作者 | 张鑫
每个数据工程师都经历过这样的场景:
业务方说"帮我把 MySQL 的用户表同步到 S3"——你心里知道这件事本质上就是从 A 搬到 B。但接下来你要查文档、学参数、写 HOCON、调试报错,一个"简单"的需求花了两小时。
SeaTunnel 拥有 100+ connectors,覆盖了几乎所有主流数据源。但每个 connector 有 20-50 个配置参数,这些参数有必填/可选/条件依赖/枚举约束等复杂规则。这个参数空间的复杂度,恰恰是用户上手最大的门槛。
我们想解决的问题很直接:能不能用一句话就生成一个可以直接运行的 Pipeline 配置?
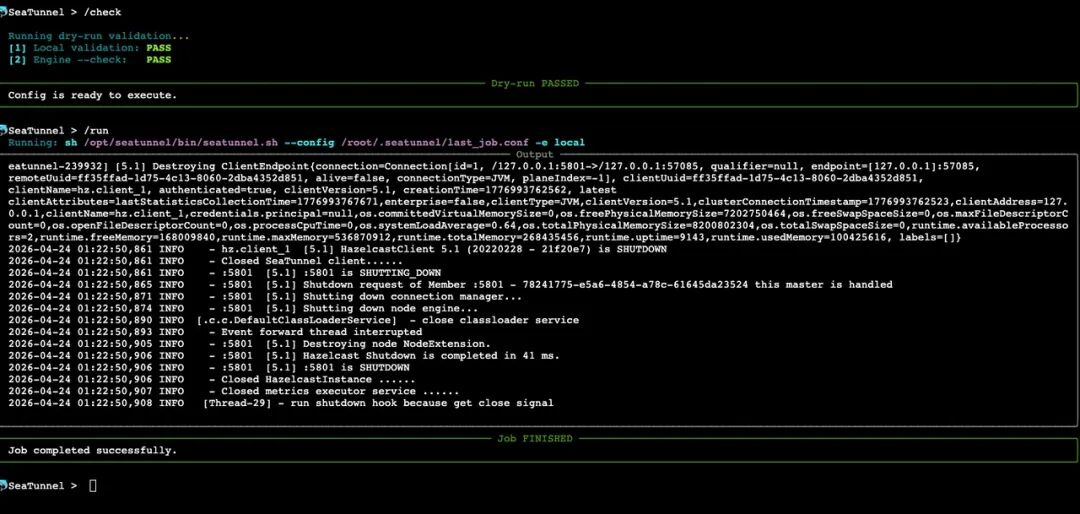
$ seatunnel "同步 MySQL users 表到 S3,Parquet 格式"✅ 配置已生成,验证通过。保存到 mysql_users_to_s3.conf
这就是 SeaTunnel AI CLI 在做的事。这篇文章将介绍我们在设计和实现这个功能时,真正面对的几个核心问题和思考。
AI 生成配置这件事,核心挑战只有一个字——准。
配置文件不像自然语言文本,有一点模糊也能被人理解。一个 Pipeline 配置要么 100% 能跑,要么就是报错。字段名写错一个字母、必填项漏一个、类型给错一个——全部是致命错误。
我们所有的架构决策,都是围绕"如何让生成结果从第一次就是准确的"这个目标展开的。
1. 参数知识的准确:为什么必须用 Runtime 反射
LLM 生成配置的质量完全取决于它对 connector 参数的理解。如果你告诉 LLM "Jdbc Source 需要 connection_url 字段",它就会老老实实生成 connection_url——但 SeaTunnel 实际需要的是 url。一个字段名的偏差,整个 Pipeline 就跑不起来。
我们踩过的坑:第一版用 Python 脚本解析 Java 源码来提取参数定义。结果大面积出错:
最终结果:生成的 metadata JSON 准确率只有约 30%。LLM 拿着错误的知识,生成的配置基本跑不起来。
正确方案:让 JVM 告诉我们真相。
SeaTunnel 的每个 connector 都实现了 factory.optionRule() 方法——这是引擎在运行时真正使用的参数校验规则。我们直接在 Java 层实例化所有 Factory,调用这个 SPI:
ServiceLoader 发现所有 Factory → 逐个调用 factory.optionRule() → 获得完整规则(required / optional / conditional / bundled / exclusive) → 序列化为结构化 JSON
这样拿到的参数定义和 SeaTunnel 引擎使用的是同一份数据。不存在"解析偏差"这回事——因为根本没有解析,是直接读取。
一个关键的子决策:Source 和 Sink 必须分开存储。
同一个 connector 名(比如 Jdbc)作为 Source 和 Sink 时参数完全不同——Sink 有 schema_save_mode、data_save_mode,Source 没有;Source 有 query、partition_column,Sink 没有。如果合在一起,LLM 会给 Source 生成 Sink 才有的参数,反之亦然。
我们用(connector_type, connector_name)作为存储 key:
{ "source:Jdbc": { "required": ["url", "driver"], "optional": ["query", "partition_column", ...] }, "sink:Jdbc": { "required": ["url", "driver"], "optional": ["schema_save_mode", "data_save_mode", ...] }}
Planner 识别出"用户需要 Jdbc 作为 Source"后,只注入 source:Jdbc 的参数知识给 Config Generator。Sink 的参数对这次生成完全不可见,从根源上消除了混用的可能。
构建时生成,不提交到 Git:
这份 JSON 不应该是手动维护的文件。我们在 CI 构建过程中自动执行反射,生成的 JSON 直接打进构建产物。Git 仓库里只有生成工具的代码,没有 JSON 文件。Connector 加了新参数,下次构建自动更新,零人工干预。
2. 场景覆盖的准确:Skill + Golden Sample 设计
参数知识准确了,但 LLM 仍然可能生成结构错误的配置——因为 SeaTunnel 的 Pipeline 拓扑不止一种模式。
我们分析了用户实际使用的场景,发现可以归类为三大类,每一类的配置结构完全不同:
