本文档将深入解析 Apache SeaTunnel Zeta (SeaTunnel Engine) 、 Flink 和 Spark 。我们将从架构设计、核心特性、优缺点对比以及使用方法等多个维度进行详细讲解,帮助你根据业务需求选择最合适的引擎。
SeaTunnel 的架构设计采用了 API 与执行引擎解耦 的策略。这意味着同一套数据同步逻辑(Config)可以无缝运行在不同的引擎上。
Zeta Engine: SeaTunnel 社区专门为数据集成场景自研的新一代引擎,专注于高性能、低延迟的数据同步。 Flink Engine: 利用 Flink 强大的流处理能力,适合已拥有 Flink 集群的用户。 Spark Engine: 利用 Spark 强大的批处理能力,适合离线大规模数据处理场景。 Zeta 是目前 SeaTunnel 社区主推的默认引擎。它旨在解决 Flink/Spark 在简单数据同步场景下“资源消耗大、部署运维重”的问题。
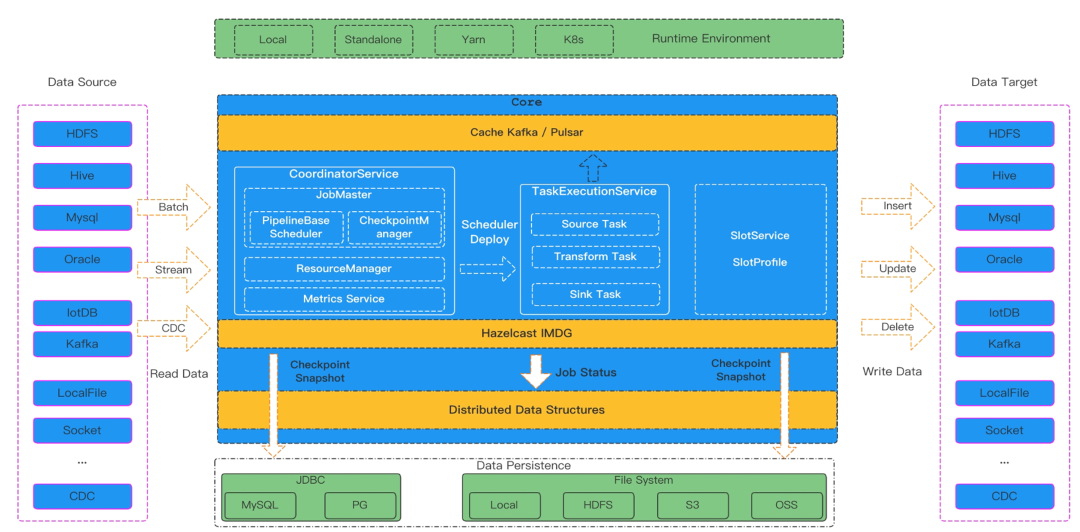
2.1 核心架构 Zeta 采用无中心化(Decentralized)或 Master-Slave 架构(取决于部署模式),主要包含以下组件:
Coordinator (Master): 作业解析: 将逻辑 DAG (Logical DAG) 转换为物理 DAG (Physical DAG)。 资源的调度: 管理 Slot,向 Worker 分配任务。 Checkpoint Coordinator: 负责触发和协调分布式快照(基于 Chandy-Lamport 算法),保障数据一致性。 Worker (Slave): Task Execution: 运行 Source, Transform, Sink 任务。 Data Transport: 负责节点间的数据传输。 ResourceManager: 支持 Standalone, YARN, Kubernetes 等多种资源管理模式。 2.2 关键特性 Pipeline 级容错 (Pipeline-level Fault Tolerance): 不同于 Flink 的“全图重启”,Zeta 可以只重启失败的 Pipeline(例如多表同步中,表 A 失败不影响表 B)。 增量快照 (Incremental Checkpoint): 支持高频 Checkpoint,最小化数据丢失风险,同时对性能影响极小。 动态扩缩容 (Dynamic Scaling): 支持在作业运行时动态增加或减少 Worker 节点,无需重启作业。 Schema Evolution (表结构变更): 原生支持 DDL 变更同步(如 Add Column),这对 CDC 场景至关重要。 2.3 使用指南 Zeta 引擎通常包含在 SeaTunnel 的二进制包中,开箱即用。
启动命令 (Local 模式 - 开发测试):
./bin/seatunnel.sh --config ./config/your_job.conf -e local 启动命令 (Cluster 模式 - 生产环境):
启动 Server (Master/Worker): ./bin/seatunnel-cluster.sh -d 提交任务到集群: ./bin/seatunnel.sh --config ./config/your_job.conf -e cluster
SeaTunnel 通过翻译层(Translation Layer)将内部的 Source/Sink API 适配为 Flink 的 SourceFunction / SinkFunction (或 Flink 新版 Source/Sink API)。
