在本周的 Apache SeaTunnel Meetup 上,项目活跃贡献者 梁尧博为我们分享了一场非常精彩的话题——AI 时代下如何更高效地进行 SeaTunnel 本地调试。他通过细致的讲解,从环境准备到调试跑通的整个过程都进行了详细的展示,让已经或者打算上手 SeaTunnel 的观众都对如何进行源码调试、问题定位和自己修 bug 有了更直观和深入的了解。现在,分享内容已经整理成文字版,供大家学习参考。
很多人平时用 SeaTunnel,更多是停留在“会配任务、能把流程跑起来”这个阶段。但一旦到了真实项目里,问题往往不会这么听话。可能是依赖冲突,可能是参数不生效,可能是连接器行为和预期不一样,也可能是某个版本本身就有 bug。
这个时候,光会改配置通常不够,最后还是得回到源码、日志、断点和本地调试。只有你能把问题在自己电脑上复现出来,知道它到底卡在哪一层,AI 才能真正帮你分析、改代码、验证结果。
所以本次分享想讲的不是“怎么把 SeaTunnel 跑起来”,而是怎么再往前走一步,做到能看源码、能本地调试、能自己查问题、能自己修 bug。AI 在这里不是替你做判断的人,而是一个很强的搭档。前提是,你得先把环境和问题握在自己手里。
适用人群
适合已经接触或正在使用 SeaTunnel 的数据开发、实施、运维人群,尤其适合那些希望进一步学会源码调试、问题定位和自己修 bug 的人。
官方文档:https://seatunnel.apache.org/zh-CN/
先准备这些基础环境:
这些工具的安装这里就不展开了。如果你本身在写 Java,这一段一般都不陌生。
补一句和 Windows 有关的提醒:
- 如果你要调试 Hive、Iceberg 这类连接器,后面很可能会碰到
HADOOP_HOME 或 winutils 的问题,文末会单独讲。
仓库位置可以从官方文档直接跳转:
![]()
官方仓库:
https://github.com/apache/seatunnel
Fork 完以后,你自己的仓库地址会类似这样:
https://github.com/LeonYoah/seatunnel.git
为什么建议先 fork:
如果网络不太稳定,可以借助代理地址:
git clone https://cdn.gh-proxy.org/https://github.com/LeonYoah/seatunnel.gitcd seatunnelgit checkout 2.3.13-release
如果本地提示没有这个分支,可以先把官方仓库加成上游:
git remote add upstream https://cdn.gh-proxy.org/https://github.com/apache/seatunnel.gitgit fetch upstream --prunegit checkout 2.3.13-release
补充一个常用地址,平时能直接记一下:
https://gh-proxy.com/
