作者 | 梁尧博(本文由AI辅助生成) Apache SeaTunnel
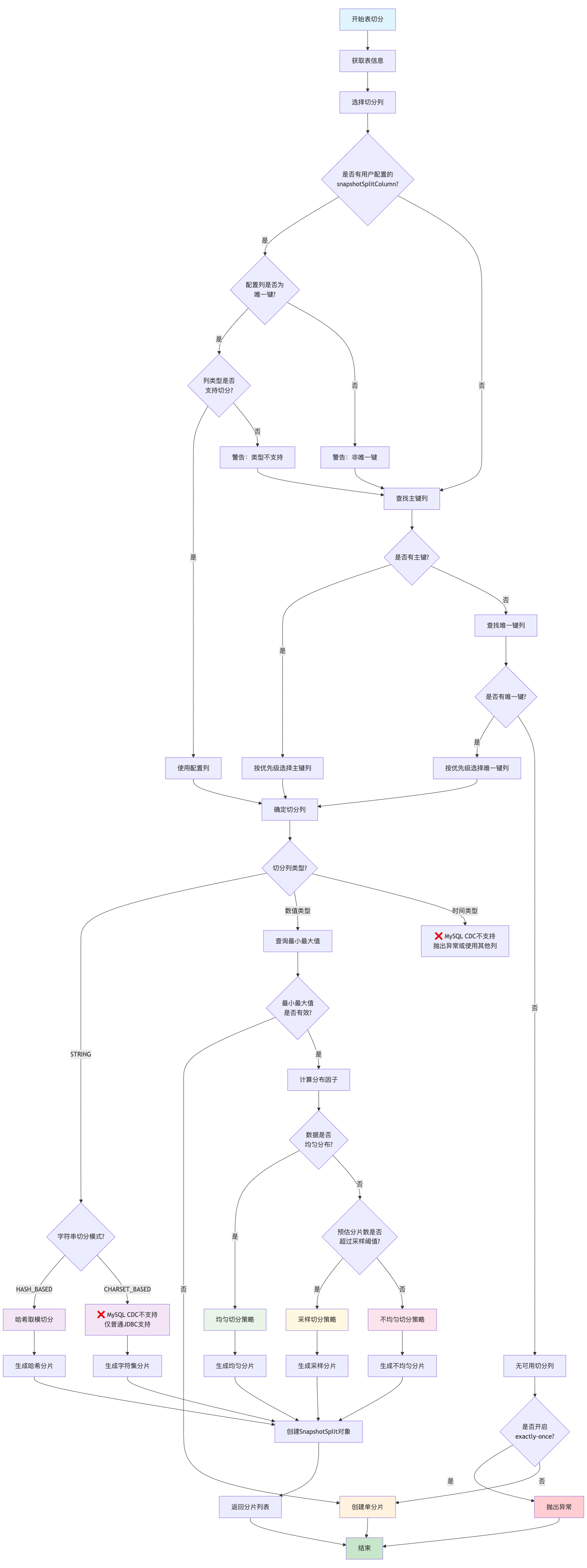
1. 用户配置的snapshotSplitColumn(建议是唯一键)2. 主键列(按数据类型优先级选择)3. 唯一键列(按数据类型优先级选择)4. 无可用列 → 单分片策略 MySQL CDC连接器支持的切分列类型: 根据AbstractJdbcSourceChunkSplitter.isEvenlySplitColumn()方法的实现:
// AbstractJdbcSourceChunkSplitter.isEvenlySplitColumn()switch (fromDbzColumn(splitColumn).getSqlType()) { case TINYINT: case SMALLINT: case INT: case BIGINT: case DECIMAL: case STRING: return true; default: return false;} 支持的类型:
注意:MySQL CDC不支持日期时间类型切分 不支持的类型:
DATE :不支持作为切分列
DATETIME :不支持作为切分列
TIMESTAMP :不支持作为切分列
TIME :不支持作为切分列
对比:普通JDBC连接器的支持情况 值得注意的是,普通JDBC连接器(DynamicChunkSplitter)支持DATE类型切分:
// DynamicChunkSplitter支持的类型switch (splitColumnType.getSqlType()) { case TINYINT: case SMALLINT: case INT: case BIGINT: case DECIMAL: case DOUBLE: case FLOAT: return evenlyColumnSplitChunks(table, splitColumnName, min, max, chunkSize); case STRING: // 字符串切分逻辑 case DATE: // 支持普通JDBC支持DATE类型 return dateColumnSplitChunks(table, splitColumnName, min, max, chunkSize);} 实际影响和解决方案 如果表只有日期时间类型的索引列,MySQL CDC将:
无法找到合适的切分列
回退到单分片模式
失去并行读取的优势
// 优先级:1最高,6最低TINYINT(1) > SMALLINT(2) > INT(3) > BIGINT(4) > DECIMAL(5) > STRING(6) SeaTunnel通过一套精密的决策算法来确定使用哪种切分策略,这个决策过程基于数据分布特征和表大小等因素。
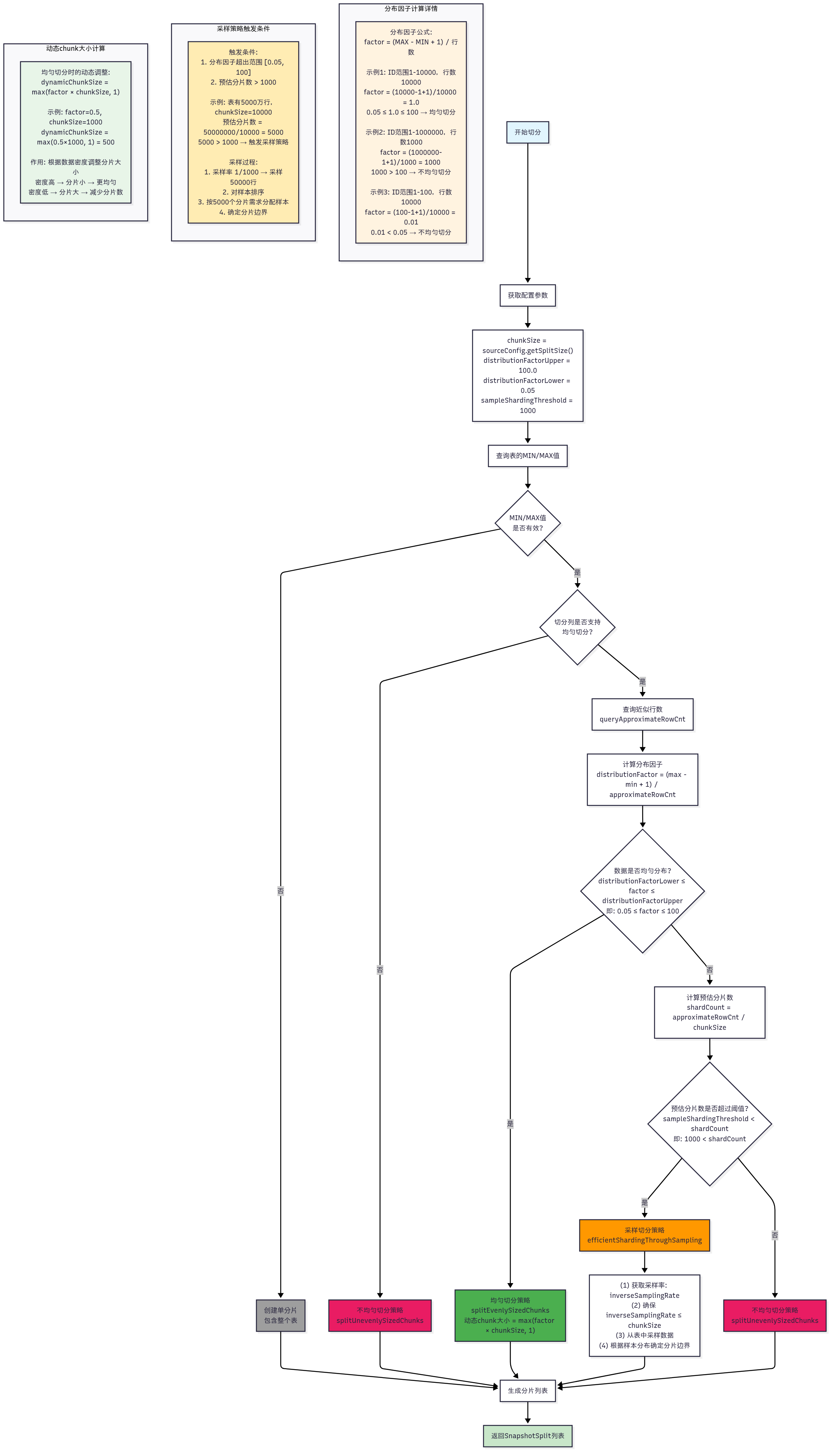
// 核心决策逻辑位于 AbstractJdbcSourceChunkSplitter.generateSplits()public Collection<SnapshotSplit> generateSplits(JdbcConnection jdbc, TableId tableId) { // 1. 获取配置参数 final int chunkSize = sourceConfig.getSplitSize(); // 默认:8096 final double distributionFactorUpper = sourceConfig.getDistributionFactorUpper(); // 默认:100.0 final double distributionFactorLower = sourceConfig.getDistributionFactorLower(); // 默认:0.05 final int sampleShardingThreshold = sourceConfig.getSampleShardingThreshold(); // 默认:1000 // 2. 检查切分列类型 if (isEvenlySplitColumn(splitColumn)) { // 3. 查询近似行数和计算分布因子 long approximateRowCnt = queryApproximateRowCnt(jdbc, tableId); double distributionFactor = calculateDistributionFactor(tableId, min, max, approximateRowCnt); // 4. 判断数据分布是否均匀 boolean dataIsEvenlyDistributed = distributionFactor >= distributionFactorLower && distributionFactor <= distributionFactorUpper; if (dataIsEvenlyDistributed) { // 均匀切分策略 return splitEvenlySizedChunks(...); } else { // 5. 检查是否需要采样策略 int shardCount = (int) (approximateRowCnt / chunkSize); if (sampleShardingThreshold < shardCount) { // 采样切分策略 return efficientShardingThroughSampling(...); } else { // 不均匀切分策略 return splitUnevenlySizedChunks(...); } } } else { // 字符串类型:不均匀切分策略 return splitUnevenlySizedChunks(...); }} 核心公式:
distributionFactor = (MAX - MIN + 1) / approximateRowCount 计算逻辑:
protected double calculateDistributionFactor(TableId tableId, Object min, Object max, long approximateRowCnt) { if (approximateRowCnt == 0) { return Double.MAX_VALUE; // 空表处理 } BigDecimal difference = ObjectUtils.minus(max, min); final BigDecimal subRowCnt = difference.add(BigDecimal.valueOf(1)); double distributionFactor = subRowCnt.divide( new BigDecimal(approximateRowCnt), 4, ROUND_CEILING).doubleValue(); return distributionFactor;} 分布因子含义:
factor ≈ 1.0 :数据分布理想,ID连续且无空隙
factor > 100 :数据稀疏,ID范围远大于行数(如:ID 1-100万,但只有1000行)
factor < 0.05 :数据密集,多行共享相似的ID值(如:时间戳列,同一秒内多条记录)
// 支持均匀切分的数据类型private boolean isEvenlySplitColumn(Column splitColumn) { return splitColumn.isNumeric() || splitColumn.isTemporalType();} boolean dataIsEvenlyDistributed = doubleCompare(distributionFactor, distributionFactorLower) >= 0 && doubleCompare(distributionFactor, distributionFactorUpper) <= 0;// 即:0.05 ≤ distributionFactor ≤ 100 int shardCount = (int) (approximateRowCnt / chunkSize);if (sampleShardingThreshold < shardCount) { // 预估分片数超过1000时,启用采样策略} 表:user_orders切分列:order_id (BIGINT)数据范围:1 - 100,000行数:100,000chunkSize:10,000计算:distributionFactor = (100000 - 1 + 1) / 100000 = 1.0判断:0.05 ≤ 1.0 ≤ 100 → 数据均匀分布结果:使用均匀切分策略,生成10个分片 表:big_transactions切分列:transaction_id (BIGINT)数据范围:1 - 10,000,000行数:50,000chunkSize:1,000计算:distributionFactor = (10000000 - 1 + 1) / 50000 = 200预估分片数 = 50000 / 1000 = 50判断:200 > 100 → 数据分布不均匀 50 < 1000 → 不触发采样结果:使用不均匀切分策略 表:log_events切分列:event_id (BIGINT)数据范围:1 - 1,00,000行数:5,000,000chunkSize:1,000计算:distributionFactor = (100000 - 1 + 1) / 5000000 = 0.2预估分片数 = 5000000 / 1000 = 5000判断:0.02 < 0.05 → 数据分布不均匀 5000 > 1000 → 触发采样策略结果:使用采样切分策略,采样后生成5000个分片 表:sensor_data切分列:timestamp (TIMESTAMP)数据范围:2023-01-01 00:00:00 - 2023-01-01 01:00:00 (3600秒)行数:1,000,000chunkSize:10,000计算:distributionFactor = 3600 / 1000000 = 0.0036判断:0.0036 < 0.05 → 数据分布不均匀 预估分片数 = 1000000 / 10000 = 100 < 1000结果:使用不均匀切分策略 条件组合 分布因子范围 预估分片数 选择策略 适用场景 数值列 + 均匀分布 [0.05, 100] 任意 均匀切分 自增ID,均匀分布的数值 数值列 + 不均匀 + 小表 <0.05 或 >100 ≤1000 不均匀切分 稀疏ID,时间戳密集 数值列 + 不均匀 + 大表 <0.05 或 >100 >1000 采样切分 大表且分布极不均匀 字符串列 不适用 任意 不均匀切分 字符串类型切分列
适用场景: 数据分布均匀的数值列
判断条件:
// 分布因子计算distributionFactor = (max - min + 1) / approximateRowCount// 均匀分布判断distributionFactorLower <= distributionFactor <= distributionFactorUpper// 默认:0.05 <= distributionFactor <= 100 切分逻辑:
// 动态chunk大小计算dynamicChunkSize = Math.max((int)(distributionFactor * chunkSize), 1)// 切分范围计算chunkStart = nullchunkEnd = min + dynamicChunkSizewhile (chunkEnd <= max) { splits.add(ChunkRange.of(chunkStart, chunkEnd)) chunkStart = chunkEnd chunkEnd = chunkEnd + dynamicChunkSize}// 添加最后一个分片splits.add(ChunkRange.of(chunkStart, null)) 示例:
表:user_table,主键:id,范围:1-10000,行数:10000distributionFactor = (10000-1+1)/10000 = 1.0chunkSize = 1000,dynamicChunkSize = 1000分片结果:Split1: [null, 1000] // id <= 1000Split2: [1000, 2000] // 1000 < id <= 2000Split3: [2000, 3000] // 2000 < id <= 3000...Split10: [9000, null] // id > 9000 适用场景: 数据分布不均匀或非数值列
切分逻辑:
// 连续查询下一个chunk的最大值Object chunkStart = nullObject chunkEnd = queryNextChunkMax(jdbc, min, tableId, splitColumn, max, chunkSize)while (chunkEnd != null && chunkEnd <= max) { splits.add(ChunkRange.of(chunkStart, chunkEnd)) chunkStart = chunkEnd chunkEnd = queryNextChunkMax(jdbc, chunkEnd, tableId, splitColumn, max, chunkSize)}splits.add(ChunkRange.of(chunkStart, null)) SQL示例:
-- 查询下一个chunk的最大值SELECT MAX(split_column) FROM ( SELECT split_column FROM table_name WHERE split_column >= ? ORDER BY split_column LIMIT ?) t 示例:
表:order_table,切分列:create_time,chunkSize=1000查询过程:1. 查询前1000行的最大create_time → '2023-01-15 10:30:00'2. 查询接下来1000行的最大create_time → '2023-02-20 15:45:00'3. 继续查询...分片结果:Split1: [null, '2023-01-15 10:30:00']Split2: ['2023-01-15 10:30:00', '2023-02-20 15:45:00']Split3: ['2023-02-20 15:45:00', '2023-03-25 09:20:00']... 适用场景: 大表且数据分布极不均匀
触发条件:
// 当预估分片数超过阈值时启用int shardCount = (int)(approximateRowCount / chunkSize)if (sampleShardingThreshold < shardCount) { // 使用采样切分}// 默认阈值:1000 采样逻辑:
// 采样数据Object[] sampleData = sampleDataFromColumn(jdbc, tableId, splitColumn, inverseSamplingRate)// 计算每个分片的样本数double approxSamplePerShard = (double)sampleData.length / shardCount// 根据样本数据确定分片边界for (int i = 0; i < shardCount; i++) { Object chunkStart = lastEnd Object chunkEnd = (i < shardCount - 1) ? sampleData[(int)((i + 1) * approxSamplePerShard)] : null splits.add(ChunkRange.of(chunkStart, chunkEnd))} 示例:
表:big_table,行数:1000万,chunkSize=10000,预估分片数=1000inverseSamplingRate=1000(采样率1/1000)采样过程:1. 从表中采样10000行数据2. 将采样数据按切分列排序3. 根据1000个分片需求,每10个样本确定一个分片边界分片结果:基于采样数据的分布确定边界 SQL查询类型 对应方法 实现类 具体作用 MIN/MAX查询 queryMinMax()MySqlUtils.java获取切分列的最小最大值 行数统计查询 queryApproximateRowCnt()MySqlUtils.java获取表的近似行数 动态边界查询 queryNextChunkMax()MySqlUtils.java不均匀切分的边界计算 采样数据查询 sampleDataFromColumn()MySqlUtils.java采样策略的数据采集 字符串哈希查询 hashModForField()MysqlDialect.java字符串类型的哈希切分
表结构:
CREATE TABLE user_orders ( order_id BIGINT AUTO_INCREMENT PRIMARY KEY, user_id INT, amount DECIMAL(10,2), created_at TIMESTAMP);-- 数据范围:order_id 1-100000,共100000行 切分过程SQL:
-- 1. 查询MIN/MAX值SELECT MIN(order_id), MAX(order_id) FROM user_orders;-- 结果:MIN=1, MAX=100000-- 2. 查询近似行数(MySQL)SHOW TABLE STATUS LIKE 'user_orders';-- 结果:Rows=100000-- 3. 计算分布因子:(100000-1+1)/100000 = 1.0-- 判断:0.05 ≤ 1.0 ≤ 100 → 均匀切分-- 4. 生成分片SQL(chunkSize=10000)-- Split 0:SELECT * FROM user_orders WHERE order_id >= 1 AND order_id < 10001;-- Split 1:SELECT * FROM user_orders WHERE order_id >= 10001 AND order_id < 20001;-- Split 2:SELECT * FROM user_orders WHERE order_id >= 20001 AND order_id < 30001;-- ...继续到Split 9-- Split 9:SELECT * FROM user_orders WHERE order_id >= 90001 AND order_id <= 100000; 对应代码实现:
public static Object[] queryMinMax(JdbcConnection jdbc, TableId tableId, String columnName) throws SQLException { final String minMaxQuery = String.format( "SELECT MIN(%s), MAX(%s) FROM %s", quote(columnName), quote(columnName), quote(tableId)); return jdbc.queryAndMap( minMaxQuery, rs -> { if (!rs.next()) { throw new SQLException( String.format( "No result returned after running query [%s]", minMaxQuery)); } return rowToArray(rs, 2); });} public static long queryApproximateRowCnt(JdbcConnection jdbc, TableId tableId) throws SQLException { final String useDatabaseStatement = String.format("USE %s;", quote(tableId.catalog())); final String rowCountQuery = String.format("SHOW TABLE STATUS LIKE '%s';", tableId.table()); jdbc.execute(useDatabaseStatement); return jdbc.queryAndMap( rowCountQuery, rs -> { if (!rs.next() || rs.getMetaData().getColumnCount() < 5) { throw new SQLException( String.format( "No result returned after running query [%s]", rowCountQuery)); } return rs.getLong(5); // Rows列 });} // 普通JDBC连接器支持DATE类型切分,CDC模式不支持switch (splitColumnType.getSqlType()) { case DATE: return dateColumnSplitChunks(table, splitColumnName, min, max, chunkSize);} 表结构:
CREATE TABLE daily_reports ( id BIGINT AUTO_INCREMENT PRIMARY KEY, -- 支持 MySQL CDC使用此列切分 report_date DATE, -- 不支持 MySQL CDC不支持此列切分 revenue DECIMAL(15,2), created_at TIMESTAMP); MySQL CDC的实际切分方式:
-- MySQL CDC会使用id列进行切分,而不是report_date-- 1. 查询MIN/MAX值(基于id列)SELECT MIN(id), MAX(id) FROM daily_reports;-- 结果:MIN=1, MAX=365-- 2. 查询近似行数SHOW TABLE STATUS LIKE 'daily_reports';-- 结果:Rows=365-- 3. 计算分布因子(基于id列)-- 分布因子:(365-1+1)/365 = 1-- 判断:1 < 100 → 使用均匀切分-- 4. 生成分片SQL(基于id列)-- Split 0:SELECT * FROM daily_reports WHERE id >= 1 AND id < 92;-- Split 1:SELECT * FROM daily_reports WHERE id >= 92 AND id < 183;-- Split 2:SELECT * FROM daily_reports WHERE id >= 183 AND id < 274;-- Split 3:SELECT * FROM daily_reports WHERE id >= 274 AND id <= 365; 表结构:
CREATE TABLE sparse_transactions ( transaction_id BIGINT PRIMARY KEY, account_id INT, amount DECIMAL(15,2));-- 数据特点:ID范围1-1000000,但只有1000行数据 切分过程SQL:
-- 1. 查询MIN/MAX值SELECT MIN(transaction_id), MAX(transaction_id) FROM sparse_transactions;-- 结果:MIN=1, MAX=1000000-- 2. 查询近似行数SHOW TABLE STATUS LIKE 'sparse_transactions';-- 结果:Rows=1000-- 3. 计算分布因子:(1000000-1+1)/1000 = 1000-- 判断:1000 > 100 → 数据分布不均匀-- 4. 不均匀切分SQL生成(chunkSize=100)-- 动态查询每个分片的边界值-- 查询第1个分片的结束值SELECT MAX(transaction_id) FROM ( SELECT transaction_id FROM sparse_transactions WHERE transaction_id >= 1 ORDER BY transaction_id ASC LIMIT 100) AS T;-- 假设结果:15000-- Split 0:SELECT * FROM sparse_transactionsWHERE transaction_id >= 1 AND transaction_id < 15000;-- 查询第2个分片的结束值SELECT MAX(transaction_id) FROM ( SELECT transaction_id FROM sparse_transactions WHERE transaction_id >= 15000 ORDER BY transaction_id ASC LIMIT 100) AS T;-- 假设结果:35000-- Split 1:SELECT * FROM sparse_transactionsWHERE transaction_id >= 15000 AND transaction_id < 35000;-- 继续此过程直到所有数据被分片 对应代码实现:
public static Object queryNextChunkMax( JdbcConnection jdbc, TableId tableId, String splitColumnName, int chunkSize, Object includedLowerBound) throws SQLException { String quotedColumn = quote(splitColumnName); String query = String.format( "SELECT MAX(%s) FROM (" + "SELECT %s FROM %s WHERE %s >= ? ORDER BY %s ASC LIMIT %s" + ") AS T", quotedColumn, quotedColumn, quote(tableId), quotedColumn, quotedColumn, chunkSize); return jdbc.prepareQueryAndMap( query, ps -> ps.setObject(1, includedLowerBound), rs -> { if (!rs.next()) { throw new SQLException( String.format( "No result returned after running query [%s]", query)); } return rs.getObject(1); });} 重要说明: MySQL CDC连接器仅支持哈希取模 方式切分字符串,而普通JDBC连接器还支持字符集编码 方式。
表结构:
CREATE TABLE customer_profiles ( customer_code VARCHAR(50) PRIMARY KEY, name VARCHAR(100), email VARCHAR(100));-- 数据特点:customer_code为字符串,如 'CUST001', 'CUST002'等 切分过程SQL:
-- 字符串类型使用哈希取模切分-- 1. 查询总行数SHOW TABLE STATUS LIKE 'customer_profiles';-- 结果:假设40000行-- 2. 计算分片数:40000 / 8096 ≈ 5个分片-- 3. 生成哈希取模分片SQL(使用MD5哈希,SeaTunnel默认)-- Split 0:SELECT * FROM customer_profilesWHERE ABS(MD5(customer_code) % 5) = 0;-- Split 1:SELECT * FROM customer_profilesWHERE ABS(MD5(customer_code) % 5) = 1;-- Split 2:SELECT * FROM customer_profilesWHERE ABS(MD5(customer_code) % 5) = 2;-- Split 3:SELECT * FROM customer_profilesWHERE ABS(MD5(customer_code) % 5) = 3;-- Split 4:SELECT * FROM customer_profilesWHERE ABS(MD5(customer_code) % 5) = 4; 注意: 以下内容仅适用于普通JDBC连接器,MySQL CDC不支持此方式。
配置参数:
# 启用字符集编码切分模式(仅普通JDBC)split.string_split_mode = charset_basedsplit.string_split_mode_collate = "0123456789abcdefghijklmnopqrstuvwxyz" public enum StringSplitMode { SAMPLE("sample"), // 默认:采样方式(实际还是哈希) CHARSET_BASED("charset_based"); // 字符集编码方式} 字符集编码算法核心:
// 字符串编码为BigInteger的核心算法public static BigInteger encodeStringToNumericRange( String str, int maxLength, boolean paddingAtEnd, boolean isCaseInsensitive, String orderedCharset, int radix) { // 1. 字符串转换为ASCII索引表示 String asciiString = stringToAsciiString(str, maxLength, paddingAtEnd, isCaseInsensitive, orderedCharset); // 2. 解析为基数数组 int[] baseArray = parseBaseNumber(asciiString); // 3. 转换为BigInteger(类似进制转换) return toDecimal(baseArray, radix);} 字符集编码切分示例:
-- 假设字符集:"0123456789abcdefghijklmnopqrstuvwxyz"(37个字符)-- 字符串"cust001"编码过程:-- 1. 'c'→12, 'u'→30, 's'→28, 't'→29, '0'→0, '0'→0, '1'→1-- 2. BigInteger = 12*37^6 + 30*37^5 + 28*37^4 + 29*37^3 + 0*37^2 + 0*37^1 + 1*37^0-- 3. 按数值范围进行均匀切分-- Split 0: 编码值范围 [0, 50000000000)SELECT * FROM customer_profilesWHERE encode_string_to_bigint(customer_code) >= 0 AND encode_string_to_bigint(customer_code) < 50000000000;-- Split 1: 编码值范围 [50000000000, 100000000000)SELECT * FROM customer_profilesWHERE encode_string_to_bigint(customer_code) >= 50000000000 AND encode_string_to_bigint(customer_code) < 100000000000; 特性 哈希取模切分 字符集编码切分 支持连接器 支持MySQL CDC 不支持MySQL CDC 切分原理 哈希函数+取模 字符串→数值编码→范围切分 数据分布 随机分布(哈希特性) 按字典序分布 性能特点 计算简单,速度快 编码复杂,但支持范围查询 适用场景 数据随机分布需求 需要保持字符串顺序的场景 配置复杂度 简单(无需配置) 复杂(需配置字符集)
实际应用建议:
MySQL CDC场景 :只能使用哈希取模,无其他选择
普通JDBC场景 :
默认使用哈希取模(性能更好)
需要保持字符串顺序时使用字符集编码
字符集编码适合固定格式的字符串(如编号、代码等)
对应代码实现:
default String hashModForField(String fieldName, int mod) { return "ABS(MD5(" + quoteIdentifier(fieldName) + ") % " + mod + ")";} 不同数据库的哈希实现:
@Overridepublic String hashModForField(String nativeType, String fieldName, int mod) { String quoteFieldName = quoteIdentifier(fieldName); if (StringUtils.isNotBlank(nativeType)) { quoteFieldName = convertType(quoteFieldName, nativeType); } return "(ABS(HASHTEXT(" + quoteFieldName + ")) % " + mod + ")";} 表结构:
CREATE TABLE big_log_events ( event_id BIGINT, user_id INT, event_type VARCHAR(50), timestamp TIMESTAMP, INDEX idx_event_id (event_id));-- 数据特点:5000万行,event_id分布不均匀 切分过程SQL:
-- 1. 查询MIN/MAX值SELECT MIN(event_id), MAX(event_id) FROM big_log_events;-- 结果:MIN=1, MAX=1000000-- 2. 查询近似行数SHOW TABLE STATUS LIKE 'big_log_events';-- 结果:Rows=50000000-- 3. 计算分布因子:(1000000-1+1)/50000000 = 0.02-- 预估分片数:50000000/8096 ≈ 6177-- 判断:0.02 < 0.05 且 6177 > 1000 → 触发采样切分-- 4. 采样查询(采样率 1/1000,即inverseSamplingRate=1000)SELECT event_id FROM big_log_eventsWHERE MOD((event_id - (SELECT MIN(event_id) FROM big_log_events)), 1000) = 0ORDER BY event_id;-- 采样约50000行数据-- 5. 根据采样结果计算分片边界-- 假设采样后得到边界值:[1, 15000, 28000, 45000, 67000, ...]-- 6. 生成最终分片SQL-- Split 0:SELECT * FROM big_log_eventsWHERE event_id >= 1 AND event_id < 15000;-- Split 1:SELECT * FROM big_log_eventsWHERE event_id >= 15000 AND event_id < 28000;-- Split 2:SELECT * FROM big_log_eventsWHERE event_id >= 28000 AND event_id < 45000;-- 继续直到所有分片 对应代码实现:
public static Object[] sampleDataFromColumn( JdbcConnection jdbc, TableId tableId, String columnName, int inverseSamplingRate) throws SQLException { final String minQuery = String.format( "SELECT %s FROM %s WHERE MOD((%s - (SELECT MIN(%s) FROM %s)), %s) = 0 ORDER BY %s", quote(columnName), quote(tableId), quote(columnName), quote(columnName), quote(tableId), inverseSamplingRate, quote(columnName)); return jdbc.queryAndMap( minQuery, resultSet -> { List<Object> results = new ArrayList<>(); while (resultSet.next()) { results.add(resultSet.getObject(1)); } return results.toArray(); });} 策略类型 数据类型 SQL查询模式 示例 均匀切分 数值类型 WHERE col >= start AND col < endWHERE order_id >= 1 AND order_id < 10001均匀切分 字符串 哈希取模查询 WHERE ABS(CRC32(name) % 4) = 0不均匀切分 数值类型 动态边界查询 SELECT MAX(id) FROM (SELECT id FROM table WHERE id >= ? ORDER BY id LIMIT ?)不均匀切分 字符串 哈希取模查询 WHERE ABS(MD5(name) % 4) = 0采样切分 数值类型 采样+边界查询 WHERE MOD((id - (SELECT MIN(id) FROM table)), 1000) = 0采样切分 字符串 字符串采样查询 WHERE ABS(CRC32(name) % 1000) = 0
数据库 哈希函数 行数统计 分页语法 MySQL MD5(field)SHOW TABLE STATUSLIMIT nPostgreSQL HASHTEXT(field)pg_class.reltuplesLIMIT nSQL Server HASHBYTES('MD5', field)sys.dm_db_partition_statsTOP nOracle ORA_HASH(field)all_tables.num_rowsROWNUM <= n
# 分布因子配置chunk-key.even-distribution.factor.upper-bound = 100.0 # 上限,默认100.0chunk-key.even-distribution.factor.lower-bound = 0.05 # 下限,默认0.05 参数说明:
# 采样配置sample-sharding.threshold = 1000 # 采样阈值,默认1000inverse-sampling.rate = 1000 # 采样率倒数,默认1000 参数说明:
# 快照切分配置snapshot.split.size = 8096 # 分片大小,默认8096行snapshot.fetch.size = 1024 # 每次拉取大小,默认1024行 参数说明:
参数名 类型 默认值 说明 snapshot.split.sizeInteger 8096 表快照的分片大小(行数) snapshot.fetch.sizeInteger 1024 读取快照时每次拉取的最大行数 chunk-key.even-distribution.factor.upper-boundDouble 100.0 均匀分布因子上限 chunk-key.even-distribution.factor.lower-boundDouble 0.05 均匀分布因子下限 sample-sharding.thresholdInteger 1000 采样切分阈值 inverse-sampling.rateInteger 1000 采样率倒数 server-idString 随机生成 数据库客户端的唯一ID server-time-zoneString UTC 数据库服务器的会话时区 connect.timeout.msDuration 30000 连接超时时间(毫秒) connect.max-retriesInteger 3 最大重试次数 connection.pool.sizeInteger 20 JDBC连接池大小
source { Mysql-CDC { # 基础连接配置 url = "jdbc:mysql://localhost:3306/test" username = "root" password = "123456" table-names = ["test.user_table"] # 快照切分配置 snapshot.split.size = 8096 snapshot.fetch.size = 1024 # 分布因子配置 chunk-key.even-distribution.factor.upper-bound = 100.0 chunk-key.even-distribution.factor.lower-bound = 0.05 # 采样策略配置 sample-sharding.threshold = 1000 inverse-sampling.rate = 1000 # 连接配置 server-id = "5400" server-time-zone = "Asia/Shanghai" connect.timeout.ms = 30000 connect.max-retries = 3 connection.pool.size = 20 # 启动模式 startup.mode = "initial" # 其他配置 exactly_once = false format = "DEFAULT" }} 通过调整关键参数,可以精确控制SeaTunnel使用哪种切分策略,以应对不同的现场场景:
1. 强制使用均匀切分策略 适用场景: 数据分布相对均匀,追求最佳并行性能
