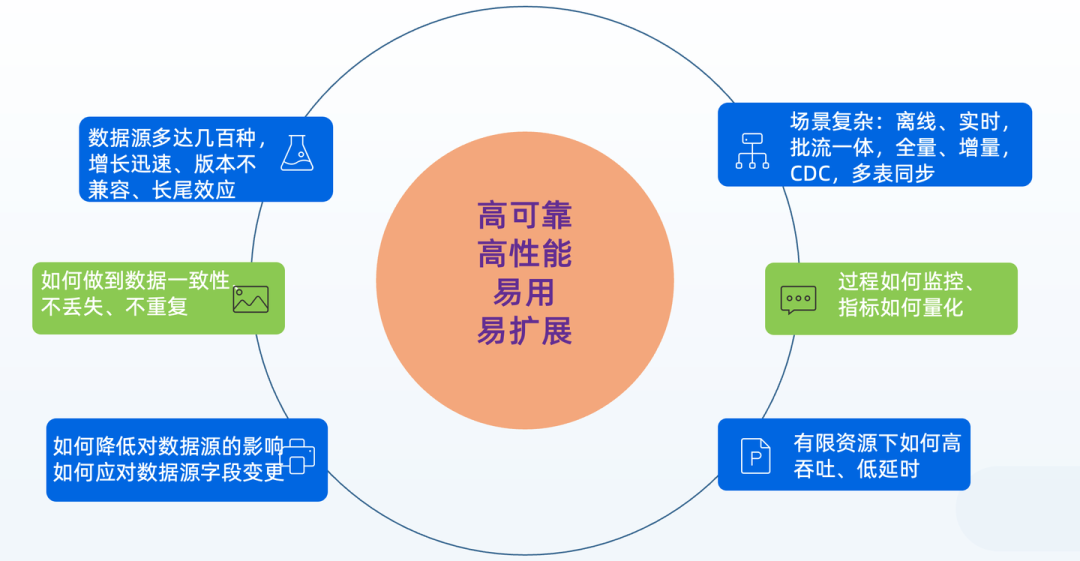
要命的是,当时市面上的解决方案都不尽如人意:
正是这些现实问题,促使我们开始了SeaTunnel 新引擎的设计之旅。
一句题外话,Zeta 现在被社区亲切的称之为 “泽塔奥特曼”,给人类带来光和希望,Zeta 也正在给数据集成行业注入全新的动力引擎。
从需求到架构
设计目标
团队给自己定了几个看似"不可能完成"的目标:
核心架构
经过和社区的各路大神连续几个月 N 多次讨论和迭代,我们最终确定了这样的架构:
┌───────────────────────────────────────────┐
│ SeaTunnel API Layer │
├───────────────────────────────────────────┤
│ │
│ ┌─────────┐ ┌─────────┐ │
│ │ Source │ │ Sink │ │
│ └─────────┘ └─────────┘ │
│ │
│ ┌─────────┐ ┌─────────┐ │
│ │Transform│ │Connector│ │
│ └─────────┘ └─────────┘ │
│ │
├───────────────────────────────────────────┤
│ Plugin Discovery Layer │
├───────────────────────────────────────────┤
│ Multi-Engine Support │
│ ┌────────┐ ┌─────────┐ ┌────────┐ │
│ │ Flink │ │ Spark │ │ Zeta │ │
│ └────────┘ └─────────┘ └────────┘ │
└───────────────────────────────────────────┘
那既然社区花了 2 年时间在打造一个全新的同步引擎,SeaTunnel 到底做了哪些让人耳目一新的创新呢?
