最近在使用SeaTunnel
CDC的 startup.mode 的timestamp底层是怎样实现的? SeaTunnel的Checkpoint机制与CDC任务是如何联动的
首先,整个CDC数据读取分为快照(全量)-》回填-》增量:
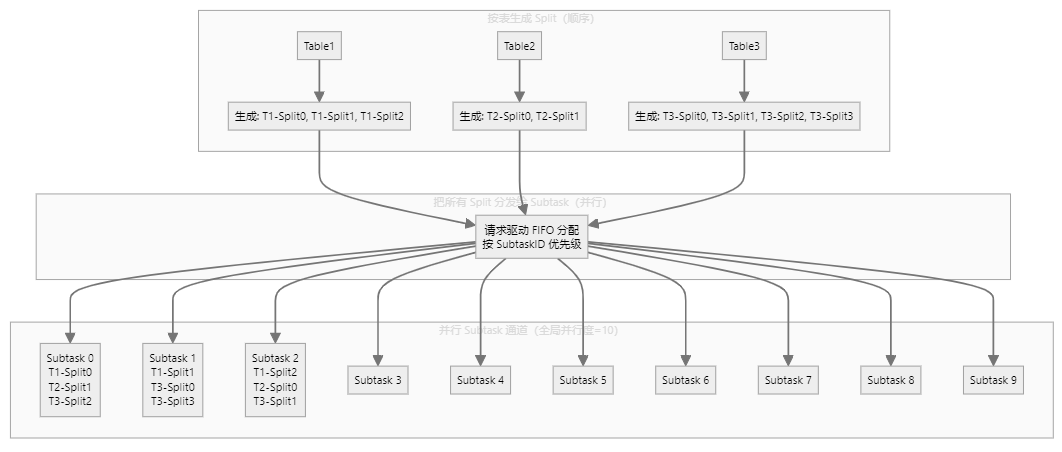
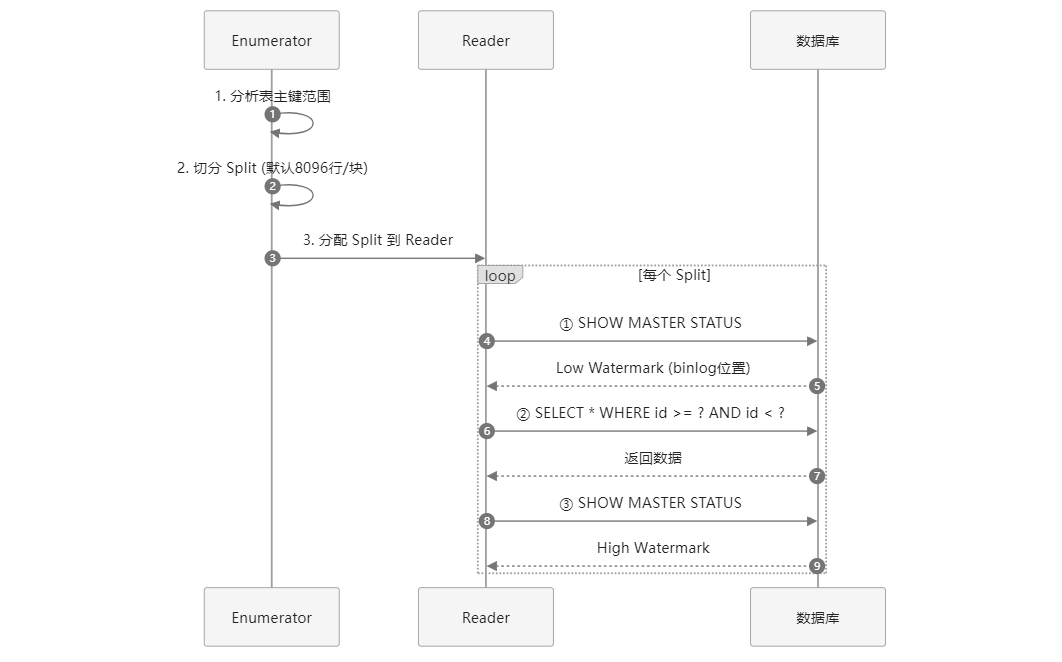
快照, 顾名思义,就是对数据库当前的数据打一份快照,全部读过来,目前SeaTunnel的实现就是纯jdbc读取,但是在读取的时候会记录一下当前的binlog位点,比如mysql,会执行 SHOW MASTER STATUS; 拿到如下信息 : File |Position |Binlog_Do_DB|Binlog_Ignore_DB|Executed_Gtid_Set| binlog.000011|1001373553| | | | 此时把这两个信息存储下来保存为 低水位线, 注意这个并不只执行一次,因为SeaTunnel为了提高性能,自主设计了切分逻辑,这块可以参考我得另一篇文章 SeaTunnel 如何给 MySQL 表做“精准切片”?一篇读懂 CDC 分片黑科技 :假设全局并行度是10,那么SeaTunnel会初始化10个通道来划分任务执行,SeaTunnel第一步会先分析表的数量 然后按照主键的最大最小值去切分,默认切分行是8096,那么一个表数据量大的情况下会切分100多个块随机分布到这10个通道里(此时数据读取任务还没执行,只是一个query语句按照where条件去切分好然后存下来),所有表切分后,每个块并行执行:
当每个块( SELECT \* FROM user\_orders WHERE order\_id \>\= 1 AND order\_id \< 10001; )开始执行的时候,会记录当前的binlog位点,当做这个块的低水位线,然后等这个块读取完了,再次执行 SHOW MASTER STATUS ,记录当前的位点为该块的高水位线,一个块执行完了 下个块随即执行,代码如下:
protected SnapshotResult doExecute (...) { BinlogOffset lowWatermark = currentBinlogOffset(jdbcConnection); dispatcher.dispatchWatermarkEvent(..., lowWatermark, WatermarkKind.LOW); createDataEvents(ctx, snapshotSplit.getTableId()); BinlogOffset highWatermark = currentBinlogOffset(jdbcConnection); dispatcher.dispatchWatermarkEvent(..., highWatermark, WatermarkKind.HIGH); } 注意事项:尽可能把split_size设置大一点,比如10w,因为根据实践证明,切的块并不是越多越好。
回填阶段:该阶段有两种形态,对应参数exactly_once这个参数 Exactly-Once = false (默认)
如果不开启,那么等所有块读完后,会对比所有块的水位线,然后拿到最小的水位线信息,开始读取数据,此时就不是jdbc读取了,而是cdc读取,比如mysql是读取binglog文件,Oracle是分析redo log文件,提取数据,根据数据类型去执行对应insert 、update、delete语句,这时候发送的每一条数据都会自带Position或者scn属性,也就是offset,每来一条 就会 和高水位线的位置信息对比,如果超过高水位线了,那么就说明要进入纯增量阶段了。
Exactly-Once = true
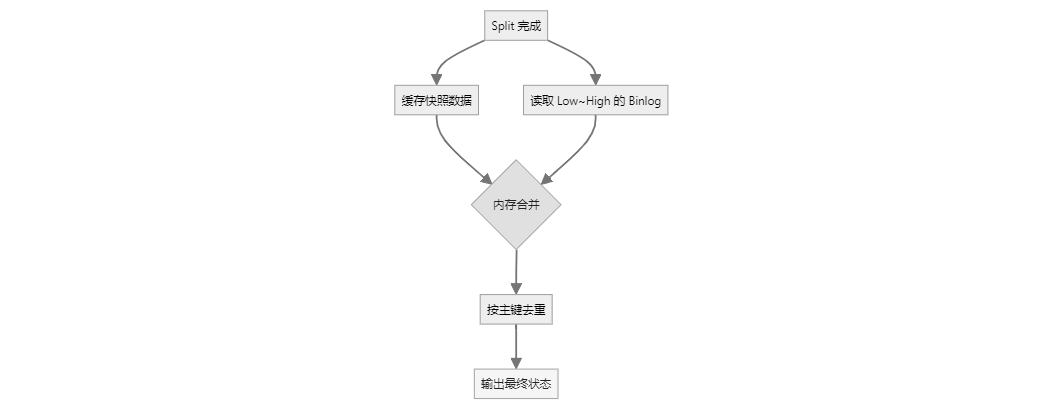
如果设置exactly_once=true,对于每个块,源端不会立刻写入,而是缓存起来,同时SeaTunnel会启动一个binlog读取任务 但是设置成了有界流,开头是每个块的低水位线,结束是每个块的高水位线,把这期间从日志解析出来的数据全部缓存下来 然后每个块的数据也有缓存,根据主键进行对比,比如在快照阶段有insert,在增量阶段有update,那么对比下来只拿update后的数据就行,然后再插入到目的端,这样来保证精确一次语义, 当然也比较耗内存!
