作者 | chl-wxp
不久前,社区发布了一篇题为《告别手敲 Schema!SeaTunnel 集成 Gravitino 元数据 RestApi 这个新动作有点酷》的文章,引起了小伙伴们的强烈反响,纷纷表示这真是个好东西啊!
Apache SeaTunnel Gravitino 元数据 RestApi 的贡献者行动力也超强,估计不久就能跟大家见面了(“可靠”消息,预计将在 3.0.0 版本得到支持)。为了让大家更加了解这个功能,贡献者还贴心地为社区小伙伴们写了一篇详细的文章,介绍了初版 Gravitino RestApi 的能力以及如何使用它,快来一睹为快吧!在使用 Apache SeaTunnel 进行批处理或同步任务时,当source是非结构化或者半结构化的类型时,Source 侧通常需要显式定义 schema(字段名、类型、顺序)。
在真实生产环境中,这会带来几个典型问题:
- 表结构字段多、类型复杂,手工维护 schema 成本高且易出错
- 上游表结构发生变更(加字段、改类型)时,需要同步修改 SeaTunnel 作业
- 对于已有存量表,仅为了同步数据却需要重复描述元数据,存在明显冗余
因此,核心诉求是:
能否让 SeaTunnel 直接复用已有元数据系统中的表结构定义,而不是在作业中重复声明 schema?
本功能正是为了解决这一问题而引入。
2. Gravitino 能力简介
(与本功能相关部分)
Gravitino 是一个统一的元数据管理与访问服务,提供了标准化的 REST API,用于管理和暴露以下对象:
- Catalog(如 MySQL、Hive、Iceberg 等)
通过 Gravitino:
- 下游系统可以通过 HTTP API 动态获取表的 schema 定义
本次在 SeaTunnel 中引入的能力,正是:
支持在 Source 的 schema 定义中,通过 Gravitino 提供的 schema_url 自动拉取表结构
3.1 准备mysql环境
3.1.1 创建目标表
MySQL 中提前创建好目标表 test.demo_user,建表语句如下:
CREATE TABLE `demo_user` ( `id` bigint unsigned NOT NULL AUTO_INCREMENT, `user_code` varchar(32) NOT NULL, `user_name` varchar(64) DEFAULT NULL, `password` varchar(128) DEFAULT NULL, `email` varchar(128) DEFAULT NULL, `phone` varchar(20) DEFAULT NULL, `gender` tinyint DEFAULT NULL, `age` int DEFAULT NULL, `status` tinyint DEFAULT NULL, `level` int DEFAULT NULL, `score` decimal(10,2) DEFAULT NULL, `balance` decimal(12,2) DEFAULT NULL, `is_deleted` tinyint DEFAULT NULL, `register_ip` varchar(45) DEFAULT NULL, `last_login_ip` varchar(45) DEFAULT NULL, `login_count` int DEFAULT NULL, `remark` varchar(255) DEFAULT NULL, `ext1` varchar(100) DEFAULT NULL, `ext2` varchar(100) DEFAULT NULL, `ext3` varchar(100) DEFAULT NULL, `ext4` varchar(100) DEFAULT NULL, `ext5` varchar(100) DEFAULT NULL, `created_by` varchar(64) DEFAULT