每次在 Apache SeaTunnel
最近 Apache SeaTunnel 社区的 Issue #10339 提案捅破了这层窗户纸:既然有 Apache Gravitino 这么强大的元数据服务,为什么不直接让它自动同步 Schema?这个提议一出,社区反响热烈,核心维护者们已经把它列入了年度 RoadMap 。目前的讨论很务实,大家正盯着怎么让 Apache SeaTunnel 在提交作业时自动‘抓取’最新的元数据,好让大家彻底告别那种‘对着数据库手敲配置’的原始生活。
Issue 链接: https://github.com/apache/seatunnel/issues/10339
先来看看提交这个 Issue 的作者是为什么想到这个点子的,以及他初步的核心设计概念。
本 PR 实现了 Apache Gravitino 与 SeaTunnel 的集成,将其作为非关系型连接器的外部元数据服务。通过 Gravitino 的 REST API 自动获取表结构和元数据,SeaTunnel 用户无需再在连接器配置中手动定义冗长且复杂的 Schema 映射。
背景 目前,Apache SeaTunnel 中的许多非关系型连接器(如 Elasticsearch、向量数据库和数据湖引擎)要求用户在作业配置中显式定义完整的列 Schema。这导致了以下问题:
配置繁琐且易错: 字段映射内容冗长,极易发生人为错误。
架构冗余: 不同作业之间存在大量重复的 Schema 定义。
数据不一致风险: 实际存储层与 SeaTunnel 配置文件之间容易出现架构脱节。
变更内容 本 PR 增加了 基于 Gravitino 的 Catalog 和 Schema 解析器 ,使 SeaTunnel 能够:
通过 REST API 从 Gravitino 查询表定义。 直接根据 Gravitino 元数据构建 SeaTunnel 内部 Schema。 针对受支持的连接器,取消强制手动定义 schema { fields { ... } } 的要求。 实现后,用户只需在作业配置中指定 Gravitino Catalog 和相关的表引用即可。
核心优势 零手动映射: 非关系型数据源实现 Schema 自动对齐。
单一事实来源: 确保表结构与中心化元数据仓库保持高度一致。
提升可靠性: 显著提高配置的准确性,降低长期维护成本。
支持复杂类型: 通过统一元数据,简化了对嵌套结构、JSON、向量等高级类型的处理。
执行范围 所有基于 Gravitino 的 Schema 解析和校验均在 SeaTunnel Engine 客户端 完成(即在作业提交前)。这种设计确保了:
在作业预检阶段即可发现无效或不兼容的 Schema。 运行时的任务仅接收经过验证和标准化的 Schema,降低了执行失败的概率。 影响 这一更新极大地简化了非关系型连接器的作业设置。除了提升易用性,它还为整个 SeaTunnel 生态系统在统一架构管理、架构演进以及高级数据类型支持方面奠定了技术框架。
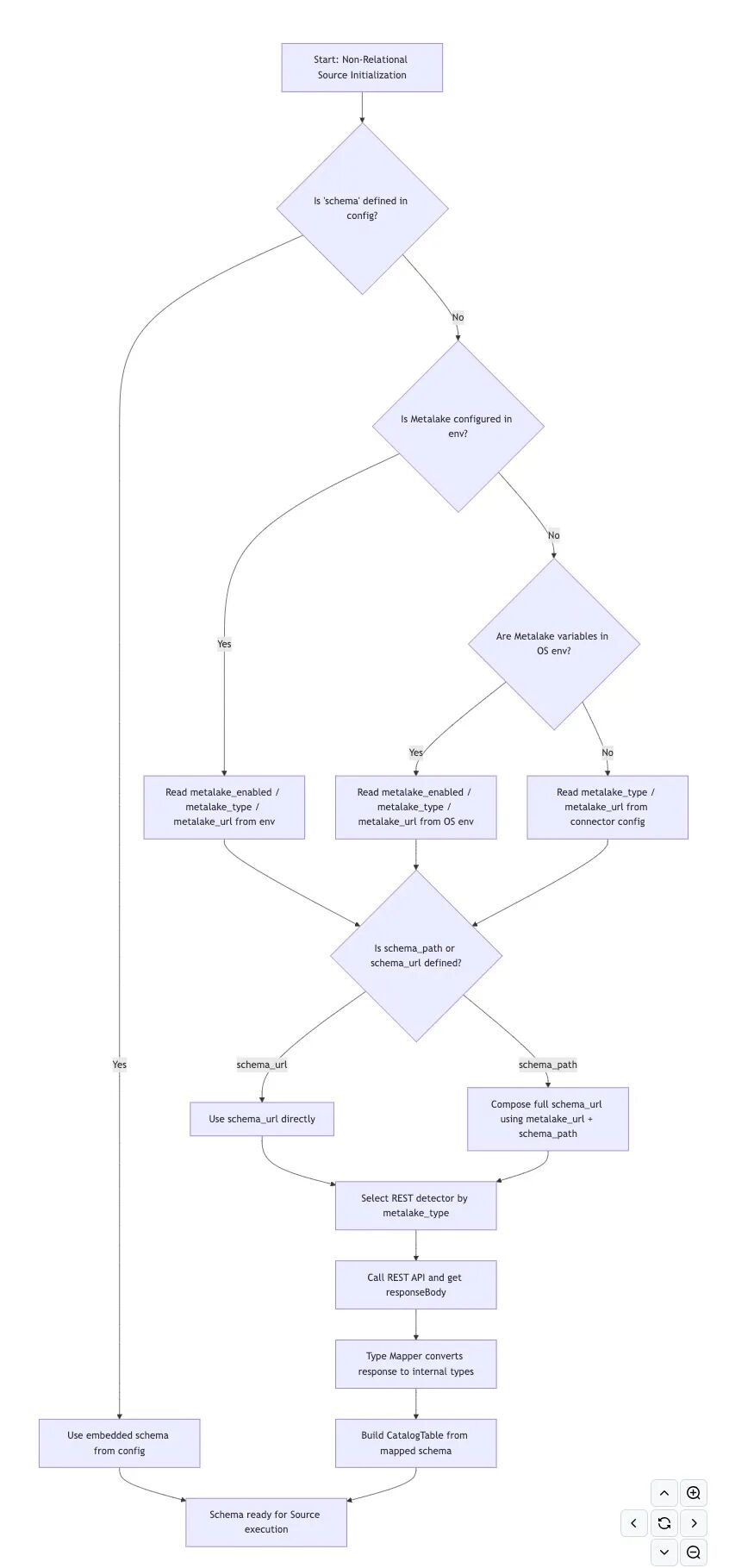
核心思路 针对 FTP、S3、ES、MongoDB 等 半结构化与非结构化数据源 ,SeaTunnel 现支持通过 Gravitino REST API 自动解析表结构(Schema)。