增量阶段 : 纯日志读取
如果开启了exactly_once,那么SeaTunnel会再次启动一个无界流也就是 从高水位线开始读取数据,如果不开启的话,会直接顺着回填阶段往下走,可以说此时的回填和增量是一体的,区别就在于一个从低水位线读,一个从高水位线读。
总结:
1. 两种形态 开启 exactly_once (精确一次) 快照 :读低水位线时刻的全量数据
回填 :补齐 [低水位线, 高水位线] 期间的变更
增量 :高水位线之后的实时流
代价是:
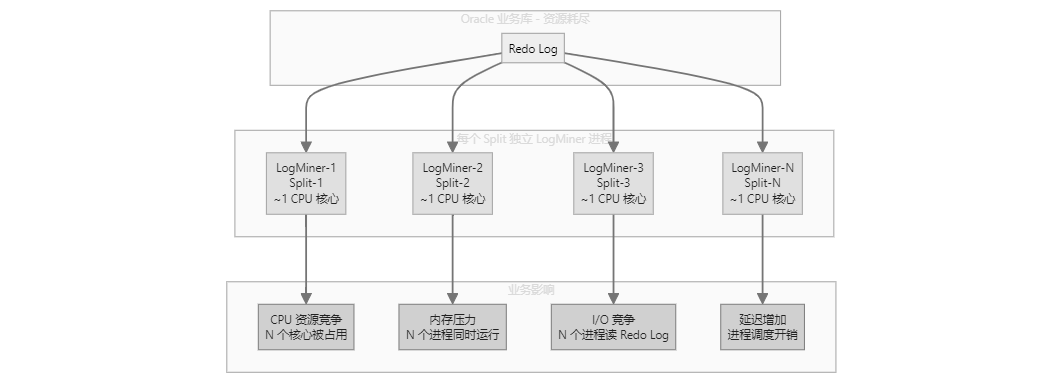
需要维护更多状态(内存压力大,特别是块多/表多时)。 对于 Oracle 这类用 LogMiner 的源端,如果每块都要维护独立流, 对业务库侵入性和延迟都显著增加 。 补充:
. LogMiner 工作原理
~500MB-1GB 内存: 用于缓存和解析 持续读取 Redo Log 文件: (I/O 操作) 不开启 exactly_once(语义是 At-Least-Once) 回填和增量在 同一条流 里串起来,可以认为“回填 + 增量是一体的”。
2. 不开 exactly_once 会不会重复读? 会,有条件:
3. 如何在不开 exactly_once 时尽量避免重复写 方案:Sink 端开启 upsert (主键幂等) JDBC Sink 打开 enable_upsert → 用 MERGE INTO / REPLACE INTO 之类的语句。 同一主键重复来多次,只是覆盖更新,下游表里最终是 1 条。 语义上:传输是 At-Least-Once,下游结果接近逻辑上的 Exactly-Once。 快照也走 upsert,性能明显慢于纯 INSERT。 如果再强行用 exactly_once + 内存过滤: 切分块很多时,需要在内存里记住大量 offset / 主键,内存压力很大。 对 Oracle 这类基于 LogMiner 的源端: 每个块单独起 LogMiner / 流式会话 → 对业务库侵入性大,延迟也会高。 4. 实战建议 CDC的startup.mode的timestamp模式底层
是怎样实现的?