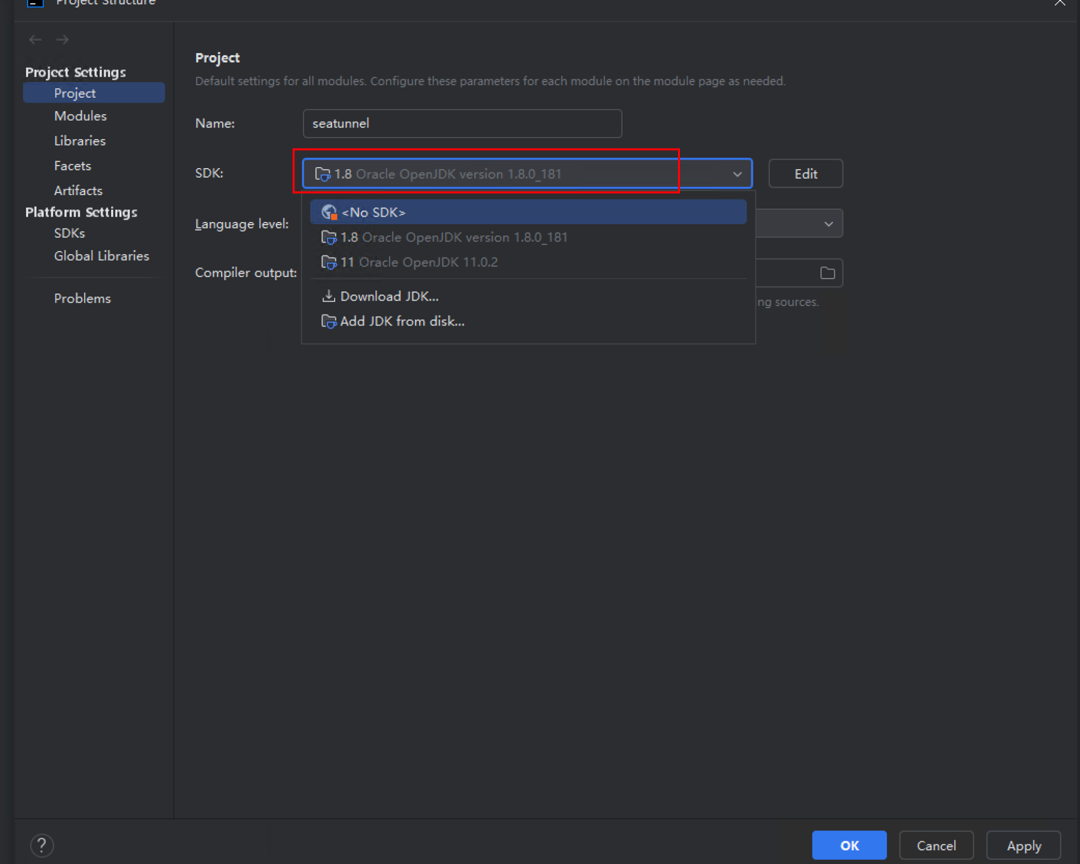
先用 IDEA 打开 seatunnel 项目,然后到 Project Structure 里把 JDK 指到 JDK 8:
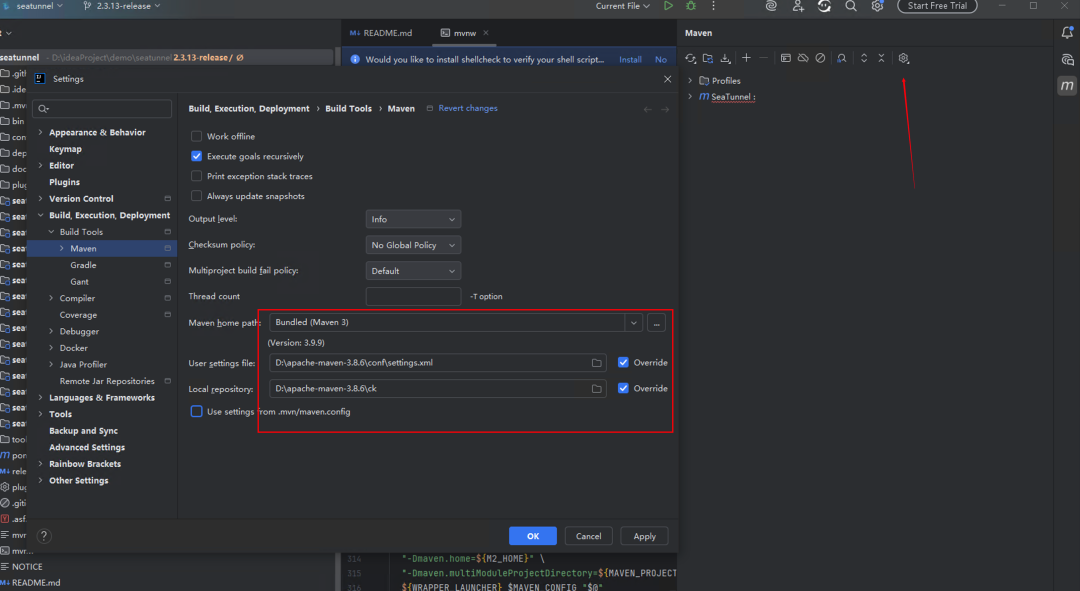
然后再看 Maven 设置。
如果你接受把依赖装到系统默认位置,C 盘,且网络环境很好,这一步其实可以简单一点,因为 IDEA 自带 Maven。
如果你想单独指定 Maven 路径,可以先安装自己的 Maven,然后在 $MAVEN_HOME/conf/settings.xml 里配镜像。下面这份只是参考,本地仓库路径记得换成你自己的:
<?xml version="1.0" encoding="UTF-8"?><settings xmlns="http://maven.apache.org/SETTINGS/1.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0 http://maven.apache.org/xsd/settings-1.0.0.xsd"> <localRepository>D:\apache-maven-3.8.6\ck</localRepository> <proxies> </proxies> <servers> </servers> <mirrors> <mirror> <id>alimaven</id> <name>aliyun maven</name> <url>http://maven.aliyun.com/nexus/content/groups/public/</url> <mirrorOf>central</mirrorOf> </mirror> <mirror> <id>repo1</id> <mirrorOf>central</mirrorOf> <name>central repo</name> <url>http://repo1.maven.org/maven2/</url> </mirror> <mirror> <id>repo2</id> <name>Mirror from Maven Repo2</name> <url>https://repo.spring.io/plugins-release/</url> <mirrorOf>central</mirrorOf> </mirror> </mirrors> <profiles> </profiles></settings>
然后再到 IDEA 设置里确认:
这里有一项容易漏:
use settings from .mvn/config
接着执行下面两个命令:
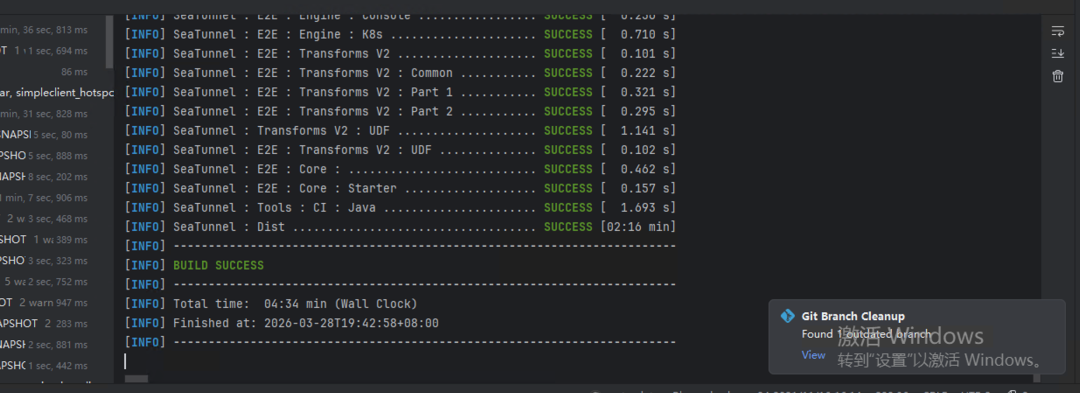
mvn spotless:applymvn clean install -Dmaven.test.skip=true -T 1C
编译完成以后,就可以开始本地调试了。
常用启动类:
org.apache.seatunnel.example.engine.SeaTunnelEngineLocalExample
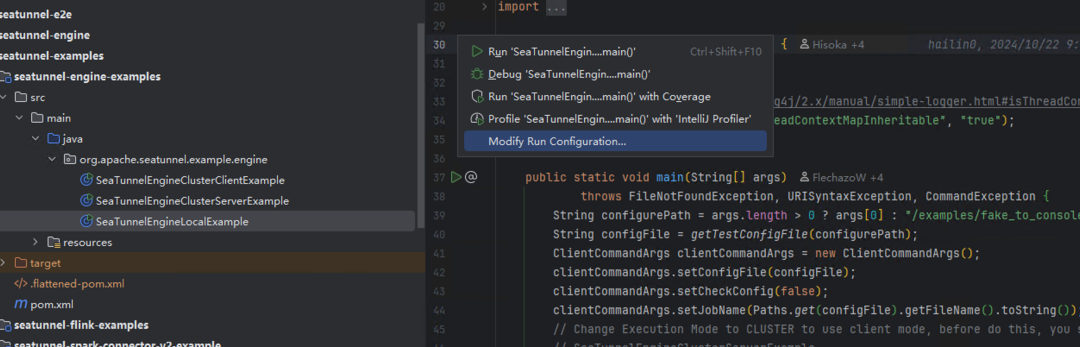
先改启动配置:
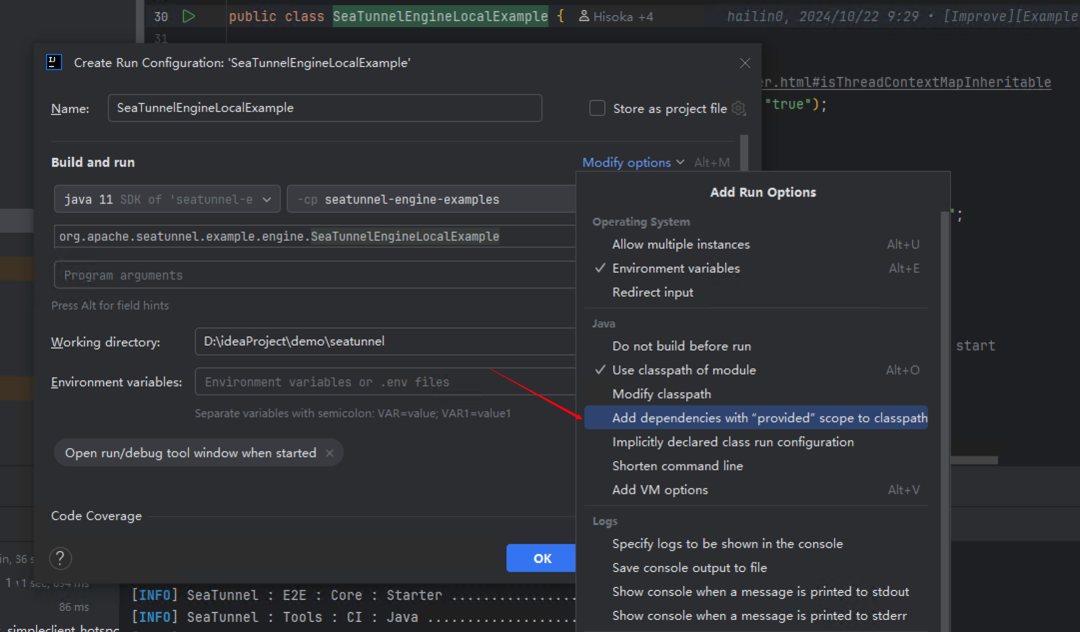
把 provided 带上:
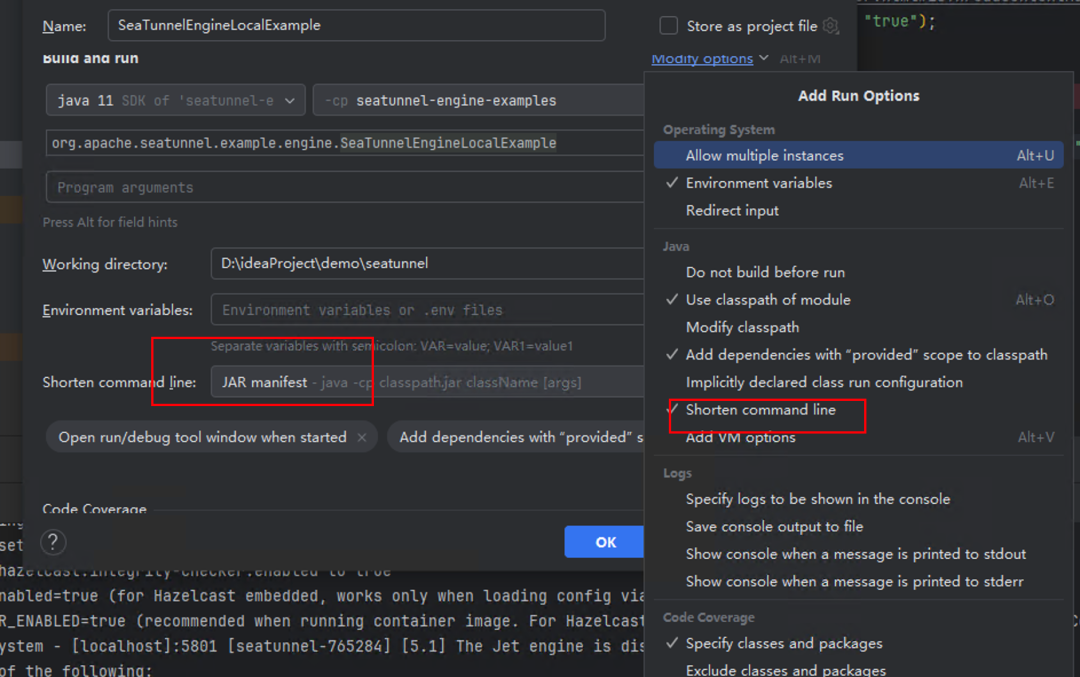
然后点击 Shorten command line,选择 JAR manifest:
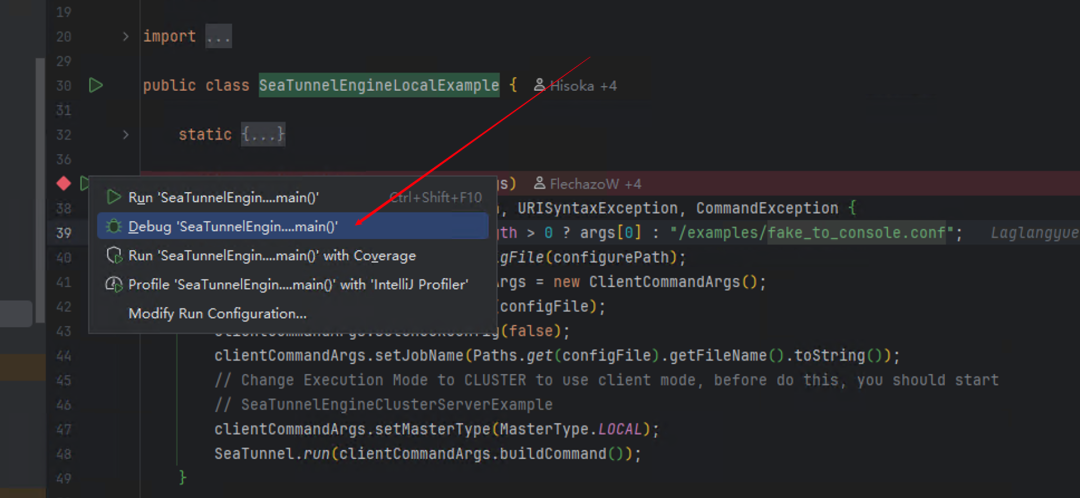
最后用 Debug 模式运行:
代码里有这样一行:
String configurePath = args.length > 0 ? args[0] : "/examples/fake_to_console.conf";
这行代码的意思很直接:
- 如果没传,就默认读
/examples/fake_to_console.conf
所以,自己的配置文件一般放到 examples 目录下最省事:
这里拿一个真实问题举例。
群里有人反馈 pg cdc 任务报错:
原始堆栈:
at org.apache.seatunnel.connectors.cdc.base.source.reader.IncrementalSourceSplitReader.fetch(IncrementalSourceSplitReader.java:94) at org.apache.seatunnel.connectors.seatunnel.common.source.reader.fetcher.FetchTask.run(FetchTask.java:54) ... 7 moreCaused by: org.apache.seatunnel.common.utils.SeaTunnelException: Read split SnapshotSplit(tableId=traffic.public.users, splitKeyType=ROW<id INT>, splitStart=null, splitEnd=null, lowWatermark=null, highWatermark=null) error due to java.lang.NullPointerException. at org.apache.seatunnel.connectors.cdc.base.source.reader.external.IncrementalSourceScanFetcher.checkReadException(IncrementalSourceScanFetcher.java:216) at org.apache.seatunnel.connectors.cdc.base.source.reader.external.IncrementalSourceScanFetcher.pollSplitRecords(IncrementalSourceScanFetcher.java:117) at org.apache.seatunnel.connectors.cdc.base.source.reader.IncrementalSourceSplitReader.fetch(IncrementalSourceSplitReader.java:91) ... 