需要注意的是,这 并非 要取代现有的显式配置,而是一项 完全向前兼容的可选新机制 。
解析优先级如下:
1. 显式配置(Inline Schema)永远优先 只要连接器配置中包含了 schema 代码块,SeaTunnel 就 必须忽略 Gravitino ,直接以显式定义的 Schema 为准。
FtpFile { path = "/tmp/seatunnel/sink/text" # ... 其他基础配置 ... # 只要这里定义了,就不会去查 Gravitino schema = { name = string age = int }} 2. 通过 env 全局配置 Gravitino(推荐模式) SeaTunnel 已在引擎层面集成了 Gravitino Metalake。 在 env 中全局开启后,所有非关系型数据源都能直接通过名称引用 Schema。
env { metalake_enabled = true metalake_type = "gravitino" metalake_url = "http://localhost:8090/api/metalakes/metalake_name/catalogs/"} 2.1 使用 schema_path 引用
FtpFile { # ... 基础配置 ... schema_path = "catalog_name.ykw.test_table"} 2.2 使用 schema_url 引用
FtpFile { # ... 基础配置 ... schema_url = "http://localhost:8090/api/metalakes/laowang_test/.../tables/all_type"} 3. 兜底逻辑:读取操作系统环境变量 如果在作业的 env 块中没有定义 Gravitino,SeaTunnel 会尝试从 操作系统环境变量 中读取以下配置: metalake_enabled | metalake_type | metalake_url 其行为逻辑与第 2 节中的 env 配置完全一致。
4. 在连接器层级单独配置 Gravitino 如果全局没有配置元数据中心,也可以在具体的连接器(Connector)内部直接定义 Gravitino。
4.1 直接使用 schema_url
FtpFile { # ... 基础配置 ... metalake_type = "gravitino" schema_url = "http://localhost:8090/api/.../tables/all_type"} 4.2 组合使用 metalake_url 与 schema_path
FtpFile { # ... 基础配置 ... metalake_type = "gravitino" metalake_url = "http://localhost:8090/api/metalakes/metalake_name/catalogs/" schema_path = "catalog_name.ykw.test_table"} 5. 探测器定位 (Find detector) 系统会根据 metalake_type 自动匹配并加载对应的 REST API HTTP 探测器。