source { Mysql-CDC { url = "jdbc:mysql://localhost:3306/test" username = "root" password = "123456" table-names = ["test.uniform_table"] # 强制均匀切分配置 chunk-key.even-distribution.factor.upper-bound = 10000.0 # 大幅提高上限 chunk-key.even-distribution.factor.lower-bound = 0.001 # 大幅降低下限 sample-sharding.threshold = 100000 # 极高阈值避免采样 snapshot.split.size = 8096 # 标准分片大小 }} 2. 强制使用不均匀切分策略 适用场景: 数据分布不均,但表不是特别大
source { Mysql-CDC { url = "jdbc:mysql://localhost:3306/test" username = "root" password = "123456" table-names = ["test.sparse_table"] # 强制不均匀切分配置 chunk-key.even-distribution.factor.upper-bound = 0.1 # 极低上限 chunk-key.even-distribution.factor.lower-bound = 0.1 # 极低下限 sample-sharding.threshold = 100000 # 极高阈值避免采样 snapshot.split.size = 5000 # 适中分片大小 }} 3. 强制使用采样切分策略 适用场景: 超大表,需要高效切分
source { Mysql-CDC { url = "jdbc:mysql://localhost:3306/test" username = "root" password = "123456" table-names = ["test.huge_table"] # 强制采样切分配置 chunk-key.even-distribution.factor.upper-bound = 0.01 # 极低上限 chunk-key.even-distribution.factor.lower-bound = 0.01 # 极低下限 sample-sharding.threshold = 100 # 极低阈值强制采样 inverse-sampling.rate = 500 # 提高采样率 snapshot.split.size = 10000 # 较大分片大小 }} 4. 避免采样策略(业务库压力大) 适用场景: 大表但业务库压力大,不能使用采样
source { Mysql-CDC { url = "jdbc:mysql://localhost:3306/test" username = "root" password = "123456" table-names = ["test.large_table"] # 避免采样配置 chunk-key.even-distribution.factor.upper-bound = 1000.0 # 放宽上限 chunk-key.even-distribution.factor.lower-bound = 0.001 # 放宽下限 sample-sharding.threshold = 50000 # 极高阈值 snapshot.split.size = 50000 # 大分片减少总数 connection.pool.size = 5 # 减少连接数 snapshot.fetch.size = 1024 # 控制拉取大小 }} 5. 高并行性能优化 适用场景: 追求最大并行度和处理速度
source { Mysql-CDC { url = "jdbc:mysql://localhost:3306/test" username = "root" password = "123456" table-names = ["test.performance_table"] # 高并行配置 snapshot.split.size = 2000 # 小分片增加并行度 snapshot.fetch.size = 2048 # 增加拉取大小 connection.pool.size = 30 # 增加连接池 chunk-key.even-distribution.factor.upper-bound = 1000.0 # 优先均匀切分 sample-sharding.threshold = 10000 # 适中阈值 }} 场景类型 分片大小 上限因子 下限因子 采样阈值 策略结果 数据均匀,追求性能 2000-8096 10000.0 0.001 100000 均匀切分 数据稀疏,中等表 5000-10000 0.1 0.1 100000 不均匀切分 超大表,允许采样 10000+ 0.01 0.01 100 采样切分 大表,业务库压力大 50000+ 1000.0 0.001 50000 避免采样 高并行需求 2000 1000.0 0.001 10000 均匀切分
策略选择控制: chunk-key.even-distribution.factor.upper-bound: 控制是否使用均匀切分
chunk-key.even-distribution.factor.lower-bound: 控制分布判断的敏感度
sample-sharding.threshold: 控制是否触发采样策略
性能调优控制: snapshot.split.size: 控制并行度和内存使用
snapshot.fetch.size: 控制数据库查询压力
connection.pool.size: 控制数据库连接压力
inverse-sampling.rate: 控制采样精度
SeaTunnel MySQL CDC连接器的表切分机制通过以下核心组件实现:
AbstractJdbcSourceChunkSplitter :核心切分逻辑
MySqlUtils :MySQL特定的SQL查询实现
JdbcDialect :数据库方言支持
三种切分策略:
均匀切分 :适用于数据分布均匀的数值和日期类型
不均匀切分 :适用于数据分布稀疏的场景
采样切分 :适用于超大表的高效切分
决策机制:
通过分布因子判断数据分布特征
根据表大小选择合适的切分策略
支持多种数据类型的特殊处理
通过精确的参数控制,这套机制能够应对各种复杂的现场场景,确保MySQL CDC在处理各种规模和类型的表时都能实现高效、均衡的数据切分。