8 moreCaused by: io.debezium.DebeziumException: java.lang.NullPointerException at org.apache.seatunnel.connectors.seatunnel.cdc.postgres.source.reader.snapshot.PostgresSnapshotSplitReadTask.execute(PostgresSnapshotSplitReadTask.java:112) at org.apache.seatunnel.connectors.seatunnel.cdc.postgres.source.reader.snapshot.PostgresSnapshotFetchTask.execute(PostgresSnapshotFetchTask.java:65) at org.apache.seatunnel.connectors.cdc.base.source.reader.external.IncrementalSourceScanFetcher.lambda$submitTask$0(IncrementalSourceScanFetcher.java:96) ... 5 moreCaused by: java.lang.NullPointerException at org.apache.seatunnel.connectors.seatunnel.cdc.postgres.source.reader.snapshot.PostgresSnapshotSplitReadTask.createDataEventsForTable(PostgresSnapshotSplitReadTask.java:183) at org.apache.seatunnel.connectors.seatunnel.cdc.postgres.source.reader.snapshot.PostgresSnapshotSplitReadTask.createDataEvents(PostgresSnapshotSplitReadTask.java:170) at org.apache.seatunnel.connectors.seatunnel.cdc.postgres.source.reader.snapshot.PostgresSnapshotSplitReadTask.doExecute(PostgresSnapshotSplitReadTask.java:136) at org.apache.seatunnel.connectors.seatunnel.cdc.postgres.source.reader.snapshot.PostgresSnapshotSplitReadTask.execute(PostgresSnapshotSplitReadTask.java:107) ... 7 more
