用一句话总结二者的关系:Debezium 是 SeaTunnel CDC 的底层核心引擎,而 SeaTunnel CDC 是对 Debezium 功能的封装、增强与生态扩展。
以下是详细的关系解读:
“Debezium 可以说是 CDC 的鼻祖”。在 SeaTunnel CDC 的体系中,Debezium 扮演着不可替代的“基石”角色。
- 核心能力提供者:Debezium 提供了最核心的 CDC 能力,即监听源数据库(如 MySQL Binlog, PostgreSQL WAL 等)的行级变更,并将这些变更标准化为事件流。
- 成熟的连接器库:SeaTunnel 复用了 Debezium 社区长期积累的、成熟的多种数据库连接器库,保证了对各类主流数据库的稳定支持。
- 标准化数据格式:Debezium 定义了清晰的数据结构(
SourceRecord),包含变更前(before)、变更后(after)、操作类型(Envelope Operation: CREATE/READ/UPDATE/DELETE)等信息,为上层处理提供了标准输入。
2. 关键转折点:弃用 Kafka Connect,转向嵌入式引擎
这是理解两者关系最关键的一点。
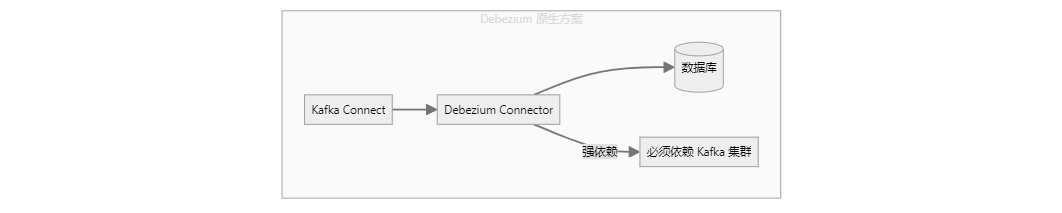
- 传统 Debezium:通常依赖 Apache Kafka Connect 部署,数据必须流入 Kafka 集群。这虽然提供了高可靠性,但也带来了沉重的基础设施依赖。
- SeaTunnel 的选择:为了实现更轻量级、更灵活的集成,SeaTunnel 并没有使用 Debezium 的 Kafka Connect 模式。相反,它利用了 Debezium 提供的嵌入式引擎 (debezium-embedded)模式。
- 集成的本质:SeaTunnel 通过引入 Maven 依赖(
debezium-api 和debezium-embedded),将 Debezium 引擎作为一个类库直接嵌入到 SeaTunnel 的进程中运行。这彻底抛离了对 Kafka 集群的强制依赖。
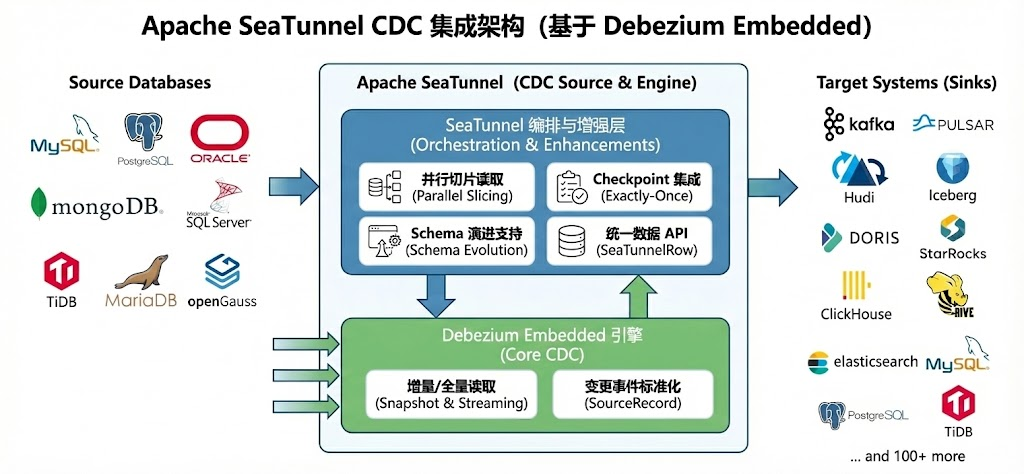
3. 编排与封装:SeaTunnel CDC 的架构
SeaTunnel 在 Debezium 引擎之上构建了一层复杂的“编排层”,负责管理和调度 Debezium 的工作。
如下面的架构图所示,SeaTunnel 位于上层,负责读取逻辑、反序列化、流式抓取和连接管理;而 Debezium 位于下层,负责驱动底层的数据库 CDC 机制并生成标准数据记录。
代码段
SeaTunnel 对 Debezium 的核心功能利用情况如下表:
| 功能 | Debezium 提供 (核心能力) | SeaTunnel 使用 (封装调用) |
|---|
| 全量读取 | | SnapshotChangeEventSource |
| 增量读取 | | StreamingChangeEventSource 读取 Binlog/WAL 等 |
| 数据结构 | | |
| 操作类型 | | 识别增删改 (CREATE/UPDATE/DELETE) |
| 状态管理 | | |
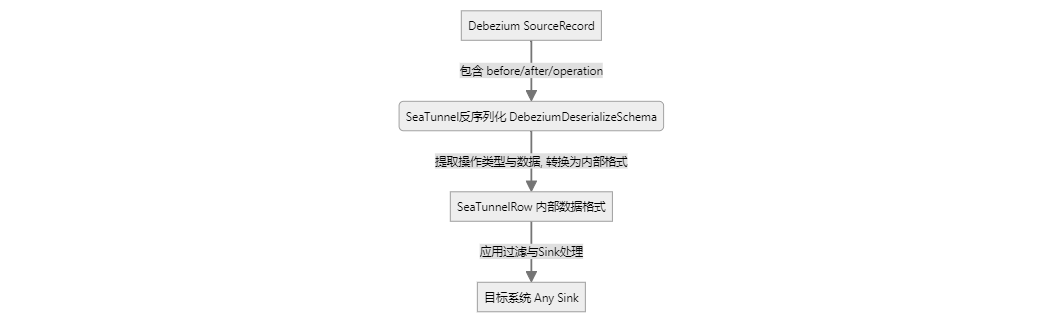