NULL, `updated_by` varchar(64) DEFAULT NULL, `created_time` datetime DEFAULT NULL, `updated_time` datetime DEFAULT NULL, `birthday` date DEFAULT NULL, `last_login_time` datetime DEFAULT NULL, `version` int DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `uk_user_code` (`user_code`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
3.1.2 创建要同步的表结构
在实际应用中,我们把表结构统一管理起来,可能管理在paimon,hive,hudi等元数据组件中,但在这里为了方便,测试用的表结构信息指向测试的目标表,也就是上一个步骤创建的test.demo_user表
3.2 注册该表结构到Gravitino中
Gravitino支持直连数据库,并会扫描库下所有表
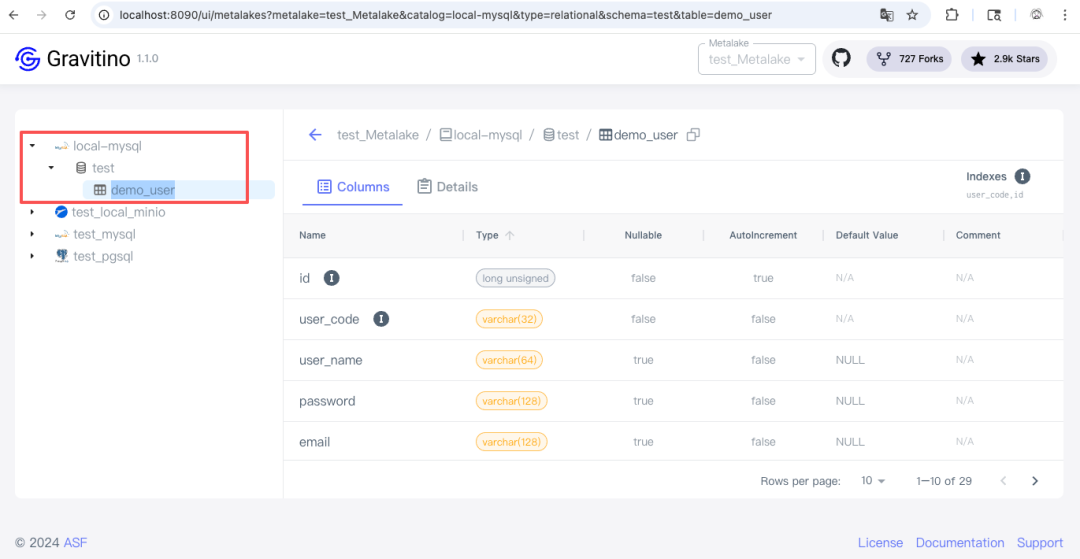
该表已经作为 local-mysql catalog 下的一个 table 被 Gravitino 管理。
Metalake:test_Metalake
3.3 表结构访问关系说明
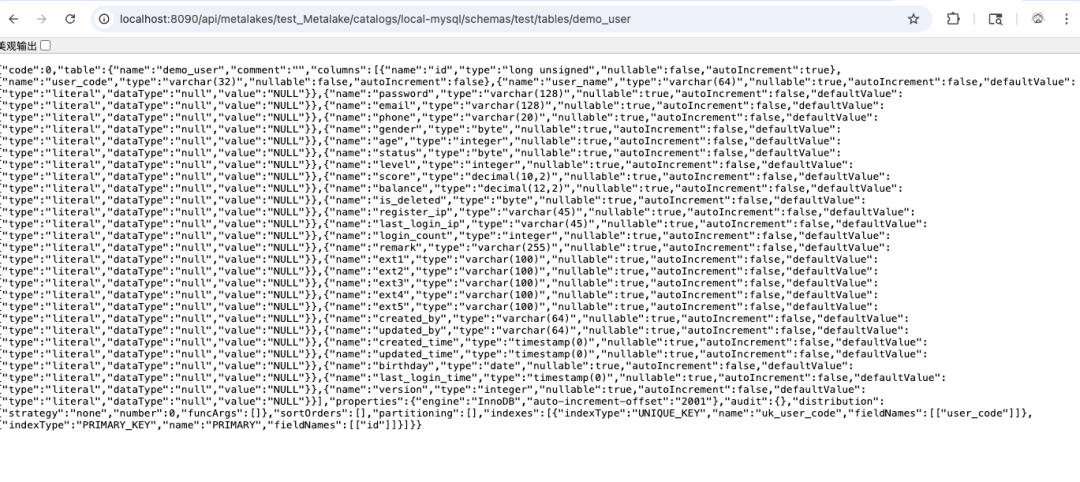
Gravitino 中表结构可以通过如下 REST API 访问:
http://localhost:8090/api/metalakes/test_Metalake/catalogs/${catalog}/schemas/${schema}/tables/${table}
在本次测试中,实际使用的 schema_url 为:
http://localhost:8090/api/metalakes/test_Metalake/catalogs/local-mysql/schemas/test/tables/demo_user
该接口返回的 JSON 中,包含了 demo_user 表的完整字段定义。
3.4 本地部署seatunnel
由于该功能还并未发版,需要手动编译最新的seatunnel的dev分支代码,并部署到本地。
3.5 准备数据文件
本次测试用例是csv作为数据文件,总共是2000条数据。
4.1 核心配置示例
env { parallelism = 1 job.mode = "BATCH"}source { LocalFile { path = "/Users/wangxuepeng/Desktop/seatunnel/apache-seatunnel-2.3.13-SNAPSHOT/test_data" file_format_type = "csv" schema { schema_url = "http://localhost:8090/api/metalakes/test_Metalake/catalogs/local-mysql/schemas/test/tables/demo_user" } }}sink { jdbc { url = "jdbc:mysql://localhost:3306/test" driver = "com.mysql.cj.jdbc.Driver" username = "root" password = "123456" database = "test" table = "demo_user" generate_sink_sql = true }}
4.2 配置要点说明
schema.schema_url
- 指向 Gravitino 中的表元数据 REST 接口
generate_sink_sql = true