这类问题,有明确报错的,我们第一反应 应该先看堆栈里最靠后的 Caused by。很多时候,最后一个 Caused by 才是最原始的异常来源。
这次堆栈里最关键的信息其实是:
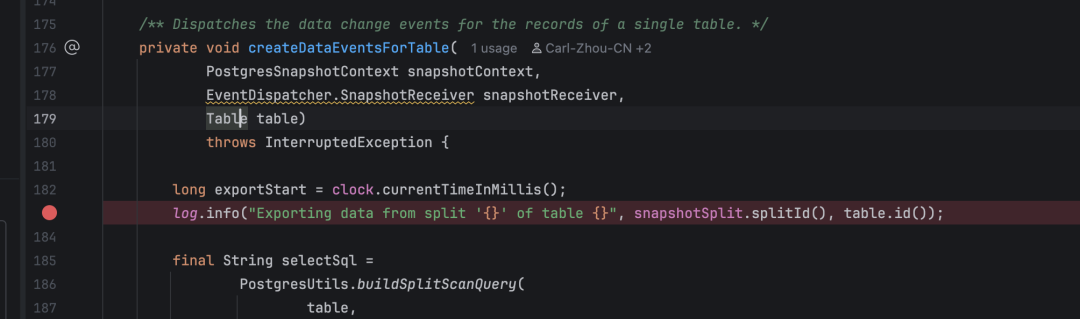
Caused by: java.lang.NullPointerExceptionat org.apache.seatunnel.connectors.seatunnel.cdc.postgres.source.reader.snapshot.PostgresSnapshotSplitReadTask.createDataEventsForTable(PostgresSnapshotSplitReadTask.java:183)
看到这里,排查思路就清楚了:
在 IDEA 里按两次 Shift,搜索 PostgresSnapshotSplitReadTask.java:183,然后定位到 183 行:
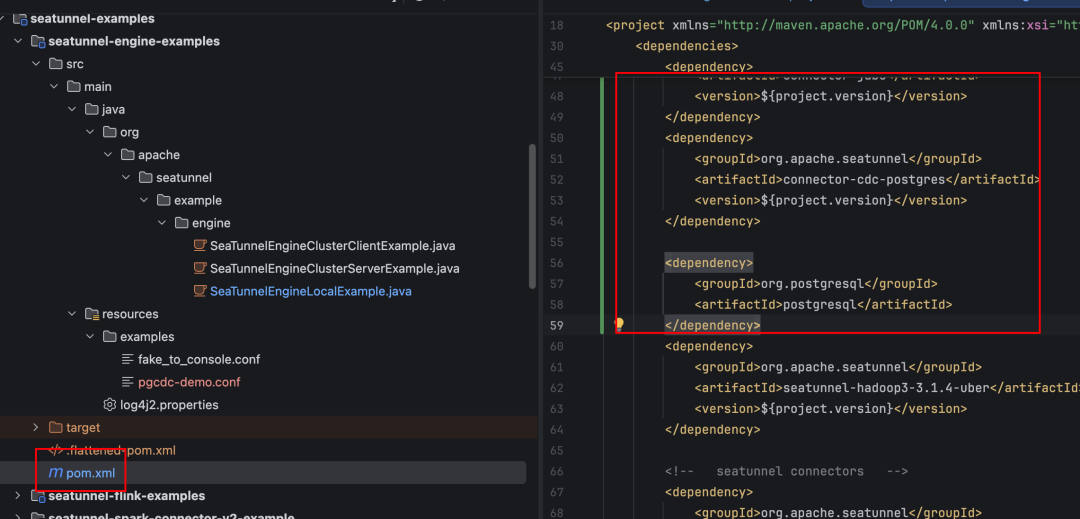
因为这是 pg-cdc 的问题,所以你还得先把相关依赖补到当前运行环境对应的 pom.xml 里:
<dependency> <groupId>org.apache.seatunnel</groupId> <artifactId>connector-jdbc</artifactId> <version>${project.version}</version></dependency><dependency> <groupId>org.apache.seatunnel</groupId> <artifactId>connector-cdc-postgres</artifactId> <version>${project.version}</version></dependency><dependency> <groupId>org.apache.seatunnel</groupId> <artifactId>connector-cdc-base</artifactId> <version>${project.version}</version></dependency><dependency> <groupId>org.postgresql</groupId> <artifactId>postgresql</artifactId> <version>42.7.5</version></dependency>
补完以后刷新 Maven,第一次运行:
发现根本没复现,没出现空指针,那问题出现在哪呢?