两者在数据处理链路上是串联关系。Debezium 负责生产“原材料”,SeaTunnel 负责将其“加工”成内部标准格式。
- Debezium 产出:生成包含原始变更信息的
SourceRecord。 - SeaTunnel 翻译:通过
DebeziumDeserializeSchema 将SourceRecord 反序列化,提取关键信息,并转换为 SeaTunnel 内部统一的行数据格式SeaTunnelRow,同时标记好行类型(RowKind,如 INSERT/UPDATE_AFTER 等)。
![]()
![]()
![]()
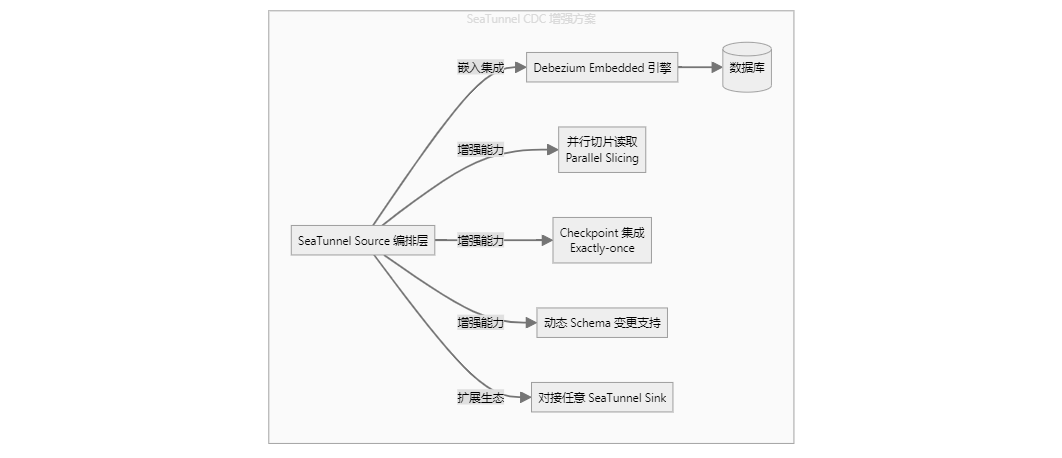
通过将 Debezium 嵌入并加以封装,SeaTunnel CDC 相比原生的 Debezium 方案实现了显著的功能增强,如下图所示:
总结 SeaTunnel 带来的关键增强:
- 解耦 Kafka:这是最大的区别。SeaTunnel CDC 可以直接将数据写入任意支持的 Sink 端(如数据湖、数仓等),而无需中间经过 Kafka。
- 并行读取能力:SeaTunnel 引入了并行切片算法,能够并发地读取全量历史数据,大幅提升效率。
- 引擎原生集成:与 SeaTunnel(以及 Flink/Spark)的 Checkpoint 机制深度集成,确保了数据处理的 Exactly-once(精确一次)语义。
- Schema 演进支持:更好地处理源端的 DDL 变更,适应表结构的变化。
Apache SeaTunnel
Apache SeaTunnel是一个云原生的多模态、高性能海量数据集成工具。北京时间 2023 年 6 月1 日,全球最大的开源软件基金会ApacheSoftware Foundation正式宣布Apache SeaTunnel毕业成为Apache顶级项目。目前,SeaTunnel在GitHub上Star数量已达8k+,社区达到6000+人规模。SeaTunnel支持在云数据库、本地数据源、SaaS、大模型等170多种数据源之间进行数据实时和批量同步,支持CDC、DDL变更、整库同步等功能,更是可以和大模型打通,让大模型链接企业内部的数据。
https://github.com/apache/seatunnelhttps://seatunnel.apache.org/https://seatunnel.apache.org/download我们相信,在「Community Over Code」(社区大于代码)、「Open and Cooperation」(开放协作)、「Meritocracy」(精英管理)、以及「多样性与共识决策」等 The Apache Way 的指引下,我们将迎来更加多元化和包容的社区生态,共建开源精神带来的技术进步!我们诚邀各位有志于让本土开源立足全球的伙伴加入 SeaTunnel 贡献者大家庭,一起共建开源!https://github.com/apache/seatunnel/issueshttps://github.com/apache/seatunnel/pullsdev-subscribe@seatunnel.apache.orghttps://join.slack.com/t/apacheseatunnel/shared_invite/zt-1kcxzyrxz-lKcF3BAyzHEmpcc4OSaCjQhttps://x.com/ASFSeaTunnel