测试目的
数仓的数据源是Kafka,因此离线数仓需要用Flume采集Kafka中的数据到HDFS中!
在实际项目中,不可能一直在Xshell中启动Flume任务,一是项目的Flume任务很多,二是一旦Xshell页面关闭,Flume任务就会停止,这样非常不方便,因此必须在后台启动Flume任务。
所以经过测试后,发现海豚调度器也可以启动Flume任务!

解决方案
Flume在Linux中的路径
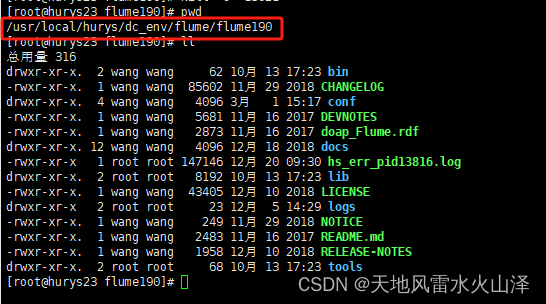
Flume任务文件在Linux中的位置以及任务文件名
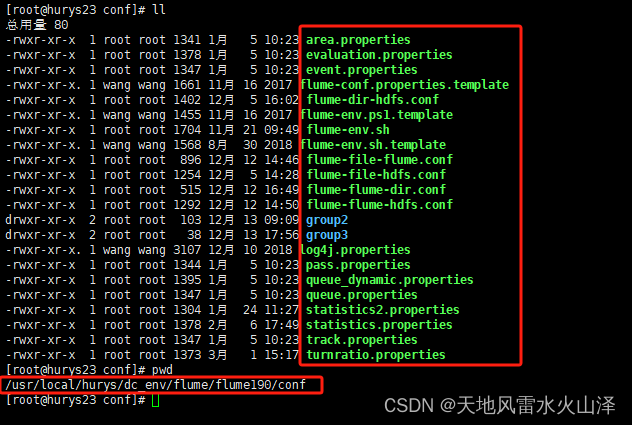
在海豚中配置运行脚本
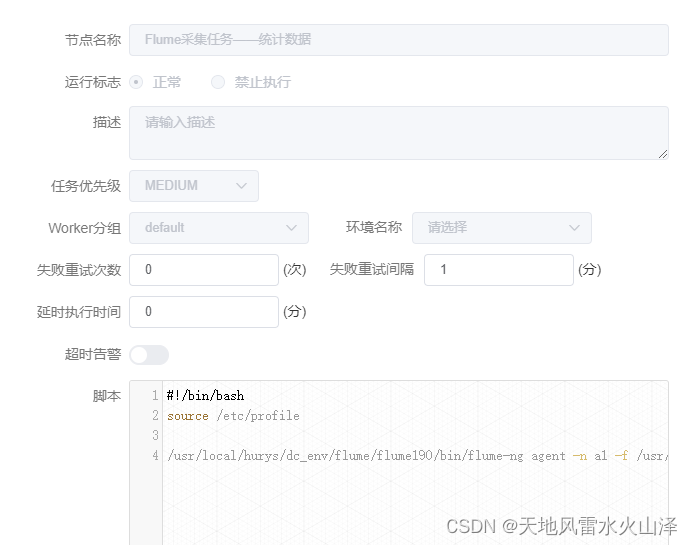
#!/bin/bashsource /etc/profile/usr/local/hurys/dc_env/flume/flume190/bin/flume-ng agent -n a1 -f /usr/local/hurys/dc_env/flume/flume190/conf/statistics.properties
注意:/usr/local/hurys/dc_env/flume/flume190/为Flume在Linux中的安装,根据自己安装路径进行调整
海豚任务配置好后就可以启动海豚任务

在HDFS对应文件夹中验证是否采集到数据
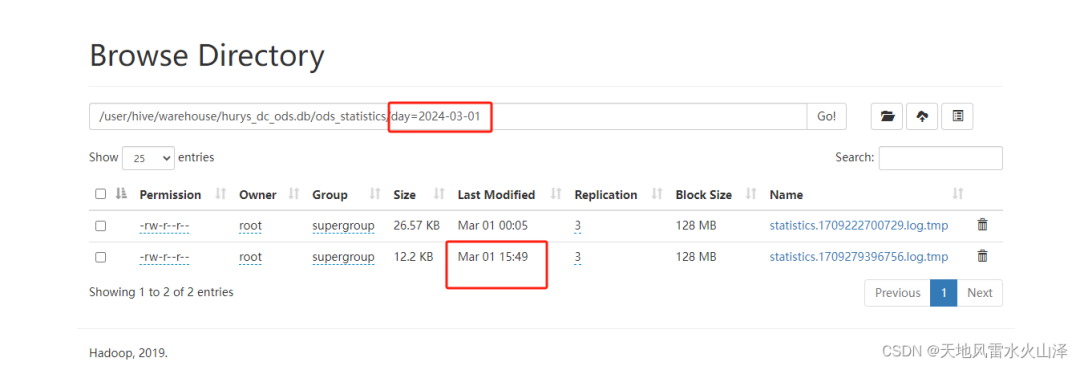
Flume采集Kafka数据成功写入到HDFS中,成功实现用海豚执行Flume任务的目的!
原文链接:https://blog.csdn.net/tiantang2renjian/article/details/136399112
- GitHub: https://github.com/apache/dolphinscheduler
- 官网:https://dolphinscheduler.apache.org/en-us
- 订阅开发者邮件:dev@dolphinscheduler@apache.org(向邮箱发送任意内容,收到邮件后回复同意订阅即可)
- YouTube:https://www.youtube.com/@apachedolphinscheduler
- Slack:https://join.slack.com/t/asf-dolphinscheduler/shared_invite/zt-1cmrxsio1-nJHxRJa44jfkrNL_Nsy9Qg
同样地,参与Apache DolphinScheduler 有非常多的参与贡献的方式,主要分为代码方式和非代码方式两种。
非代码方式包括:
完善文档、翻译文档;翻译技术性、实践性文章;投稿实践性、原理性文章;成为布道师;社区管理、答疑;会议分享;测试反馈;用户反馈等。
代码方式包括:
查找Bug;编写修复代码;开发新功能;提交代码贡献;参与代码审查等。
贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/pulls?q=is%3Apr+is%3Aopen+label%3A%22first+time+contributor%22优先级问题列表:https://github.com/apache/dolphinscheduler/pulls?q=is%3Apr+is%3Aopen+label%3Apriority%3Ahigh如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/docs/3.2.2/%E8%B4%A1%E7%8C%AE%E6%8C%87%E5%8D%97_menu/%E5%A6%82%E4%BD%95%E5%8F%82%E4%B8%8E_menuhttps://github.com/apache/dolphinscheduler