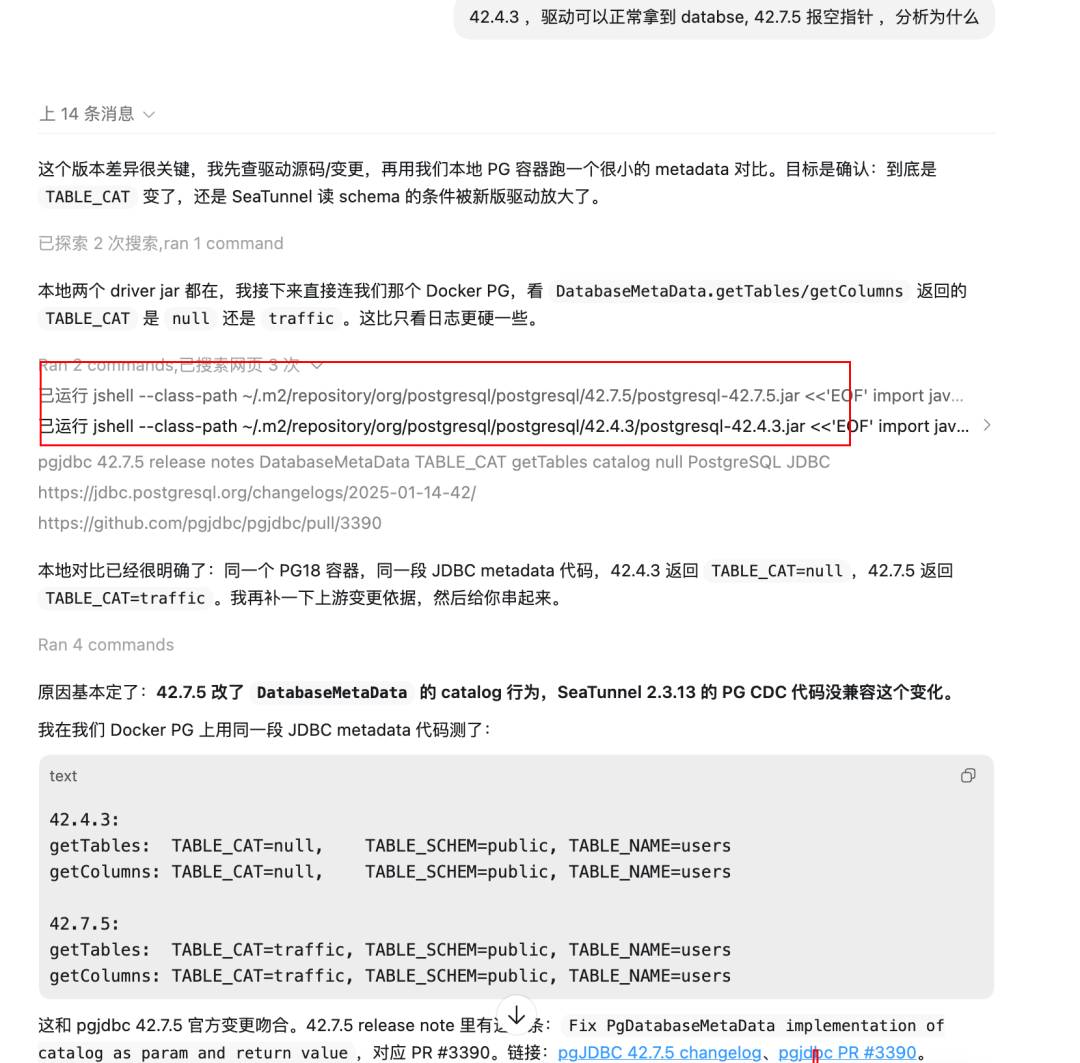
此时我们就应该想到控制变量法,尽可能的保证复现环境一致,于是乎我就又问了出现问题的小伙伴他的 PG 版本 和驱动,确定他的 pg数据库 是 v18,jdbc 驱动是42.7.5 ,我对比发现 我们的驱动是 42.4.3,于是更换驱动...
第二次运行:
更新 pom.xml 然后刷新 Maven,空指针出现!
那么问题就在驱动身上,我们把空指针出现的代码位置以及版本问题告诉AI,AI此时就开始马力全开,按照真正的方向去定位问题。
![]()
总结一下根本原因: 就是驱动版本过高影响的,用 42.4.3 会报错,但是用42.7.5 会出现空指针 。具体排查思路大家可以看这个 pr:https://github.com/apache/seatunnel/pull/10058
ai给出的修复代码:
TableId tableIdWithoutCatalog = new TableId(null, tableId.schema(), tableId.table());Table table = databaseSchema.tableFor(tableIdWithoutCatalog);if (table == null) { String catalog = tableId.catalog(); if (catalog == null || catalog.isEmpty()) { catalog = connectorConfig.databaseName(); } if (catalog != null && !catalog.isEmpty()) { TableId tableIdWithCatalog = new TableId(catalog, tableId.schema(), tableId.table()); table = databaseSchema.tableFor(tableIdWithCatalog); }}if (table == null) { throw new IllegalStateException( String.format("Cannot find table schema for %s", tableId));}createDataEventsForTable(snapshotContext, snapshotReceiver, table);
问题修完以后,再开始打包:
- 找到对应 jar,上传到服务器
connectors目录,替换同名 jar
相关截图:
![]()
这个案例真正想说明的是:
- 其次如果没有你的源码经验和断点信息以及环境复现,那么 AI会走很多弯路,就比如上面的场景,ai 很难联想到是驱动问题,在你给的上下文环境里,它对 驱动,版本这些词语命中率很很低很低。