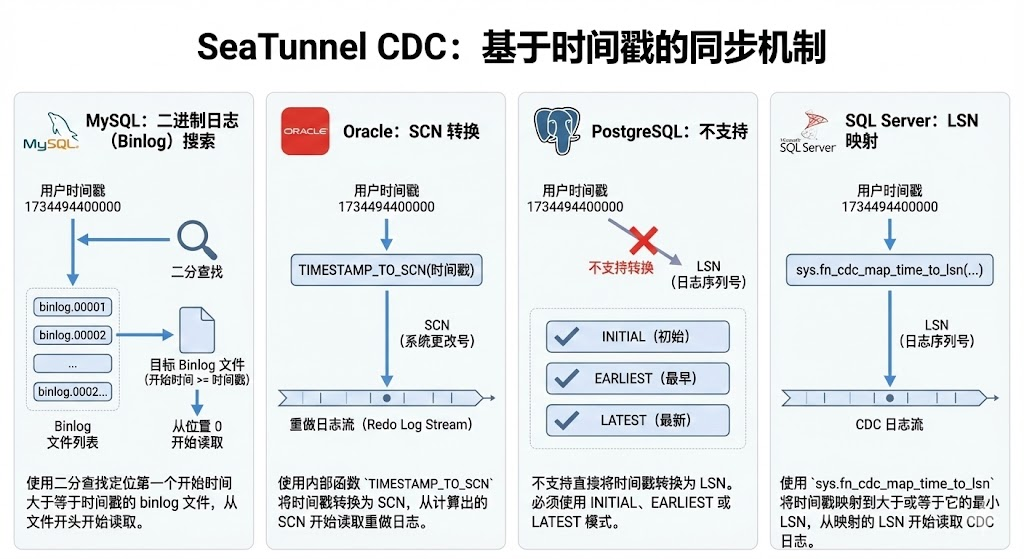
timestamp顾名思义就是指定时间去同步数据,那么每个数据数据库他们的cdc原理不同,指定时间的方式也就不同。
1. MySQL - 二分查找 Binlog 文件 MySQL 的原理:
用户指定毫秒级时间戳(如 1734494400000 ) SeaTunnel 执行 SHOW BINARY LOGS 获取所有 binlog 文件列表 使用 二分查找 遍历 binlog 文件,获取每个文件的第一条记录的时间戳 找到第一个时间戳 >= 指定时间的 binlog 文件 返回该文件名和位置 0,从该位置开始读取 binlog 2. Oracle - TIMESTAMP_TO_SCN 函数 Oracle 的原理:
用户指定毫秒级时间戳(如 1763058616003 ) SeaTunnel 将毫秒转换为 java.sql.Timestamp ,格式化为 YYYY-MM-DD HH24:MI:SS.FF3 执行 SQL: SELECT TIMESTAMP_TO_SCN(TO_TIMESTAMP('2024-12-18 09:00:00.003', 'YYYY-MM-DD HH24:MI:SS.FF3')) FROM DUAL Oracle 数据库内置函数 TIMESTAMP_TO_SCN 直接返回对应的 SCN(System Change Number) 返回 RedoLogOffset 包含该 SCN,从该 SCN 开始读取 redo log 也可以将scn查查出来 转为timestamp: SELECT current_scn FROM v$database; and SELECT SCN_TO_TIMESTAMP('240158979') FROM DUAL; 补充一点,Oracle由于直接读取redolog,所以排查问题很困难,下面这几个sql执行能够简单的模拟debezium启动logminer进程的代码,可以方便定位问题:
BEGIN DBMS_LOGMNR.END_LOGMNR; EXCEPTION WHEN OTHERS THEN NULL ; END ;SELECT * FROM V$LOGFILE ;DECLARE v_first BOOLEAN := TRUE ; BEGIN FOR rec IN (SELECT MEMBER FROM V$LOGFILE WHERE TYPE= 'ONLINE' AND ROWNUM <= 3 ) LOOP IF v_first THEN DBMS_LOGMNR.ADD_LOGFILE(rec.MEMBER, DBMS_LOGMNR.NEW); DBMS_OUTPUT.PUT_LINE('Added log file: ' || rec.MEMBER); v_first := FALSE ; ELSE DBMS_LOGMNR.ADD_LOGFILE(rec.MEMBER, DBMS_LOGMNR.ADDFILE); DBMS_OUTPUT.PUT_LINE('Added log file: ' || rec.MEMBER); END IF; END LOOP; END ;BEGIN DBMS_LOGMNR.START_LOGMNR( OPTIONS => DBMS_LOGMNR.DICT_FROM_ONLINE_CATALOG + DBMS_LOGMNR.COMMITTED_DATA_ONLY ); DBMS_OUTPUT.PUT_LINE('LogMiner started successfully' ); END ;SELECT SCN, OPERATION, OPERATION_CODE, TABLE_NAME, TO_CHAR(TIMESTAMP , 'YYYY-MM-DD HH24:MI:SS' ) AS TIMESTAMP , CSF, INFO, SUBSTR(SQL_REDO, 1 , 200 ) AS SQL_REDO_PREVIEW FROM V$LOGMNR_CONTENTSWHERE TABLE_NAME = 'XML_DEBUG_TEST' AND SEG_OWNER = USER ORDER BY SCN, SEQUENCE#;BEGIN DBMS_LOGMNR.END_LOGMNR; EXCEPTION WHEN OTHERS THEN NULL ; END ;3. PostgreSQL - 不支持 Timestamp PostgreSQL 的原理:
不支持 PostgreSQL 使用 LSN(Log Sequence Number)作为偏移量 LSN 是一个 64 位的数字,表示 WAL(Write-Ahead Log)中的位置 用户只能使用 INITIAL 、 EARLIEST 、 LATEST 模式 4. SQL Server - sys.fn_cdc_map_time_to_lsn 函数 SQL Server 的原理:
用户指定毫秒级时间戳(如 1734494400000 ) SeaTunnel 将毫秒转换为 java.sql.Timestamp 执行 SQL: SELECT sys.fn_cdc_map_time_to_lsn('smallest greater than or equal', ?) AS lsn SQL Server 内置函数 sys.fn_cdc_map_time_to_lsn 返回 >= 指定时间的最小 LSN 返回 LsnOffset 包含该 LSN 的字节数组,从该 LSN 开始读取 CDC 日志 SeaTunnel的Checkpoint机制
与CDC任务是如何联动的?