6. 映射与构建 CatalogTable 探测器调用拼接好的 URL 获取响应体(ResponseBody),随后将其交给映射器(Mapper)进行类型匹配,最终完成 CatalogTable 的构建。
7. 流程图如下 目前,Apache SeaTunnel 项目核心贡献者对此提议给出了正面评价,并将其添加到 Apache SeaTunnel Roadmap 中。
Apache SeaTunnel PMC Member 对这个提议提出一些疑问,比如这种集成属于哪一层级,对多引擎兼容性的考量,类型转换的准确性等,并根据社区设计规范,要求发起者提交一份正式的设计文档(Design Document)。提交者的回复非常具有建设性,他通过 “客户端预处理”和“抽象 Catalog 接口” 这两个核心设计点,有效地回应了社区对于系统耦合度和运行稳定性的担忧。
目前,这个讨论的回到了该 Issue 的提交者手中,社区正在等待他提交那份正式的 Design Document。
可以看到,这个方案要是落地,咱以后写任务可能就一两行配置的事儿。目前设计稿正在打磨中,非常需要大家去评论区吐吐槽、提提建议,毕竟这个功能好不好用,咱们一线开发者最清楚。走,去 GitHub 围观一下,说不定你的一个提议就能决定下一个版本的样子! https://github.com/apache/seatunnel/issues/10339
Apache SeaTunnel Apache SeaTunnel是一个云原生的多模态、高性能海量数据集成工具。北京时间 2023 年 6 月1 日,全球最大的开源软件基金会ApacheSoftware Foundation正式宣布Apache SeaTunnel毕业成为Apache顶级项目。目前,SeaTunnel在GitHub上Star数量已达8k+,社区达到6000+人规模。SeaTunnel支持在云数据库、本地数据源、SaaS、大模型等170多种数据源之间进行数据实时和批量同步,支持CDC、DDL变更、整库同步等功能,更是可以和大模型打通,让大模型链接企业内部的数据。
https://github.com/apache/seatunnel https://seatunnel.apache.org/ https://seatunnel.apache.org/download 我们相信,在 「 Community Over Code 」 (社区大于代码)、 「Open and Cooperation」 (开放协作)、 「Meritocracy」 (精英管理)、以及「 多样性与共识决策」 等 The Apache Way 的指引下,我们将迎来更加多元化和包容的社区生态,共建开源精神带来的技术进步! 我们诚邀各位有志于让本土开源立足全球的伙伴加入 SeaTunnel 贡献者大家庭,一起共建开源! https://github.com/apache/seatunnel/issues https://github.com/apache/seatunnel/pulls dev-subscribe@seatunnel.apache.org https://join.slack.com/t/apacheseatunnel/shared_invite/zt-1kcxzyrxz-lKcF3BAyzHEmpcc4OSaCjQ https://x.com/ASFSeaTunnel