https://github.com/apache/SeaTunnel
Apache SeaTunnel 社区正式发布 2.3.13 版本 !本次发版对于 Apache SeaTunnel 来说是一个里程碑式的进展,带来了诸如 Checkpoint API、Flink 引擎升级、大文件并行处理、多表同步能力、AI Embedding Transform、更加丰富的连接器扩展 等多项重要能力。无论是批量数据处理还是实时 CDC,同步到 Lakehouse,SeaTunnel 都能更高效、更稳定、更智能地支持你的数据集成工作。
感谢 50+ 社区贡献者 的辛勤付出,本次版本包含 100+ PR 的功能新增、优化与 Bug 修复。如果你正在构建 数据仓库、实时同步平台或 AI 数据管道 ,这个版本的更新值得关注。
没有时间细读完整 Release Notes?没关系,下面整理了 本次版本最值得关注的 10 个更新 ,并标注了对应的 PR,供大家参考。
完整版 Release Note: https://github.com/apache/seatunnel/releases/tag/2.3.13 01 新增Checkpoint API,
任务容错能力进一步增强
在数据同步任务中,Checkpoint 是保证任务可靠性的核心机制之一。SeaTunnel 2.3.13 新增 Checkpoint API ( #10065 ),让任务状态管理更加灵活,也为后续调度系统和运维能力提供了更好的扩展基础。Zeta 引擎支持 Checkpoint 最小间隔 min-pause 配置 ( #9804 ),可以避免频繁 checkpoint 带来的系统压力。
监控能力也得到加强,例如新增 Sink 提交指标并计算 commit rate( #10233 ),同时在任务概览接口中返回 PendingJobs 信息( #9902 ),并提供查看 Pending 队列的 REST API( #10078 )。
这些能力可以帮助用户更好地理解任务执行状态并优化 checkpoint 策略。
02 支持Flink 1.20.1并增强CDC能力
在引擎生态方面,本版本增强了对 Apache Flink 的支持。SeaTunnel 现在已经支持 Flink 1.20.1 ( #9576 ),同时 CDC 同步能力也得到提升,例如 CDC Source 支持 Schema Evolution ( #9867 ),可以在源表结构变化时自动适配同步任务。
此外 NO_CDC Source 也支持 checkpoint( #10094 ),提升了任务恢复能力。这些改进让 SeaTunnel 在数据库结构变更频繁的场景下更加稳定。
在实际数据平台中,大量数据往往以文件形式存在,例如 HDFS、对象存储或本地文件系统。
本次版本对文件处理性能进行了明显优化。HDFS File Connector 支持真正的大文件并行切分( #10332 ),LocalFile Connector 支持 CSV、Text、JSON 大文件并行读取( #10142 ),Parquet 文件也支持 Logical Split( #10239 )。
此外 HDFS File 还支持多表读取能力( #9816 )。这些能力可以显著提升 TB 级文件处理场景中的读取吞吐量。
04 File Connector新增
Update同步模式
在文件同步场景中,过去往往只能通过追加或覆盖方式写入数据。本版本中多个文件类连接器新增 sync_mode=update 模式支持,包括 FTP、SFTP 和 LocalFile Source( #10437 ),HdfsFile Source 也新增同样能力( #10268 )。这意味着文件同步任务可以支持更新语义,从而更好地适应增量数据处理场景。
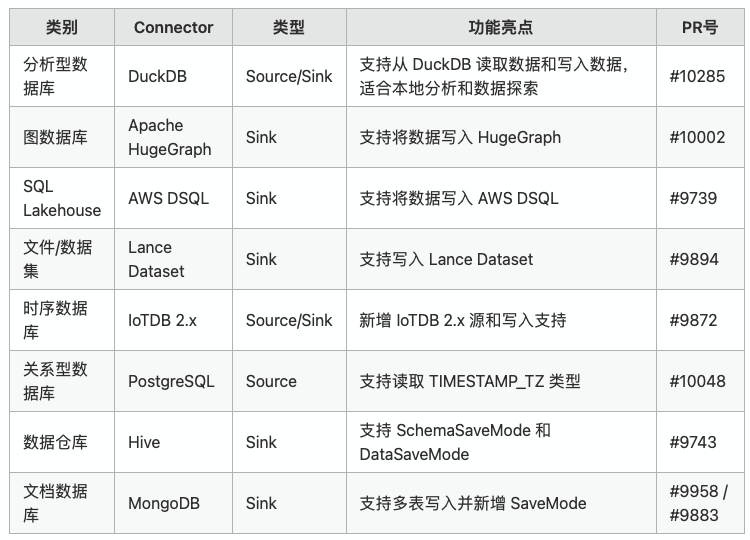
SeaTunnel 2.3.13 在连接器生态上继续扩展和增强。在分析型数据库方面,新增 DuckDB Source 与 Sink 支持( #10285 ),适合本地分析和数据探索。
本版本还新增或增强了多个数据库和 Lakehouse 连接器,包括 Apache HugeGraph Sink( #10002 )、AWS DSQL Sink( #9739 )、Lance Dataset Sink( #9894 )、IoTDB 2.x Source 与 Sink( #9872 )。
同时多个已有连接器能力得到提升,例如 PostgreSQL 支持 TIMESTAMP_TZ 类型( #10048 )、Hive Sink 支持 SchemaSaveMode 与 DataSaveMode( #9743 )、MongoDB Sink 支持多表写入并新增 SaveMode( #9958 / #9883 )。
这些更新显著提升了 SeaTunnel 在数据库与 Lakehouse 场景的适配能力和数据管道构建效率。
06 Kafka支持Protobuf
Schema Registry
在实时数据处理场景中,Kafka 通常与 Schema Registry 结合使用。本版本中 Kafka Connector 新增 Protobuf Schema Registry Wire Format 支持 ( #10183 ),使 SeaTunnel 能够直接解析通过 Schema Registry 管理的 Protobuf 数据格式,从而更方便地构建实时数据管道。
07 新增AI Embedding Transform
随着 AI 与数据工程的融合,越来越多企业需要构建向量数据管道。
SeaTunnel 在 Transform 组件中新增 Multimodal Embedding Transform ( #9673 ),可以在数据管道中直接生成向量数据,用于向量数据库、RAG 系统以及 AI 检索应用。同时新增 RegexExtract Transform ( #9829 ),进一步增强数据清洗能力。
