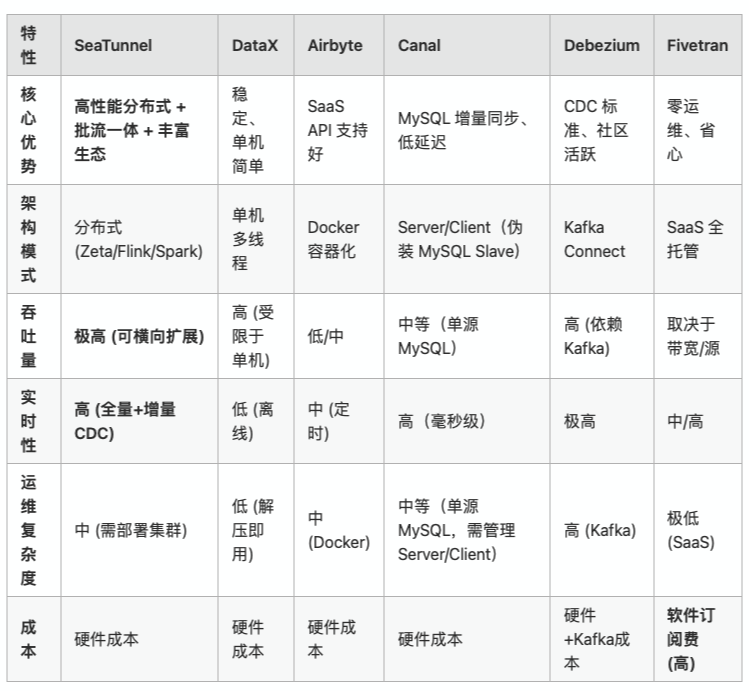
当数据量变大、数据源复杂、实时需求提高,很多团队在选数据同步工具时犯难。本文对 DataX、Airbyte、Canal、Debezium、Fivetran 与 Apache SeaTunnel
简介 : DataX 是阿里巴巴开源的离线数据同步工具/平台,实现了包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、HBase、OTS、ODPS 等各种异构数据源之间高效的数据同步功能。
架构 : Framework + Plugin 架构。采用单进程多线程模式完成数据的传输。
优点 1. 稳定性极高 :经过阿里内部海量数据验证。 2. 无外部依赖 :单机部署,开箱即用。 3. 插件丰富 :支持几乎所有主流关系型数据库和大数据存储。 4. 流控能力强 :支持字节/记录级别的精准限速。 SeaTunnel 支持 分布式运行 (基于 Zeta/Flink/Spark),突破了 DataX 的单机吞吐瓶颈。对于海量数据(TB/PB级),可通过横向扩展节点线性提升性能。 缺点 1. 单机瓶颈 :受限于单机内存和 CPU。 2. 缺乏实时性 :专注于离线批处理。 3. 运维成本 :缺乏统一的官方 Web 管控界面。 SeaTunnel 是 批流一体 架构,同一套代码既可以跑离线也可以跑实时 CDC,而 DataX 几乎只能做离线 T+1。 适用场景 每天定时进行的 T+1 全量/增量数据同步;中小规模数据的迁移。
简介 : Airbyte 是目前 GitHub 上最活跃的新一代开源 ELT(Extract, Load, Transform)平台,旨在解决集成长尾数据源(SaaS API 等)的难题。
架构 : 基于 Docker 容器化运行,每个 Connector 都是一个独立的 Docker 镜像,通过标准输入输出与核心平台通信。
优点 1. Connector 生态庞大 :支持 300+ 数据源,特别是 SaaS API。 2. 易用性好 :现代化 Web UI。 3. 标准化协议 :Airbyte Protocol 便于开发 Connector。 SeaTunnel 基于 Java 原生开发,性能更高,处理大数据量时更稳定。 缺点 1. 性能限制 :大规模数据处理能力弱。 2. 资源消耗大 :每个作业需启动 Docker 容器。 3. 稳定性 :高并发场景不如 Java 原生引擎。 SeaTunnel 无需 Docker,可在物理机/VM 上高效运行,资源利用率更高。 适用场景 中小规模 ELT 任务,SaaS 数据汇聚到数仓。
简介 : 阿里巴巴开源的基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费的中间件。主要定位是 CDC(Change Data Capture)。
架构 : Server/Client 架构。Canal Server 伪装成 MySQL Slave 订阅 binlog,Client 消费数据。
简介 : Debezium 是一个开源的分布式 CDC 平台,通常构建在 Apache Kafka 之上。
架构 : 作为 Kafka Connect 的 Source Connector 运行,也可以作为嵌入式库(Debezium Engine)运行。
优点 1. 多数据库支持 :原生支持主流 DB CDC。 2. 标准化 :CDC 领域事实标准。 3. 快照+增量 :自动无锁快照。 SeaTunnel 集成 Debezium 引擎能力,无需 Kafka 依赖,支持轻量、直连同步。 缺点 1. 架构重 :依赖 Kafka 和 Zookeeper/KRaft。 2. 数据转换弱 :只捕获数据,复杂 ETL 下游处理。 3. 格式膨胀 :默认 JSON 消息大。 SeaTunnel 提供丰富 Transform 插件,可在同步过程中完成清洗与转换。 适用场景 构建事件流架构;多源异构数据库实时 CDC 采集。
简介 : Fivetran 是全球领先的自动化数据移动平台(SaaS),专注于将数据从各种源同步到云数仓。
架构 : 全托管 SaaS 服务,闭源。
优点 1. 零运维 :全托管 SaaS。 2. 自动处理幂等和重试 。 3. 内置 dbt 转换支持 。 SeaTunnel 开源免费,可私有化部署,数据不出域,满足金融/政企合规。 缺点 1. 昂贵 :按行计费。 2. 数据合规风险 :数据必须经过云端。 3. 黑盒 :无法定制。 SeaTunnel 可自定义 Connector 与 Transform,代码完全可控。 适用场景
Apache SeaTunnel(Apache 基金会)
简介 : Apache SeaTunnel 是 Apache 基金会旗下的下一代高性能数据集成平台,定位于 统一的数据同步与集成引擎 。它既不是单纯的离线同步工具(如 DataX),也不仅是 CDC 组件(如 Canal / Debezium),而是面向现代数据平台(Lakehouse / Real-time DW)的 批流一体数据集成基础设施 。