大家都知道Checkpoint可以实现断点续传,那么到底是怎么实现的呢,有什么注意事项呢?
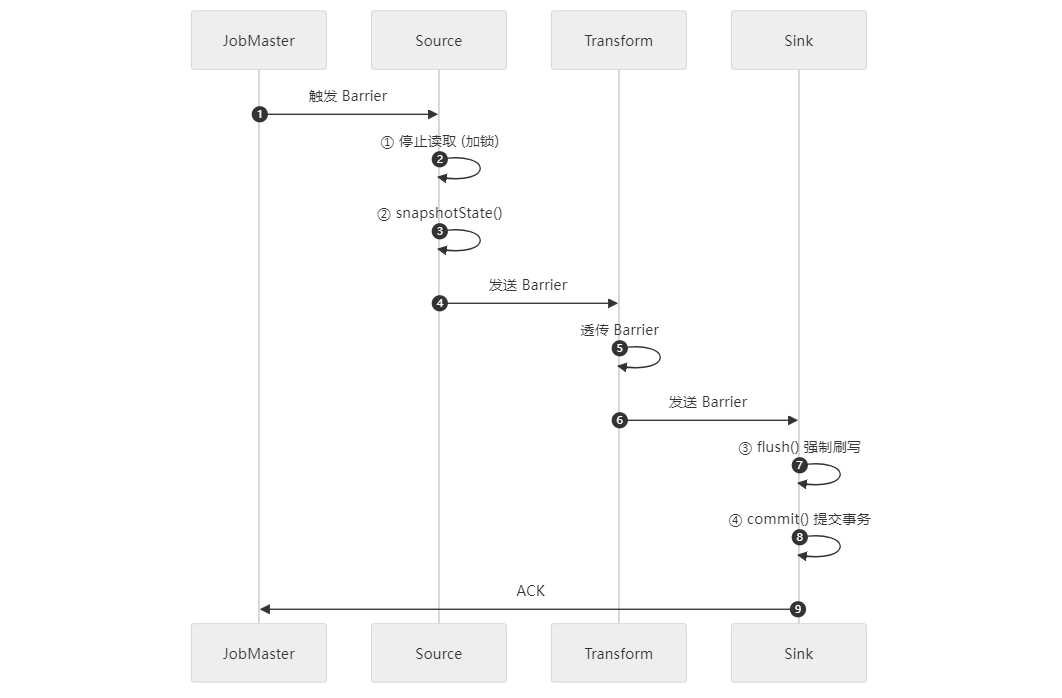
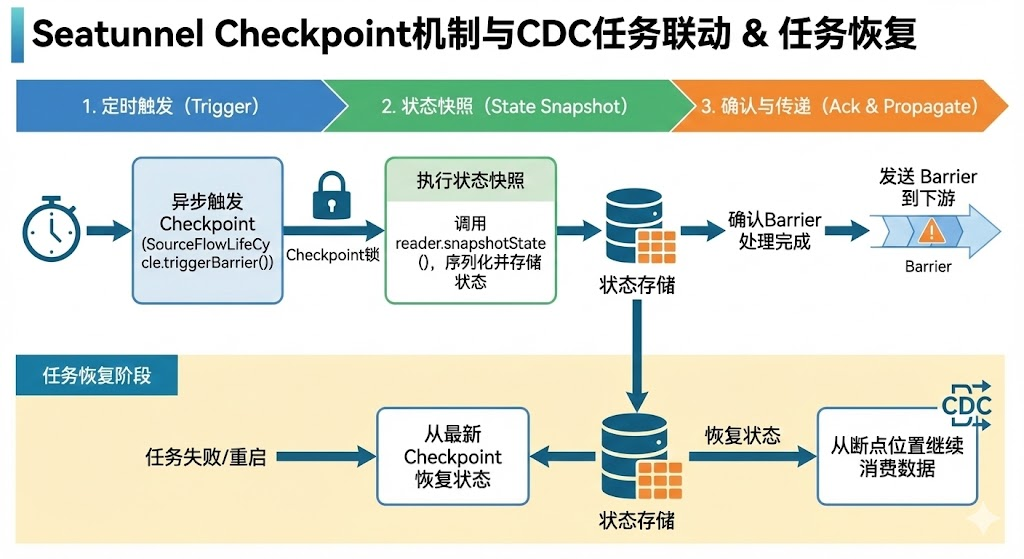
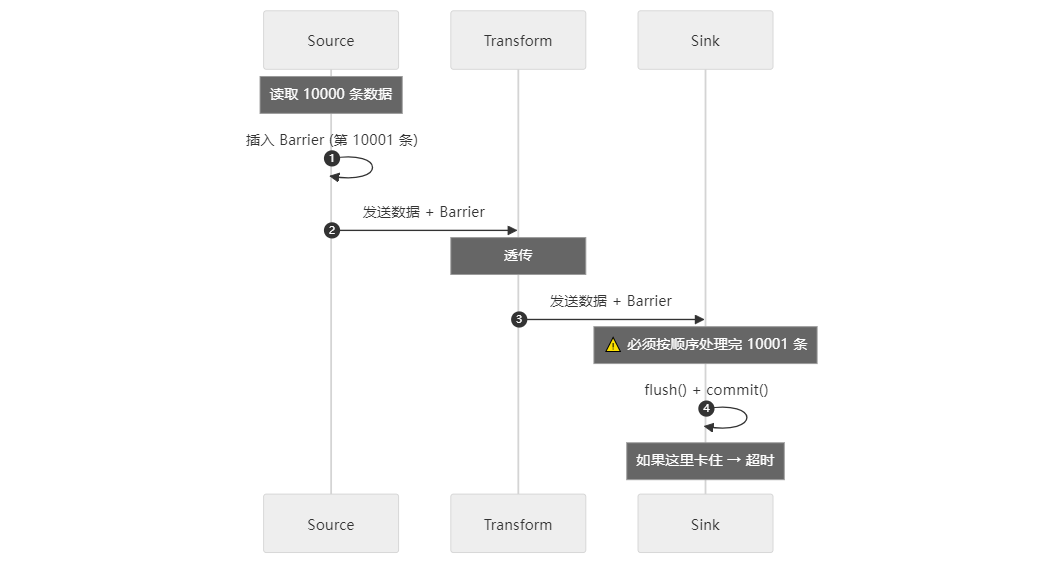
首先,我们先简单了解一下ck的实现原理:SeaTunnel会每隔一定时间会异步触发一个ck: SourceFlowLifeCycle.triggerBarrier()
public void triggerBarrier (Barrier barrier) throws Exception { log.debug ("source trigger barrier [{}]" , barrier); synchronized (collector.getCheckpointLock ()) { if (barrier.prepareClose (this .currentTaskLocation)) { this .prepareClose = true ; } if (barrier.snapshot ()) { List<byte[]> states = serializeStates (splitSerializer, reader.snapshotState (barrier.getId ())); runningTask.addState (barrier, ActionStateKey.of (sourceAction), states); } runningTask.ack (barrier); collector.sendRecordToNext (new Record<>(barrier)); } } 从代码可以看到,实际ck就是会模拟一个barrier屏障数据,这个是一个标记的特殊数据,会被塞进迭代器,随着数据流转发送source->transform->sink 各个任务通道里。每到一个层级就会到Barrier数据做判断,source端会停止读数,记录当时读取的信息状态存储到ck里,transform暂不处理,当sink端接收到Barrier数据后 ,会强制flush当前缓存的批数据,
当我们对ck机制有个初步了解后,就会有很多问题,比如cdc在全量阶段,我进行ck的时候 ,source端触发保存的是什么数据呢?为什么它能断点续传?有什么不好的地方?而增量阶段又是怎样的的呢?