08 新增Markdown Parser
支持RAG场景
在 AI 数据准备场景中,Markdown 文档是一类常见数据源。本版本新增 Markdown Parser ( #9760 ),并补充了相关文档( #9834 ),用于支持 Markdown 文档解析与结构化处理。这一能力可以帮助用户更方便地构建 RAG 数据管道。
除了新功能,本版本还进行了大量稳定性优化。例如:
ClickHouse Connector 优化并行读取策略( #9801 ) MySQL Connector 优化分片计算策略( #9975 ) 同时,本版本还修复了大量生产环境问题,例如:
ClickHouse Connector ThreadLocal 内存泄漏( #10264 ) 这些修复进一步提升了系统在复杂生产环境中的稳定性。
本次版本修复了以往版本的遗留问题,包括
修复了 CDC Snapshot Split 空指针 ( #10404 ) ClickHouse Connector 内存泄漏 ( #10264 ) Elasticsearch Sink 任务无法退出 ( #10038 ) 及其他多个 Connector、Transform、Engine、UI、CI 相关问题 ( #10422 , #10013 等。 在文档与开发者体验方面,本版本进行了系统性完善,包括:
新增 SeaTunnel MCP 与 x2SeaTunnel 文档 ( #10108 ) 完善后的版本可帮助新用户快速上手,开发者更易理解架构与能力。
特别感谢本次发版经理 @xiaochen-zhou 的全力支持,使本次版本得以快速规划与高效执行。同时,感谢所有志愿者的辛勤付出与支持,正是有了你们,SeaTunnel 社区才能不断发展壮大!
Adam Wang, AzkabanWarden.Gf, Bo Schuster, cloud456, CloverDew, corgy-w, CosmosNi, Cyanty, David Zollo, dotfive-star, dy102, dyp12, Frui Guo, Jarvis, Jast, Jeremy, JeremyXin, Jia Fan, Joonseo Lee, krutoileshii, 老王, Leon Yoah, Li Dongxu, LiJie20190102, limin, LimJiaWenBrenda, liucongjy, loupipalien, mengxpgogogo-eng, misi, 巧克力黑, shfshihuafeng, silenceland, Sim Chou, Steven Zhao, wanmingshi, wtybxqm, yzeng1618, zhan7236, zhangdonghao, zhuxt2015, zy
下载地址:https://seatunnel.apache.org/download 版本升级指南:https://seatunnel.apache.org/docs/upgrade-guide Note:升级建议
如果你当前使用的是 Apache SeaTunnel 2.3.x 版本 ,升级到 2.3.13 通常是安全的,因为该版本主要是功能增强与稳定性优化。建议在升级前先备份配置文件并在测试环境验证任务运行情况。对于使用 Checkpoint 的任务,建议在升级前停止任务并确认状态一致性,避免在升级过程中产生状态兼容问题。
同时建议关注连接器配置参数的变化,例如 Hive、MongoDB、Kafka 等连接器在本版本中新增了一些配置选项。
如果你正在使用 Flink 引擎,也可以考虑同步升级到 Flink 1.20.x,以获得更好的兼容性与 CDC 能力。
Apache SeaTunnel Apache SeaTunnel是一个云原生的多模态、高性能海量数据集成工具。北京时间 2023 年 6 月1 日,全球最大的开源软件基金会ApacheSoftware Foundation正式宣布SeaTunnel毕业成为Apache顶级项目。目前,SeaTunnel在GitHub上Star数量已达9.1k+,社区达到7000+人规模。SeaTunnel支持在云数据库、本地数据源、SaaS、大模型等170多种数据源之间进行数据实时和批量同步,支持CDC、DDL变更、整库同步等功能,更是可以和大模型打通,让大模型链接企业内部的数据。
https://github.com/apache/seatunnel https://seatunnel.apache.org/ https://seatunnel.apache.org/download 我们相信,在 「 Community Over Code 」 (社区大于代码)、 「Open and Cooperation」 (开放协作)、 「Meritocracy」 (精英管理)、以及「 多样性与共识决策」 等 The Apache Way 的指引下,我们将迎来更加多元化和包容的社区生态,共建开源精神带来的技术进步! 我们诚邀各位有志于让本土开源立足全球的伙伴加入 SeaTunnel 贡献者大家庭,一起共建开源! https://github.com/apache/seatunnel/issues https://github.com/apache/seatunnel/pulls dev-subscribe@seatunnel.apache.org https://join.slack.com/t/apacheseatunnel/shared_invite/zt-1kcxzyrxz-lKcF3BAyzHEmpcc4OSaCjQ https://x.com/ASFSeaTunnel