作者 | 肖清海
旧环境情况
当前 DolphinScheduler 版本: 3.1.3
当前 版本: 2.1.3
部署规模: 1台Master + 2台Worker,工作流定义3700+,日均调度任务量20000+
使用年限: 已经稳定运行3年
升级驱动因素
功能需求:因业务需求增大,当前版本的架构设计缺陷、元数据库处理限制以及服务器资源不足;
社区支持:官方推荐使用最新稳定版本,获得更好的技术支持
性能优化:3.4.1版本在调度性能和稳定性方面有显著提升
为什么不用官方升级方案
版本跨度太大:3.1.3 → 3.2.0 → 3.3.0 → 3.4.1,需要多次中间升级
生产环境限制:无法接受多次停机窗口,业务连续性要求高
架构变更风险:资源中心重构、元数据库表结构变更等存在较高迁移风险
工作量考量:任务数量多,手动重建工作流工作量巨大,需要自动化方案
二、整体迁移思路:绕开官方
升级路径,采用「重建+API」方案
2.1 核心思想
不追求「逐步升级」,而是「换新环境+数据迁移」:
- 编写脚本代码通过旧版本API读取工作流定义和任务配置
2.2 方案优势与风险对比
| | |
|---|
| | |
| | |
| | 只迁移核心业务数据(工作流定义),历史执行记录不迁移 |
| | |
| | |
| | |
3.1 环境准备阶段
3.1.1 新环境部署
- 配置数据库、Registry等依赖,弃用zk注册中心,改用Jdbc
- 集成seatunnel 2.1.3,启动方式从引擎:从spark改成start-seatunnel-spark.sh;
- 默认参数配。如租户、工作组、环境等,在项目管理设置里面配置偏好;
- 参数传递变化。新版必须在下游节点添加“IN”类型的参数,才可以接收上游变量值
- 验证新环境基本功能正常,另外选取代表性任务手动创建执行验证
3.1.2 API访问配置
- 在新环境中配置API访问权限:令牌管理创建新的令牌
3.2 元数据库基础数据配置
3.3.1 前期准备测试
- 先对自己的任务分类:模板化的任务,非模板化的任务;
- 选取代表性的任务,在新版本上创建运行,保证任务的正常运行,同步后的表的数据正常。
3.3.2 代码开发-读取原任务定义
... //获取整个, 循环处理 String processDefinitionUrl = OLD_URL + "/dolphinscheduler/projects/" + oldProjectCode + "/process-definition/query-process-definition-list"; Map<String, String> map = new HashMap<>(); map.put("projectCode", oldProjectCode); String pdRes = httpClientUtilOld.doGetRequest(processDefinitionUrl, map); ArrayList<JSONObject> dataList = parseResDataToList(pdRes); for (JSONObject job : dataList) { String oldWFCode = job.get("code").toString(); Map<String, String> mapPara = new HashMap<>(); String oldurl = OLD_URL + "/dolphinscheduler/projects/" + oldProjectCode + "/process-definition/" + oldWFCode; mapPara.put("code", oldWFCode); mapPara.put("projectCode", oldProjectCode); String res = httpClientUtilOld.doGetRequest(oldurl, mapPara); JSONObject jsonObject = JSON.parseObject(res); JSONObject data = (JSONObject) jsonObject.get("data"); JSONObject processDefinition = data.getJSONObject("processDefinition"); JSONArray processTaskRelationList = data.getJSONArray("processTaskRelationList"); JSONArray taskDefinitionList = data.getJSONArray("taskDefinitionList"); //todo 获取 n个编码,替换旧任务编码 //填充 信息创建任务 createWF(processDefinition, processTaskRelationList, taskDefinitionList, NEW_IP, newProjectCode);3.3.3 API创建新工作流
//看原工作流的任务有几个 获取任务编码 int taskCnt = taskDefinitionList.size(); List<String> taskCodeList = taskDefinitionList.stream() .map(obj -> (JSONObject) obj) .map(obj -> obj.getString("code")) .collect(Collectors.toList()); try {// todo 获取 任务编码 String taskCodeUrl = NEW_URL + "/dolphinscheduler/projects/" + newProjectCode + "/task-definition/gen-task-codes"; HashMap<String, String> taskCodeMap = new HashMap<>(); //需要创建n个任务 taskCodeMap.put("genNum", String.valueOf(taskCnt)); String codeData = httpClientUtilNew.doGetRequest(taskCodeUrl, taskCodeMap); Object codes = JSON.parseObject(codeData).get("data"); JSONArray taskCodeArr = JSON.parseArray(codes.toString());//根据实际任务 添加任务下游接收参数 for (int i = 0; i < taskDefinitionList.size(); i++) { JSONObject logTask = (JSONObject) taskDefinitionList.get(i); if (“判断逻辑”)) { JSONObject taskParams = logTask.getJSONObject("taskParams"); JSONArray localParams = taskParams.getJSONArray("localParams"); // 构造 hiveAmount JSONObject hiveParam = new JSONObject(); hiveParam.put("prop", "hiveAmount"); hiveParam.put("direct", "IN"); hiveParam.put("type", "VARCHAR"); hiveParam.put("value", ""); localParams.add(hiveParam); logTask.put("taskParamList", localParams); JSONObject paramMap = new JSONObject(); for (Object obj : localParams) { JSONObject param = (JSONObject) obj; paramMap.put(param.getString("prop"), param.getString("value")); } logTask.put("taskParamMap", paramMap); ....