不同阶段保存的状态 快照阶段 保存内容
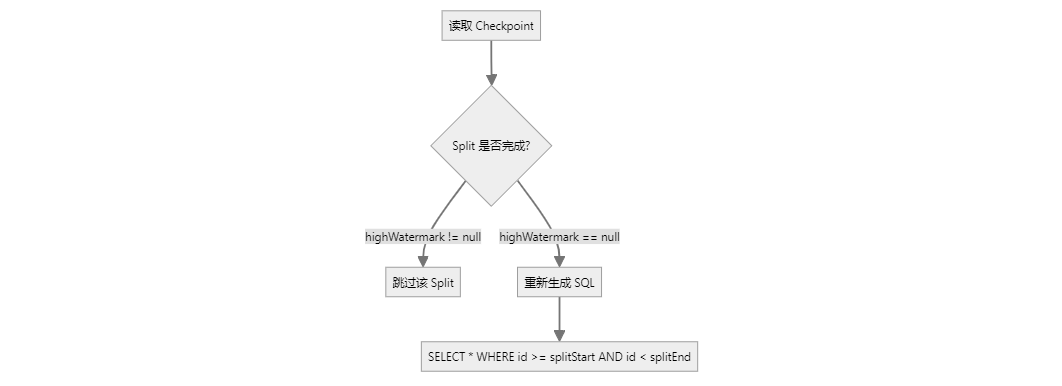
public class SnapshotSplit { private final Object[] splitStart; private final Object[] splitEnd; private final Offset lowWatermark; private final Offset highWatermark; } 恢复逻辑
关键源码
// IncrementalSourceReader.addSplits() for (SourceSplitBase split : splits) { if (split .isSnapshotSplit()) { SnapshotSplit snapshotSplit = split .asSnapshotSplit(); if (snapshotSplit.isSnapshotReadFinished()) { finishedUnackedSplits.put(splitId, snapshotSplit); // 已完成,跳过 } else { unfinishedSplits.add(split ); // 未完成,重新读取 } } } 增量阶段 保存内容
public class IncrementalSplit { private final Offset startupOffset; private final List <CompletedSnapshotSplitInfo > completedSnapshotSplitInfos; private final Map <TableId , byte[]> historyTableChanges; } 恢复逻辑
if (split.isIncrementalSplit()) { IncrementalSplit incrementalSplit = split.asIncrementalSplit(); debeziumDeserializationSchema.restoreCheckpointProducedType( incrementalSplit.getCheckpointTables() ); return new IncrementalSplitState (incrementalSplit); } Checkpoint 状态对比 快照 有(需 Sink 幂等,且再次运行Select查询因为不在同一时刻会导致查询不对等) 增量
所以,经过对比分析,建议大家 尽量避免在全量和回填阶段阶段去恢复和暂停任务,会有很多未知问题!
很多小伙伴在任务运行难免会发现一个问题, ck超时 ,甚至10分钟、20分钟都还是超时,这是为什么?
结合之前对ck和cdc任务的理解,我们可以分析出来,长时间的Checkpoint (CK) 超时通常是由于目的端 (Sink) 写入性能不足或配置不当导致的。源端 (Source) 触发 CK 仅需保存少量元数据,速度极快;但目的端必须在超时前处理完所有待写入数据,才能通过 CK Barrier,因此写入效率是关键。
Checkpoint 超时机制分析 CheckPoint 机制旨在确保数据同步的 精确一次 (Exactly-Once) 语义,它的核心在于 CK Barrier(检查点屏障) 必须从源端流到目的端,且所有算子都完成状态保存。
源端速度: 源端仅需记录当前读取的位置信息和元数据(如 SeaTunnel 的 Split 和 Offset,但是对于Flink这种计算引擎可能会很大),这通常是毫秒级的操作,因此源端触发 CK 很快 。 目的端阻塞: 当 CK Barrier 到达目的端时,目的端必须完成所有在 Barrier 之前接收到的待写入数据(如 10,000 条记录)的写入操作。 超时发生: 如果目的端写入速度慢,数据积压,导致 Barrier 无法在规定的超时时间(例如 10-20 分钟)内通过,就会触发 CK Timeout。 结论 : 长时间超时几乎总是意味着目的端在指定时间内无法处理完积压的数据。