SeaTunnel 致力于解决一个核心问题:
如何用一套引擎,统一处理“全量 + 增量 + 实时 + 多源异构”的数据流动问题。
架构 : SeaTunnel 采用 插件化 + 分布式执行引擎 架构,支持多种运行模式:
Zeta Engine(官方原生引擎)
Apache Flink
Apache Spark
整体架构可以抽象为:
Source → Transform → Sink 但与传统工具不同的是,这条链路可以在 分布式环境下并行执行 ,并具备完整的状态管理、容错与一致性保障。
优点 1. 真正的分布式架构 :可横向扩展,突破单机瓶颈。 2. 批流一体 :同一套 Connector 同时支持 Batch / Stream / CDC。 3. 多源 CDC 能力 :MySQL、PostgreSQL、Oracle、SQLServer、MongoDB 等。 4. 强 ETL 能力 :内置 SQL Transform、Filter、Replace、Split 等。 5. Exactly-Once 语义 :Checkpoint + 2PC,保证端到端一致性。 缺点 1. 学习成本高于 DataX :需要理解分布式执行模型。 2. 部署复杂度中等 :相比 SaaS 工具需要一定运维能力。 适用场景 1. TB/PB 级数据同步与迁移 2. 数据湖(Iceberg / Hudi)实时入湖 3. 数仓实时同步(OLTP → OLAP) 4. 统一全量 + 增量 + CDC 的数据集成体系
Apache SeaTunnel 不仅仅是上述工具的简单替代品,它通过 下一代数据集成架构 解决了传统工具难以兼顾的痛点。以下是选择 SeaTunnel 的深度理由:
1. 突破性能瓶颈:真正的分布式并行处理 (vs DataX) 2. 架构极简主义:无 Kafka 依赖的 CDC (vs Debezium/Canal) 痛点: 传统 CDC 架构(如 Debezium)通常强绑定 Kafka,要求企业维护一套复杂的 MQ 集群,链路长(DB -> Kafka -> Consumer -> Sink),延迟高且故障点多。
SeaTunnel 方案: 实现了 Source 到 Sink 的 直连同步 。SeaTunnel 内部处理了 binlog 的解析与缓冲,无需中间件即可将 MySQL/PG 数据实时写入 Hudi/Iceberg/Doris,大幅降低了架构复杂度和维护成本。
3. 批流一体的统一体验 (vs 割裂的工具栈) 4. 内置强大的数据处理能力 (ETL vs ELT) 5. 企业级的一致性与容错 (vs 简单的脚本) 6. 自主可控与合规 (vs Fivetran) 通过以上对比可以看出,随着数据规模和实时性要求不断提升,统一的数据集成能力愈发关键。Apache SeaTunnel 提供了一条可落地、可扩展的技术路径,在性能、可靠性和架构灵活性等方面具备显著优势,也值得在实际场景中进一步探索和验证。
Apache SeaTunnel Apache SeaTunnel是一个云原生的多模态、高性能海量数据集成工具。北京时间 2023 年 6 月1 日,全球最大的开源软件基金会ApacheSoftware Foundation正式宣布SeaTunnel毕业成为Apache顶级项目。目前,SeaTunnel在GitHub上Star数量已达9.1k+,社区达到7000+人规模。SeaTunnel支持在云数据库、本地数据源、SaaS、大模型等170多种数据源之间进行数据实时和批量同步,支持CDC、DDL变更、整库同步等功能,更是可以和大模型打通,让大模型链接企业内部的数据。
https://github.com/apache/seatunnel https://seatunnel.apache.org/ https://seatunnel.apache.org/download 我们相信,在 「 Community Over Code 」 (社区大于代码)、 「Open and Cooperation」 (开放协作)、 「Meritocracy」 (精英管理)、以及「 多样性与共识决策」 等 The Apache Way 的指引下,我们将迎来更加多元化和包容的社区生态,共建开源精神带来的技术进步! 我们诚邀各位有志于让本土开源立足全球的伙伴加入 SeaTunnel 贡献者大家庭,一起共建开源! https://github.com/apache/seatunnel/issues https://github.com/apache/seatunnel/pulls dev-subscribe@seatunnel.apache.org https://join.slack.com/t/apacheseatunnel/shared_invite/zt-1kcxzyrxz-lKcF3BAyzHEmpcc4OSaCjQ https://x.com/ASFSeaTunnel