最简单的场景——一个 Source 到一个 Sink:
配置结构清晰,无歧义:
source { Jdbc { ... } }sink { S3File { ... } }
这类场景 LLM 的直觉基本正确,准确率较高。
中间加了数据处理逻辑:
MySQL ──→ SQL Transform (过滤/脱敏/聚合) ──→ S3
配置需要正确的 plugin_output / plugin_input 路由:
source { Jdbc { plugin_output = "raw_data"; ... } }transform { Sql { plugin_input = "raw_data"; plugin_output = "cleaned"; query = "..." } }sink { S3File { plugin_input = "cleaned"; ... } }
LLM 容易犯的错:忘记写 plugin_output / plugin_input,或者使用已废弃的 result_table_name / source_table_name。
场景三:复杂多分支链路(Multi-Pipeline)
多个 Source、多个 Sink、分支路由:
MySQL (orders) ──┐ ├──→ ConsoleMySQL (audit_log) ──┘MySQL (users) ──────────→ Assert
这是 LLM 最容易出错的场景。我们在真实测试中发现了一个典型问题——LLM 会自己发明 connector 名称:
source { Jdbc1 { ... } Jdbc2 { ... } }
LLM 的"直觉"是:两个同类 connector 需要不同的名字来区分。这在很多编程语言里是合理的(变量名不能重复),但 SeaTunnel 的 HOCON 配置允许同名 key 重复出现,通过 plugin_output 来区分:
source { Jdbc { plugin_output = "orders_stream" query = "SELECT * FROM orders" ... } Jdbc { plugin_output = "users_stream" query = "SELECT * FROM users" ... }}sink { Console { plugin_input = "orders_stream" } Assert { plugin_input = "users_stream" }}
Skill SOP:场景化的生成指导
为了解决不同场景的结构差异问题,我们引入了 Skill SOP(Standard Operating Procedure) 机制——为每类场景定义一套明确的生成规则和约束。
Skill 的核心思想是:不要指望 LLM 从通用知识中推理出 SeaTunnel 的特定配置规范,而是把规范显式地告诉它。
Skill: "multi_source_same_connector"触发条件: 检测到用户需要多个同类型 Source约束规则: 1. 绝不修改 connector 标识符(永远用 "Jdbc" 而非 "Jdbc1") 2. 每个同类型实例必须有不同的 plugin_output 3. 下游通过 plugin_input 指定消费哪个流 4. 禁止使用 result_table_name / source_table_name(已废弃)生成模板: source { ${connector} { plugin_output = "${stream_name_1}" ... } ${connector} { plugin_output = "${stream_name_2}" ... } }
Golden Sample:用正确示例锚定 LLM 的输出格式
每个 Skill 配套一组 Golden Sample——经过人工验证、确认可以直接在 SeaTunnel 上运行的完整配置示例。
Golden Sample 的作用不是让 LLM 去"模仿",而是让它理解 "这类场景正确的输出长什么样":
Golden Sample: single_jdbc_to_s3.conf场景: 单表从 MySQL 同步到 S3 Parquet验证状态: ✅ 在 SeaTunnel 2.3.9 上运行通过env { job.mode = "BATCH" }source { Jdbc { url = "${MYSQL_URL}" driver = "com.mysql.cj.jdbc.Driver" user = "${MYSQL_USER}" password = "${MYSQL_PASSWORD}" query = "SELECT * FROM users" }}sink { S3File { bucket = "${S3_BUCKET}" path = "/data/users/" file_format_type = "parquet" ... }}