SeaTunnel 的核心技术创新
2.0 多引擎支持
这是社区做的一件大事,让我们一起从多个角度深入分析 SeaTunnel 为什么要做多引擎支持。
历史背景:
SeaTunnel 引擎发展历程:
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ 2017-2019 │ │ 2019-2021 │ │ 2021-至今 │
│ 仅支持Spark │ => │ 增加Flink支持 │ => │ 自研Zeta引擎 │
└─────────────────┘ └─────────────────┘ └─────────────────┘
最初的选择 - Spark
实时需求推动下 - Flink
Zeta 横空出世
而随着数据量和场景的深入,我们逐渐的意识到 Spark 和 Flink 的突出优势是作为计算引擎而生的,用户需要的是能满足同步场景的引擎,比如用户需要:
而还有一个也很痛的点儿是 Spark 和 Flink 发的版本中间间是有很多不兼容的,比如你适配了 Flink 1.13,然后 Flink 1.14 发布了,需要再重新适配一遍 1.14,这么多 Connector 都需要重新适配,适配量非常大。
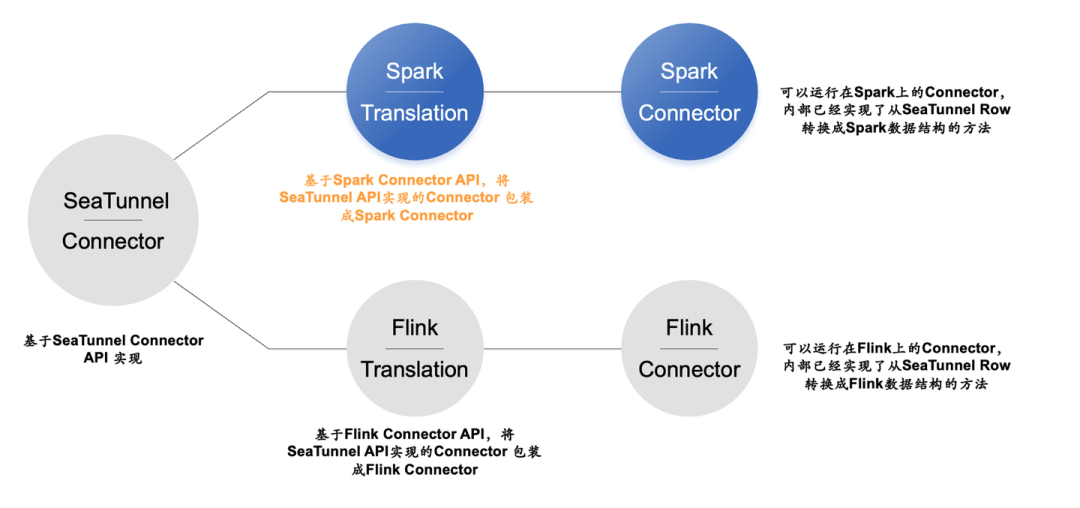
在社区大佬们的一致努力下,SeaTunnel Zeta 引擎横空出世,Zeta 引擎的优秀设计如今已经成为很多社区的学习对象,比如 SeaTunnel 做了第一个大动作就是添加了一个 Translation 翻译层,SeaTunnel 通过翻译层实现了不同引擎版本的兼容,所以 SeaTunnel 可以支持 Zeta、Flink、Spark 引擎之一作为运行时引擎
适配层结构:
┌─────────────────────────────────────┐
│ SeaTunnel API Layer │
├─────────────────────────────────────┤
│ Translation Layer │
├──────────┬──────────┬──────────────┤
│ Spark │ Flink │ Zeta │
│Translator│Translator│ Translator │
└──────────┴──────────┴──────────────┘
下图为 SeaTunnel 对 Flink 和 Spark 的支持实现:
智能连接池管理
传统数据同步系统最大的性能瓶颈之一就是数据库连接资源的浪费。智能连接池 不再是一张表一个连接,而是根据负载动态分配:
优化前
Table1 ──► Connection1
Table2 ──► Connection2
Table3 ──► Connection3
优化后
Table1 ┐
Table2 ├──► Shared Connection Pool (动态分配)
Table3 ┘
(100 tables = ~10 connections)
零拷贝数据传输
传统方案
Source ──► Memory ──► Transform ──► Memory ──► Sink
SeaTunnel方案
Source ═══════► Transform ═══════► Sink (直接内存传输)
自适应反压
Fast Producer Slow Consumer
│ │
▼ ▼
[||||||||] → [|||]
Buffer Process
│
Back Pressure
动态线程调度
SeaTunnel 使用了动态线程调度技术,这种设计带来的性能提升是惊人的:
Traditional Thread Pool:
Fixed Size: 100 threads
│││││││││││ (Many idle threads)
└─────────┘
SeaTunnel Dynamic Thread Pool:
Adaptive Size: 10-50 threads
│││││ (Efficient utilization)
└───┘
插件化设计
SeaTunnel 的插件系统采用了 SPI(Service Provider Interface) + 动态类加载的方式,主要包含以下几个核心组件:
Plugin System Architecture
┌─────────────────────────────────────┐
│ Plugin Discovery Layer │
├─────────────────────────────────────┤
│ │
│ ┌──────────┐ ┌──────────┐ │
│ │ Source │ │ Sink │ │
│ │ Plugins │ │ Plugins │ │
│ └──────────┘ └──────────┘ │
│ │
│ ┌──────────┐ ┌──────────┐ │
│ │Transform │ │ Factory │ │
│ │ Plugins │ │Discovery │ │
│ └──────────┘ └──────────┘ │
│ │
├─────────────────────────────────────┤
│ Plugin ClassLoader Layer │
└─────────────────────────────────────┘
整个插件的加载流程如下:
1. 扫描插件目录
┌────────────────┐
│ Scan Plugins │
└───────┬────────┘
▼
2. 创建类加载器
┌────────────────┐
│Create Loader │
└───────┬────────┘
▼
3. 加载插件配置
┌────────────────┐
│ Load Config │
└───────┬────────┘
▼
4. 初始化插件
┌────────────────┐
│Init Plugin │
└────────────────┘
在实践过程,我们遇到 1 个棘手问题:
不少用户是 hive1、hive2、hive3 及各厂商又自己改造的 hive 版本,这样不可避免遇到的问题就是怎么让 Connector 之间可以保持兼容,这时候社区提出来插件隔离机制来解决这个问题,SeaTunnel 通过自定义的类加载器实现了插件间的隔离:
ClassLoader Hierarchy:
Bootstrap ClassLoader
▲
│
System ClassLoader
▲
│
SeaTunnel ClassLoader
▲
│
Plugin-specific ClassLoader
技术背后的故事
在开发过程中,我们也遇到了一些有趣的挑战:
内存泄漏之谜
有一次,系统运行一段时间后内存在持续的上涨。经过几天的跟踪排查,发现是因为某些特殊字符导致的内存溢出。
解决过程也不难,关键但找到问题着实让我们出了一身冷汗。
幽灵数据问题
在全量同步时,偶尔会出现一些"幽灵数据"。最后发现是因为批处理时没有正确处理边界情况,导致出现了短暂的数据不一致。
性能断崖
系统在处理某些特定数据模式时,性能会突然下降 40%。通过添加自适应批处理机制,完美解决了这个问题。
结语
正如 Linus Torvalds 说过的:"Talk is cheap. Show me the code."
但今天我想说的是:"Code is cheap. Show me the value."
技术的价值不在于它有多复杂,而在于它能解决多少实际问题。
SeaTunnel 的成功证明:有时候,最优雅的解决方案往往是最简单的。
白鲸开源是一家开源原生的商业公司,是国家高新技术企业,由多个Apache Foundation Member成立,80%员工都是 Apache Committer,运营2个全球Apache开源项目(, SeaTunnel)。白鲸开源已根据全球最佳实践发布商业版产品WhaleStudio(含白鲸数据调度平台和白鲸数据集成平台)。我们致力于打造下一代开源原生的DataOps 平台,助力企业在大数据和云时代,智能化地完成多数据源、多云及信创环境的数据集成、调度开发和治理,以提高企业解决数据问题的效率,提升企业分析洞察能力和决策能力。
如果您希望深入了解文中提到的数据质量功能,或者讨论如何将 WhaleStudio 与你的业务流程相结合,我们非常愿意为你提供帮助。欢迎扫码获取WhaleStudio产品白皮书。