如果你已经能把项目跑起来,能看源码、打断点、读日志、追调用链路,那 AI 的作用就完全不一样了。它不再只是一个回答问题的工具,而是可以和你一起分析源码、定位异常、修改代码、验证方案的搭档,你能给予 AI 正常的方向,而不是 AI 在茫茫大海中搜寻答案。这样一来,很多原本觉得“工具不支持”“只能绕路解决”的问题,很可能就变成了“我们可以自己修 Bug、改逻辑、做适配,甚至新增一个连接器”,这种从“使用者”到“主导者”的角色转变,无疑为工作带来了极大的主动权和闭环效率。
在当前AI 时代,并不是说我们一开始就可以把所有问题都丢给 AI。相反,越是想用好 AI,越需要先具备一定的源码阅读能力和本地调试能力的基本功。等你逐渐熟练之后,很多重复性的排查和编码工作就可以慢慢交给 全部AI 来做,而你要做的,是负责掌舵:判断方向对不对、方案靠不靠谱、结果有没有被验证。
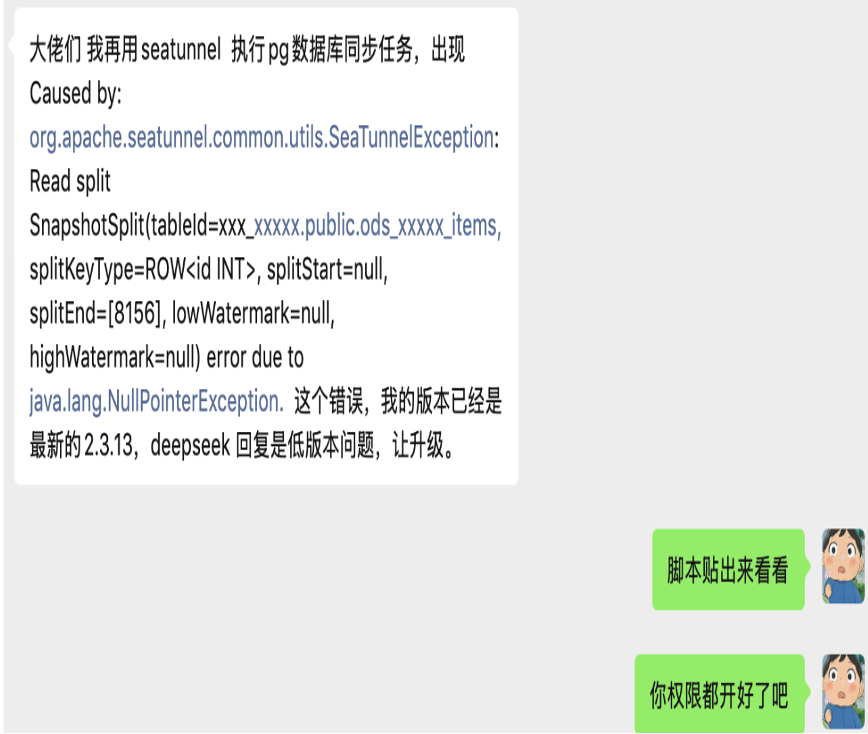
很多人现在一遇到问题,第一反应就是把报错直接复制到网页版 DeepSeek 或 ChatGPT 里。这样不是完全没用,但大多数时候,得到的是“检查配置”“尝试升级版本”“看看依赖是不是冲突”这一类泛化建议。
![]()
这类回答的问题不在于它一定错,而在于它经常不够贴近你当前的项目和环境。尤其是下面这些情况:
所以更推荐的方式是:
这时候,像 Codex、Claude Code 这类工具的价值就会更明显,因为它们不只是“回答一个问题”,而是能直接参与到代码、环境和执行过程中。
参考下面的案例:
这里我们就可以看到, ai能够运行 docker 去跑一个真实 pg环境验证 bug,也能直接调用 jar 包执行去分析DatabaseMetaData的行为,且定位到了真实问题就是驱动版本影响的,这提供了非常大的便利。
8.1 Windows 打包整套 SeaTunnel 后,shell 脚本报错
如果你打的是整套安装包:
mvn clean package -pl seatunnel-dist -am -Dmaven.test.skip=true
参考:
https://www.cnblogs.com/qixing/p/14287479.html
在 Linux 服务器上解压后,如果报这个错:
#/bin/sh^m: 坏的解释器: 没有那个文件或目录
一般是脚本换行符有问题。
可以这样处理:
或者手动处理单个脚本:
sed -i 's/\r$//' seatunnel.sh
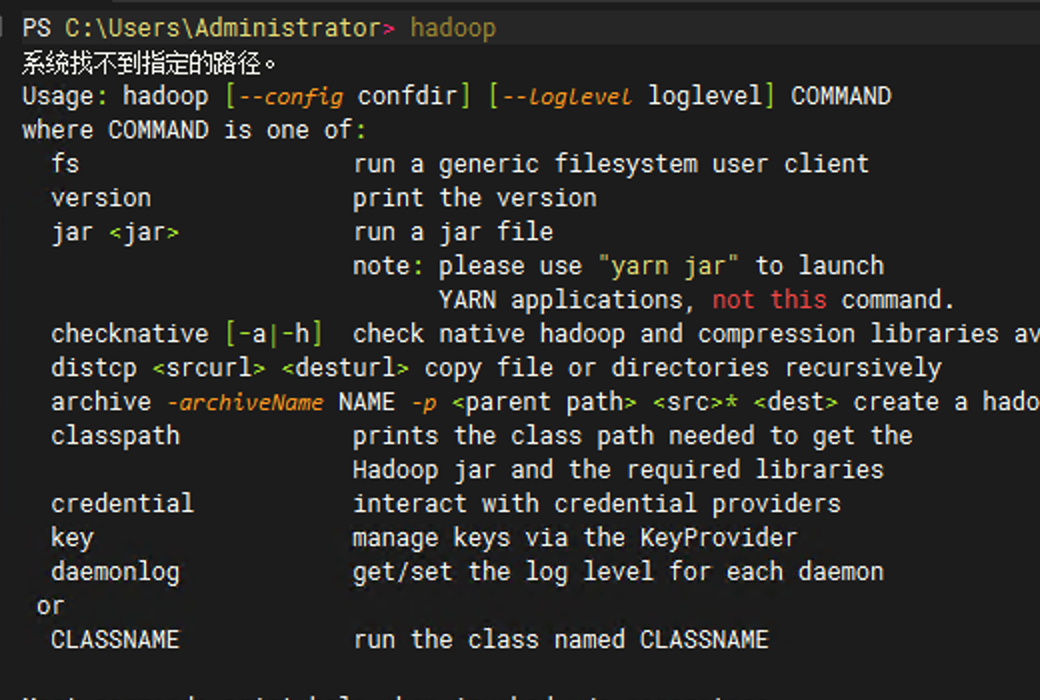
8.2 Windows 下的 HADOOP_HOME / winutils 问题
如果你在 Windows 下调试 Hive、Iceberg 这类连接器,经常会碰到这个错误:
java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset
原因通常不是“少装了一个普通依赖”,而是 Windows 缺少 Hadoop 那部分本地运行支持。
这时候,即使你装了 Hadoop,本地也不一定能直接用。更常见的办法是补 winutils。