Golden Sample: multi_jdbc_to_multi_sink.conf场景: 同一个 MySQL 实例的多张表路由到不同 Sink验证状态: ✅ 在 SeaTunnel 2.3.9 上运行通过env { job.mode = "BATCH" }source { Jdbc { plugin_output = "orders_data" url = "${MYSQL_URL}" driver = "com.mysql.cj.jdbc.Driver" user = "${MYSQL_USER}" password = "${MYSQL_PASSWORD}" query = "SELECT * FROM orders" } Jdbc { plugin_output = "users_data" url = "${MYSQL_URL}" driver = "com.mysql.cj.jdbc.Driver" user = "${MYSQL_USER}" password = "${MYSQL_PASSWORD}" query = "SELECT * FROM users" }}sink { Console { plugin_input = "orders_data" } S3File { plugin_input = "users_data"; ... }}
Skill + Golden Sample 的组合效果:
为什么不只用 Golden Sample 而需要 Skill SOP?
Golden Sample 解决的是"正确的输出长什么样"——这是示例层面的。但 LLM 面对的用户请求千变万化,它需要理解规则背后的逻辑才能泛化。
Skill SOP 提供的是可泛化的约束规则:
- "当有多个同类型 connector 时→ 必须用 plugin_output 区分"
- "当用户提到'实时同步'或'变更捕获'时→ 使用 CDC connector 而非普通 Jdbc"
- "当有 Transform 时→ 整条链路必须有完整的 plugin_output → plugin_input 串联"
Skill = 规则(可泛化)+ Golden Sample = 锚点(确保格式正确)。两者缺一不可。
3. 验证闭环的准确:结构化错误反馈 + 自愈
即使有了精确的参数知识和场景化 Skill,LLM 仍然可能出错——这是概率模型的本质特征。我们不追求"一次生成永远正确",而是设计了一个确定性验证 + 结构化反馈的闭环:
LLM 生成配置 ↓Validator 检查(纯规则,不用 LLM): ├── Connector 名是否存在? → 拦截 "Jdbc1" 这类幻觉 ├── 所有 required 字段齐全? → 拦截遗漏 ├── Key 是否在合法集合中? → 拦截拼写错误 ├── 值类型是否匹配? → 拦截类型错误 └── plugin_output/input 链路完整? → 拦截断链 ↓ 有错误? ├── YES → 结构化错误描述回传 LLM 重新生成 │ "Missing required 'url' in Jdbc source. │ Unknown key 'Jdbc1', did you mean 'Jdbc'? │ Use plugin_output for multi-instance routing." │ (最多 3 轮) │ └── NO → ✅ 输出可运行配置
关键设计:错误信息必须是结构化的、可操作的。
不是给 LLM 一个模糊的 "config invalid",而是精确告诉它哪里错了、应该是什么、怎么改。这让自愈的成功率大幅提升。
实测数据:
- 3 轮仍未通过:~2%(通常是极端复杂场景,回退到人工)
4. Multi-Agent 协作:为什么要拆开
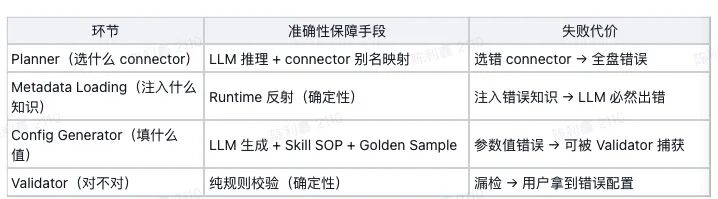
把"理解意图""生成配置""验证结果"拆成独立的 Agent,除了前面提到的 Context Window 和角色混淆问题,还有一个更根本的原因——每个环节的准确性要求和保障手段不同:
拆开后,确定性的部分(Metadata Loading、Validator)用确定性手段保障;不确定的部分(Planner、Generator)用 LLM + 约束 + 闭环修正保障。不让不确定性在链路中无限制地传播。
这个 feature 的安全挑战比一般的 AI 工具更严峻,因为数据集成场景天然充满敏感信息——数据库密码、Cloud Access Key、API Token。
1. 威胁模型