- Sink 侧根据解析后的 schema 自动生成 INSERT SQL
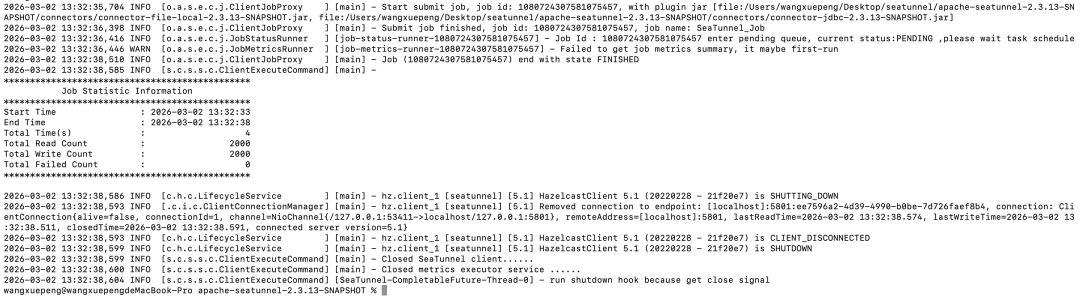
日志截图 :
数据库截图:
任务运行过程中:
- Source 根据 schema_url 自动解析字段结构
6.1 功能支持的范围
该功能在dev分支目前是已经支持文件类型的连接器,包括local,hdfs,s3等。
6.2 使用schema_url是否支持多表
改功能的引入并不影响多表的功能,甚至可以混合使用,比如:
source { LocalFile { tables_configs = [ { path = "/seatunnel/read/metalake/table1" file_format_type = "csv" field_delimiter = "," row_delimiter = "\n" skip_header_row_number = 1 schema { table = "db.table1" fields { c_string = string c_int = int c_boolean = boolean c_double = double } } }, { path = "/seatunnel/read/metalake/table2" file_format_type = "csv" field_delimiter = "," row_delimiter = "\n" skip_header_row_number = 1 schema { table = "db.table2" schema_url = "http://gravitino:8090/api/metalakes/test_metalake/catalogs/test_catalog/schemas/test_schema/tables/table2" } } ] }}
通过引入 基于 Gravitino schema_url 的 schema 自动解析能力,SeaTunnel 在数据同步场景中具备了以下优势:
该能力非常适合:
Apache SeaTunnel
Apache SeaTunnel是一个云原生的多模态、高性能海量数据集成工具。北京时间 2023 年 6 月1 日,全球最大的开源软件基金会ApacheSoftware Foundation正式宣布SeaTunnel毕业成为Apache顶级项目。目前,SeaTunnel在GitHub上Star数量已达9.1k+,社区达到7000+人规模。SeaTunnel支持在云数据库、本地数据源、SaaS、大模型等170多种数据源之间进行数据实时和批量同步,支持CDC、DDL变更、整库同步等功能,更是可以和大模型打通,让大模型链接企业内部的数据。
https://github.com/apache/seatunnelhttps://seatunnel.apache.org/https://seatunnel.apache.org/download我们相信,在「Community Over Code」(社区大于代码)、「Open and Cooperation」(开放协作)、「Meritocracy」(精英管理)、以及「多样性与共识决策」等 The Apache Way 的指引下,我们将迎来更加多元化和包容的社区生态,共建开源精神带来的技术进步!我们诚邀各位有志于让本土开源立足全球的伙伴加入 SeaTunnel 贡献者大家庭,一起共建开源!https://github.com/apache/seatunnel/issueshttps://github.com/apache/seatunnel/pullsdev-subscribe@seatunnel.apache.orghttps://join.slack.com/t/apacheseatunnel/shared_invite/zt-1kcxzyrxz-lKcF3BAyzHEmpcc4OSaCjQhttps://x.com/ASFSeaTunnel