在数据平台不断演进的今天,调度系统早已不只是“定时跑任务”的工具,而是承载复杂依赖与稳定性的核心中枢。《深入理解 Apache :从调度原理到 实战》系列专栏,尝试从真实工程场景出发,拆解调度背后的关键设计。本文作为第四篇,将聚焦 Apache DolphinScheduler 的状态机机制,带你看清调度系统如何在充满不确定性的环境中,依然保持有序与可靠。
在所有调度系统的核心机制中,真正决定“是否可靠”的,从来都不是 UI、线程池或分布式框架,而是状态机。只要系统需要跨节点执行、允许失败、支持重试、支持人工干预并在异常后自动恢复,它就必须围绕状态流转来设计。深入理解这一点,才能真正理解调度系统的复杂性。
在 Apache DolphinScheduler 中,TaskInstance 与 WorkflowInstance 并不是简单的执行对象,而是两个嵌套的状态机。调度系统的运行,本质上不是“执行任务”,而是“推动状态向前演进”。
调度系统与普通程序最大的区别在于,它的执行过程具有长生命周期与不确定性。一个任务可能运行数小时,中间可能经历 Worker 宕机、Master 切换、网络抖动、数据库短暂不可用,甚至人工终止或暂停。若系统只依赖内存中的执行上下文,一旦进程崩溃,所有信息都会丢失。
因此,调度系统必须将“当前进展”外化为持久化状态。数据库中的状态字段,才是真正的执行依据。Master 重启后不会“记住”正在执行什么,但它可以重新扫描数据库,根据状态判断哪些任务需要重新调度、哪些已经结束、哪些需要容错恢复。
这就是状态机思想:执行逻辑不依赖内存,而依赖可持久化的状态流转。
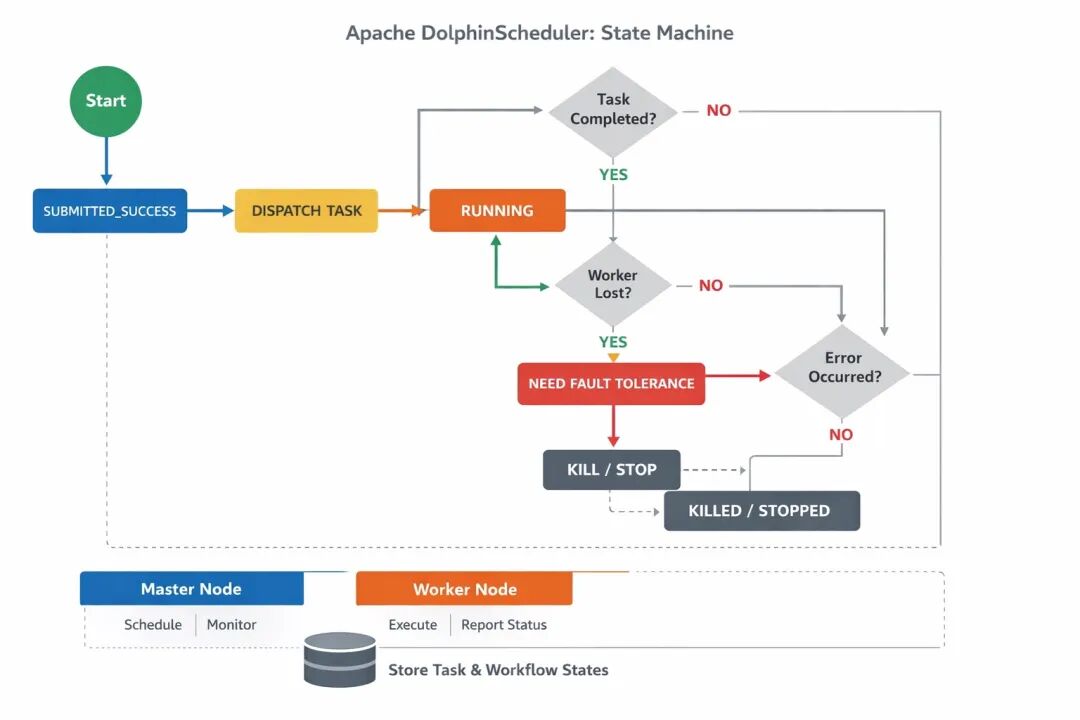
在 DolphinScheduler 中,TaskExecutionStatus 的设计并不是简单的成功或失败。一个任务从创建到结束,通常会经历如下过程:
public enum TaskExecutionStatus { SUBMITTED_SUCCESS, DISPATCH, RUNNING, SUCCESS, FAILURE, NEED_FAULT_TOLERANCE, KILL, KILL_SUCCESS, PAUSE, STOP, WAITING_THREAD, DELAY_EXECUTION}一个最基本的成功路径是:
SUBMITTED_SUCCESS → DISPATCH → RUNNING → SUCCESS
但这只是理想路径。在分布式环境中,更常见的是包含容错分支的路径。例如,当 Worker 丢失或执行异常时:
RUNNING → NEED_FAULT_TOLERANCE → SUBMITTED_SUCCESS → DISPATCH → RUNNING
这条路径意味着任务进入容错状态后被重新提交,而不是简单标记为失败。状态本身定义了系统下一步该做什么。
在 Master 侧,调度逻辑本质是状态驱动的:
public void submitTask(TaskInstance taskInstance) { if (taskInstance.getState() == TaskExecutionStatus.SUBMITTED_SUCCESS) { dispatchToWorker(taskInstance); taskInstance.setState(TaskExecutionStatus.DISPATCH); updateTaskState(taskInstance); }}
Worker 执行任务时,同样通过状态变更来表达进度:
public void executeTask(TaskInstance taskInstance) { taskInstance.setState(TaskExecutionStatus.RUNNING); updateTaskState(taskInstance); try { runTaskLogic(taskInstance); taskInstance.setState(TaskExecutionStatus.SUCCESS); } catch (Exception e) { taskInstance.setState(TaskExecutionStatus.FAILURE); } updateTaskState(taskInstance);}关键点不在于执行逻辑本身,而在于每一次状态变更都必须持久化。数据库中的状态,是整个系统的唯一事实来源。
如果说 TaskInstance 是原子状态机,那么 WorkflowInstance 是聚合状态机。Workflow 的状态并不是独立存在的,它本质上是所有子任务状态的函数。
一个 Workflow 在运行过程中,Master 会不断扫描当前 DAG,寻找依赖满足的任务并提交执行。与此同时,它也会根据任务状态更新自身状态:
private void updateWorkflowStatus() { if (allTasksSuccess()) { workflowInstance.setState(SUCCESS); } else if (anyTaskFailureWithoutRetry()) { workflowInstance.setState(FAILURE); }}这里的核心思想是:Workflow 不主动“执行”,它只是根据 Task 状态的变化进行状态推进。状态变化才是驱动调度循环的真正事件源。
DolphinScheduler 状态
机的工作原理
从整体架构看,DolphinScheduler 的状态机运行机制可以抽象为三层协作:数据库、Master、Worker。
数据库负责持久化所有 WorkflowInstance 和 TaskInstance 的状态字段;Worker 负责执行具体任务并汇报状态;Master 则作为状态推进器,根据数据库中的状态变化做出下一步决策。
当 Master 启动时,它不会依赖内存快照,而是执行类似如下的恢复逻辑:
ublic void recover() { List<WorkflowInstance> runningWorkflows = workflowDao.findRunning(); for (WorkflowInstance wf : runningWorkflows) { rebuildWorkflowContext(wf); scheduleWorkflow(wf); }}
对于处于 RUNNING 但长时间无心跳的任务,Master 会进行超时检测:
if (taskInstance.getState() == RUNNING && timeout(taskInstance)) { taskInstance.setState(NEED_FAULT_TOLERANCE); updateTaskState(taskInstance);}之后,状态重新进入可调度阶段。也就是说,Master 本身并不保存复杂执行逻辑,它只是在不断读取状态、判断条件、推进状态。
这是一种 “数据库驱动调度” 的模式。系统的健壮性来源于状态可重建,而不是节点稳定。
在生产环境中,“任务卡住”是最常见的抱怨之一。但如果从状态机角度观察,所谓“卡住”,往往是系统在做保守决策。
例如,一个任务处于 RUNNING 状态,但 Worker 已失联。此时系统面临选择:立即判定失败并重试,还是等待更长时间确认节点是否恢复?如果过早回滚,可能导致重复执行;如果等待较久,则看起来像“卡住”。
这是可靠性与实时性的权衡。状态机设计往往倾向于避免副作用,因此宁可延迟判断,也不轻易回滚。