风险 1: 用户密码通过 LLM Prompt 发送到第三方 API → 密钥泄漏给 LLM 供应商风险 2: 生成的配置文件包含明文密码 → 被误提交到 Git / 被其他人读取风险 3: Session Memory 持久化了敏感上下文 → 跨会话 / 跨用户泄漏
2. 设计原则:Secure by Default
核心原则只有一条——敏感信息绝不离开用户本地环境,除非用户显式要求。
具体实现是全链路脱敏:任何匹配 password|token|secret|api_key|access_key|private_key 模式的字段值,在所有路径上自动替换为环境变量占位符:
用户输入 "password=mySecret123" ↓发送给 LLM 的 Prompt: password = "${JDBC_PASSWORD}" ↓生成的配置文件: password = "${JDBC_PASSWORD}" ↓Session Memory 持久化: password = "${JDBC_PASSWORD}"
LLM 从头到尾看不到真实密码。生成的配置文件天然安全,用户通过环境变量在运行时注入真实值。
作为 Apache 顶级项目,这是不可妥协的红线。社区 review 中,安全问题被明确标记为 Blocking——不解决这个问题,功能再好也不会被合并。
AI CLI 不是孤立存在的。它和社区正在推进的 Dry-Run 验证(PR #10763)形成闭环——AI 生成配置 → dry-run 的 Layer 0-3 做渐进验证 → 结构化错误回传 → AI 自修复。
往前看,AI 配置生成只是起点。我们在思考几个方向:
- AI 理解数据:不只生成连接参数,还能读取源 Schema、自动做类型映射、用自然语言描述 Transform 逻辑
- AI 运维管线:Pipeline 出了问题自动诊断,CDC 源表 DDL 变更自动适应
- AI 优化一切:分析运行瓶颈,建议调优方案,规划最优 Pipeline 拓扑
这些方向目前还在构想阶段。我们公开出来,是希望和社区一起讨论优先级和设计方案。
试用与反馈:用 AI CLI 生成各种场景的配置(MySQL→S3、Kafka→Jdbc、CDC→Hive...),告诉我们哪些场景成功、哪些失败。每一个真实的失败案例都是改进方向。
Skill 和 Golden Sample 补充:为更多场景编写 Skill SOP 和经过验证的 Golden Sample。这是提升覆盖度最直接的方式。
设计讨论:在 dev@seatunnel.apache.org 或 GitHub Issue 中参与未来方向的技术讨论。好的设计来自多元视角的碰撞。
- GitHub: https://github.com/apache/seatunnel
- PR: https://github.com/apache/seatunnel/pull/10789
- 邮件列表: dev@seatunnel.apache.org
数据集成是每个企业都依赖的基础设施。让它变得更易用、更智能、更安全——这件事值得我们一起做。
Apache SeaTunnel
Apache SeaTunnel是一个云原生的多模态、高性能海量数据集成工具。北京时间 2023 年 6 月1 日,全球最大的开源软件基金会ApacheSoftware Foundation正式宣布SeaTunnel毕业成为Apache顶级项目。目前,SeaTunnel在GitHub上Star数量已达9k+,社区达到7000+人规模。SeaTunnel支持在云数据库、本地数据源、SaaS、大模型等170多种数据源之间进行数据实时和批量同步,支持CDC、DDL变更、整库同步等功能,更是可以和大模型打通,让大模型链接企业内部的数据。
https://github.com/apache/seatunnelhttps://seatunnel.apache.org/https://seatunnel.apache.org/download我们相信,在「Community Over Code」(社区大于代码)、「Open and Cooperation」(开放协作)、「Meritocracy」(精英管理)、以及「多样性与共识决策」等 The Apache Way 的指引下,我们将迎来更加多元化和包容的社区生态,共建开源精神带来的技术进步!我们诚邀各位有志于让本土开源立足全球的伙伴加入 SeaTunnel 贡献者大家庭,一起共建开源!https://github.com/apache/seatunnel/issueshttps://github.com/apache/seatunnel/pullsdev-subscribe@seatunnel.apache.orghttps://join.slack.com/t/apacheseatunnel/shared_invite/zt-3uouszk3m-PtLLNyZsJVqE5Gb6gn24mAhttps://x.com/ASFSeaTunnel