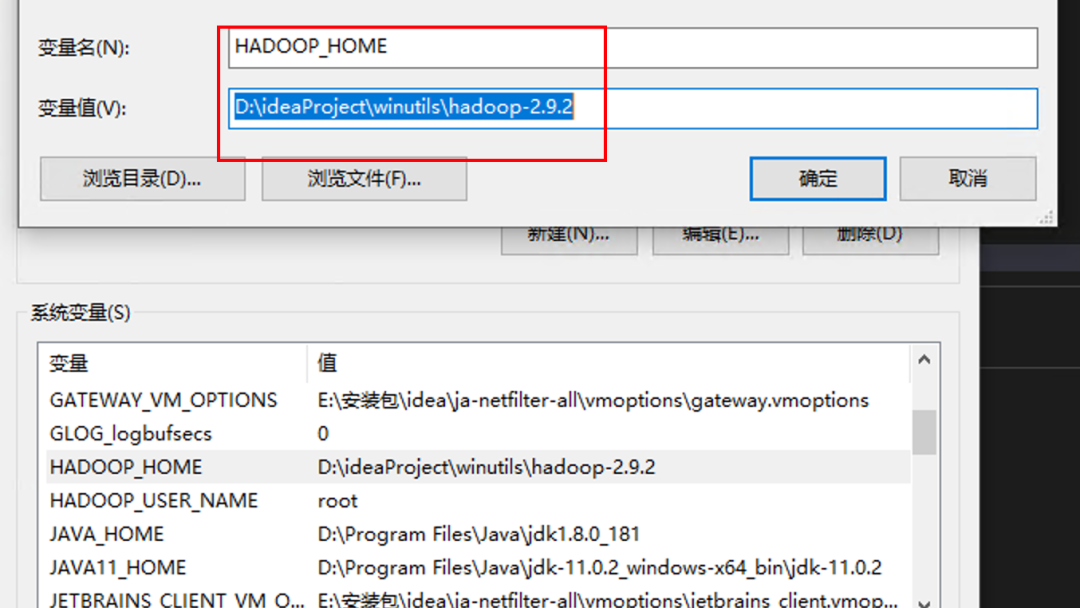
winutils.exe 是 Hadoop 在 Windows 下运行时需要的本地工具,用来补 Linux 环境里的那部分系统调用。从 Hadoop 2.2 开始,这个文件不再跟安装包一起发,所以需要自己下载和配置。
安装步骤:
git clone https://cdn.gh-proxy.org/https://github.com/cdarlint/winutils.git
示例值:
D:\ideaProject\winutils\hadoop-2.9.2
安装完成以后,Windows 就可以正常使用 hadoop 命令了。
AI 时代并没有让读源码和调试过时,恰恰相反,它们变得更有价值了。你越能把环境跑起来、把问题复现出来、把断点打进去,AI 就越能真正帮上忙。
希望这篇分享能让大家从“会配任务、能跑起来”,再往前走一步,变成能看源码、能本地调试、能独立查问题、也能自己修 bug 的人。这样以后再碰到问题,我们就不是只能等答案,而是可以带着 AI 一起把问题查清楚、改明白、真正解决。
Apache SeaTunnel
Apache SeaTunnel是一个云原生的多模态、高性能海量数据集成工具。北京时间 2023 年 6 月1 日,全球最大的开源软件基金会ApacheSoftware Foundation正式宣布SeaTunnel毕业成为Apache顶级项目。目前,SeaTunnel在GitHub上Star数量已达9k+,社区达到7000+人规模。SeaTunnel支持在云数据库、本地数据源、SaaS、大模型等170多种数据源之间进行数据实时和批量同步,支持CDC、DDL变更、整库同步等功能,更是可以和大模型打通,让大模型链接企业内部的数据。
https://github.com/apache/seatunnelhttps://seatunnel.apache.org/https://seatunnel.apache.org/download我们相信,在「Community Over Code」(社区大于代码)、「Open and Cooperation」(开放协作)、「Meritocracy」(精英管理)、以及「多样性与共识决策」等 The Apache Way 的指引下,我们将迎来更加多元化和包容的社区生态,共建开源精神带来的技术进步!我们诚邀各位有志于让本土开源立足全球的伙伴加入 SeaTunnel 贡献者大家庭,一起共建开源!https://github.com/apache/seatunnel/issueshttps://github.com/apache/seatunnel/pullsdev-subscribe@seatunnel.apache.orghttps://join.slack.com/t/apacheseatunnel/shared_invite/zt-3uouszk3m-PtLLNyZsJVqE5Gb6gn24mAhttps://x.com/ASFSeaTunnel