// 替换必要参数 code 和seatunnel执行引擎参数 for (int i = 0; i < taskCodeList.size(); i++) { String oldCode = taskCodeList.get(i); String newCode = taskCodeArr.getString(i); //替换编码 // 替换sea引擎:"SPARK" "start-seatunnel-spark.sh" taskDefinitionListJsonStr = taskDefinitionListJsonStr .replace("\"code\":" + oldCode + ",", "\"code\":" + newCode + ",") .replace("\"engine\":\"SPARK\",", "\"startupScript\":\"start-seatunnel-spark.sh\","); taskRelationListJsonStr = taskRelationListJsonStr .replace("TaskCode\":" + oldCode + ",", "TaskCode\":" + newCode + ","); locationsJsonStr = locationsJsonStr .replace(oldCode, newCode);... } Map<String, String> map = new HashMap<>(); map.put("taskDefinitionJson", taskDefinitionListJsonStr); map.put("taskRelationJson", taskRelationListJsonStr); map.put("locations", locationsJsonStr); map.put("name", processDefinition.getString("name")); map.put("tenantCode", "omm");//processDefinition.getString("tenantCode") map.put("executionType", processDefinition.getString("executionType")); map.put("description", processDefinition.getString("description") == null ? "" : processDefinition.getString("description")); map.put("globalParams", processDefinition.getString("globalParams")); map.put("timeout", processDefinition.getString("timeout")); String processDefinitionUrl = NEW_URL + "/dolphinscheduler/projects/" + newProjectCode + "/workflow-definition"; String processDefinitionRes = httpClientUtilNew.doPostRequest(processDefinitionUrl, map);3.4 迁移执行阶段
3.4.1 流程
备份旧版本调度表:t_ds_schedules_20260416_10
选择试点项目:选择一个任务量适中、业务影响小的项目作为试点
迁移任务定义:迁移200个任务定义(包括定时配置)
上线任务不上线定时:先上线任务定义,但不启用定时调度
手动提交验证:分批手动提交运行,注意和原集群的任务是否冲突(因为大部分是天/时/15分钟定时,一般不冲突)
核查处理失败任务:分析失败原因,修复问题后重新运行
上线定时配置:所有任务验证无误后,上线这些任务的定时
下线原集群定时:确认新环境稳定运行后,下线原集群对应任务的定时
分项目、分批次迁移
3.4.2 迁移实施
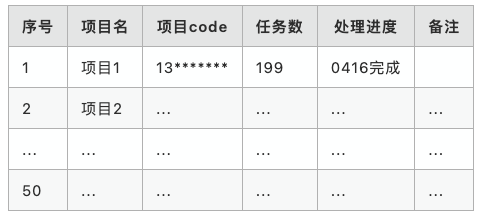
按照流程,先找个任务少并且有代表性的项目(199个任务),迁移后试运行一段时间,测试稳定性运行一周没有问题。后续迁移完成50个项目,总共约3700个任务,耗时10天左右
3.4.3 运行情况
目前已经运行了近1个月时间。以前调度延迟的问题:几乎是10秒到1分钟甚至更严重,现在几乎没有调度延迟;调度缺失实例的问题,目前也未发生。
目前一切运行良好,暂未发现问题,后续持续观察。
4.1 主要风险点
数据丢失风险:迁移过程中可能遗漏部分配置
兼容性问题:旧版本特有配置在新版本不支持
业务中断风险:切换期间可能出现调度延迟
4.2 应急预案
4.2.1 回滚方案
4.2.2 数据备份
5.1 项目成果
5.2 经验教训
5.3 后续规划
- 目前是升级的ds版本,解决当前的调度瓶颈,因需适应项目spark集群的升级,下一步要测试实施seatunnel从2.1.3升级到 2.3.12版本,大概率也是沿用这套方案。
- GitHub: https://github.com/apache/dolphinscheduler
- 官网:https://dolphinscheduler.apache.org/en-us
- 订阅开发者邮件:dev@dolphinscheduler@apache.org(向邮箱发送任意内容,收到邮件后回复同意订阅即可)
- YouTube:https://www.youtube.com/@apachedolphinscheduler
- Slack:https://join.slack.com/t/asf-dolphinscheduler/shared_invite/zt-1cmrxsio1-nJHxRJa44jfkrNL_Nsy9Qg
同样地,参与Apache DolphinScheduler 有非常多的参与贡献的方式,主要分为代码方式和非代码方式两种。
非代码方式包括:
完善文档、翻译文档;翻译技术性、实践性文章;投稿实践性、原理性文章;成为布道师;社区管理、答疑;会议分享;测试反馈;用户反馈等。
代码方式包括:
查找Bug;编写修复代码;开发新功能;提交代码贡献;参与代码审查等。
贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/pulls?q=is%3Apr+is%3Aopen+label%3A%22first+time+contributor%22优先级问题列表:https://github.com/apache/dolphinscheduler/pulls?q=is%3Apr+is%3Aopen+label%3Apriority%3Ahigh如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/docs/3.2.2/%E8%B4%A1%E7%8C%AE%E6%8C%87%E5%8D%97_menu/%E5%A6%82%E4%BD%95%E5%8F%82%E4%B8%8E_menuhttps://github.com/apache/dolphinscheduler