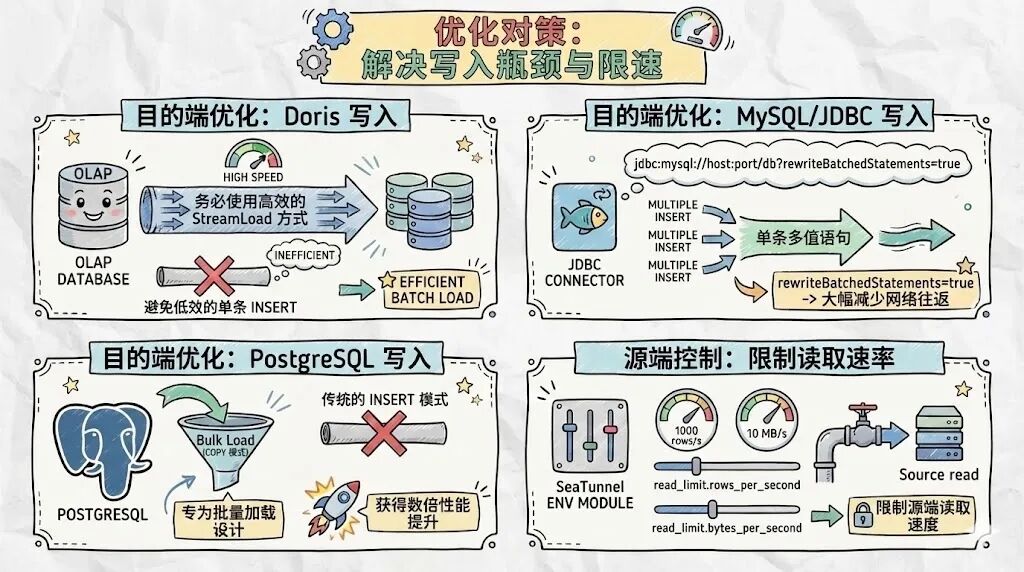
解决方案 1. Sink 端优化(最常见) MySQL
jdbc:mysql://host:port/db?rewriteBatchedStatements=true &cachePrepStmts=true Doris/StarRocks
sink { Doris { sink.enable-2pc = true sink.buffer-size = 1048576 sink.buffer-count = 3 } } PostgreSQL
sink { Jdbc { use_copy_statement = true } } 2. Source 端限流 env { job.mode = STREAMING read_limit.rows_per_second = 4000 read_limit.bytes_per_second = 7000000 checkpoint.interval = 30000 checkpoint.timeout = 600000 } CDC 技术确实复杂,涉及分布式系统的方方面面:并行度控制、状态管理、容错恢复、精确一次语义、对数据库的理解等。SeaTunnel在Debezium的基础上做了大量工程优化,修复了若干BUG, 而且SeaTunnel的架构设计对新手来说非常友好,不论是修补文档还是直接上手修改BUG,都比较轻松,所以非常欢迎大家加入贡献者队伍里~
希望本文能帮助大家更好地理解SeaTunnel CDC的内部机制,在生产环境中少踩坑、多调优。如果有任何疑问或发现错误,欢迎交流指正!
最后,祝大家的CDC任务都能稳定运行不中断,Checkpoint不再超时!
Apache SeaTunnel Apache SeaTunnel是一个云原生的多模态、高性能海量数据集成工具。北京时间 2023 年 6 月1 日,全球最大的开源软件基金会ApacheSoftware Foundation正式宣布Apache SeaTunnel毕业成为Apache顶级项目。目前,SeaTunnel在GitHub上Star数量已达8k+,社区达到6000+人规模。SeaTunnel支持在云数据库、本地数据源、SaaS、大模型等170多种数据源之间进行数据实时和批量同步,支持CDC、DDL变更、整库同步等功能,更是可以和大模型打通,让大模型链接企业内部的数据。
https://github.com/apache/seatunnel https://seatunnel.apache.org/ https://seatunnel.apache.org/download 我们相信,在 「 Community Over Code 」 (社区大于代码)、 「Open and Cooperation」 (开放协作)、 「Meritocracy」 (精英管理)、以及「 多样性与共识决策」 等 The Apache Way 的指引下,我们将迎来更加多元化和包容的社区生态,共建开源精神带来的技术进步! 我们诚邀各位有志于让本土开源立足全球的伙伴加入 SeaTunnel 贡献者大家庭,一起共建开源! https://github.com/apache/seatunnel/issues https://github.com/apache/seatunnel/pulls dev-subscribe@seatunnel.apache.org https://join.slack.com/t/apacheseatunnel/shared_invite/zt-1kcxzyrxz-lKcF3BAyzHEmpcc4OSaCjQ https://x.com/ASFSeaTunnel