另一个常见场景是状态更新失败。任务已经执行完成,但数据库写入异常,状态仍停留在 RUNNING。此时系统必须通过幂等逻辑与恢复扫描机制来保证最终一致,而不是依赖瞬时内存结果。
因此,很多“异常”其实是分布式一致性策略的外在表现。
状态机设计为调度系统带来四个核心能力:幂等性、可恢复性、最终一致性与可观测性。
幂等性通过状态检查实现,任何已完成任务不会重复执行。可恢复性通过 NEED_FAULT_TOLERANCE 等中间状态实现,使任务可以在异常后重新进入调度循环。最终一致性依赖于 Master 重启后的状态扫描机制,使系统在节点故障后仍能收敛到正确状态。可观测性则来源于清晰的状态语义,使问题定位成为可能。
调度系统真正的难点,不在于如何提交任务,而在于如何在各种失败场景下维持状态的正确演进。状态机设计一旦出现漏洞,就会导致重复执行、丢失执行、状态紊乱或死锁。
在 Apache DolphinScheduler 中,可靠性并不是某个模块的特性,而是整个系统围绕状态机展开的结果。TaskInstance 是最小状态单元,WorkflowInstance 是聚合状态机,Master 是状态推进器,而数据库是状态的最终真相。
调度系统的灵魂,从来不是执行器,而是状态流转。真正困难的,不是让任务跑起来,而是在任何异常场景下,仍然能保证状态不乱、逻辑可恢复、结果可收敛。
当我们理解这一点,就会明白:调度系统之所以难,是因为可靠性本身就是一门关于状态机的工程艺术。
- 下篇预告:
第 5 篇|失败、重试、补数:调度语义的真相
Apache DolphinScheduler 3.3.2 正式发布!性能与稳定性有重要更新- GitHub: https://github.com/apache/dolphinscheduler
- 官网:https://dolphinscheduler.apache.org/en-us
- 订阅开发者邮件:dev@dolphinscheduler@apache.org(向邮箱发送任意内容,收到邮件后回复同意订阅即可)
- YouTube:https://www.youtube.com/@apachedolphinscheduler
- Slack:https://join.slack.com/t/asf-dolphinscheduler/shared_invite/zt-1cmrxsio1-nJHxRJa44jfkrNL_Nsy9Qg
同样地,参与Apache DolphinScheduler 有非常多的参与贡献的方式,主要分为代码方式和非代码方式两种。
非代码方式包括:
完善文档、翻译文档;翻译技术性、实践性文章;投稿实践性、原理性文章;成为布道师;社区管理、答疑;会议分享;测试反馈;用户反馈等。
代码方式包括:
查找Bug;编写修复代码;开发新功能;提交代码贡献;参与代码审查等。
贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/pulls?q=is%3Apr+is%3Aopen+label%3A%22first+time+contributor%22优先级问题列表:https://github.com/apache/dolphinscheduler/pulls?q=is%3Apr+is%3Aopen+label%3Apriority%3Ahigh如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/docs/3.2.2/%E8%B4%A1%E7%8C%AE%E6%8C%87%E5%8D%97_menu/%E5%A6%82%E4%BD%95%E5%8F%82%E4%B8%8E_menuhttps://github.com/apache/dolphinscheduler