3.1 架构原理 Translation: SeaTunnel 在 Client 端将 Config 解析并翻译成 Flink JobGraph。 Execution: 提交给 Flink Cluster 执行。此时,SeaTunnel 任务就是一个标准的 Flink 任务。 State Backend: 依赖 Flink 的 Checkpoint 机制(RocksDB/FsStateBackend)管理状态。 3.2 优缺点 优点: 生态成熟,运维工具丰富,适合复杂的流式计算+同步场景 。 缺点: 版本耦合严重(需适配 Flink 1.13-1.18 等不同版本),对于纯同步任务显得过重。 3.3 使用指南 需要下载对应的 seatunnel-flink-starter jar 包,并确保 Flink 环境已准备好。
启动命令 (Flink 1.13+):
./bin/start-seatunnel-flink-13-connector-v2.sh \ --config ./config/your_job.conf \ --run-mode run (注意:不同 Flink 版本脚本名称略有不同,如 flink-15 , flink-18 )
类似于 Flink,SeaTunnel 将 Source/Sink 适配为 Spark 的 DataSource V2 API。
4.1 架构原理 Batch: 使用 Spark RDD / DataFrame API 执行离线批处理。 Streaming: 使用 Spark Streaming (Micro-batch) 执行流式处理。 4.2 优缺点 优点: 批处理性能强大,在大规模离线数据清洗/ETL 场景表现优异。 缺点: 流处理基于微批(Micro-batch),延迟通常高于 Flink/Zeta;资源调度较慢。 4.3 使用指南 需要下载对应的 seatunnel-spark-starter jar 包。
启动命令 (Spark 3.x):
./bin/start-seatunnel-spark-3-connector-v2.sh \ --config ./config/your_job.conf \ --master local [4] 定位 数据同步专用 适用场景 部署复杂度 低 资源消耗 低 延迟 低 容错粒度 Pipeline 级 CDC 支持 完美 多版本适配
如果你是新项目,或者主要需求是数据同步 :
首选 Zeta 引擎 。它最轻量、性能最好,且对 CDC 和多表同步有特殊优化。 如果你已经有现成的 Flink/Spark 集群,且运维团队不想维护新引擎 :
选择 Flink 或 Spark 引擎,复用现有基础设施。 如果你的任务包含极其复杂的自定义计算逻辑 :
优先考虑 Flink (流) 或 Spark (批),利用其丰富的算子生态。但也可以考虑 Zeta + SQL Transform 满足大部分需求。 如果你是第一次接触 SeaTunnel,请按照以下步骤快速体验 Zeta 引擎的强大功能。
7.1 环境准备 确保你的机器上安装了 Java 8 或 Java 11。
java -version 7.2 下载与安装 下载: 从Apache SeaTunnel 官网下载最新版本的二进制包 (apache-seatunnel-x.x.x-bin.tar.gz)。 解压: tar -zxvf apache-seatunnel-*.tar.gz cd apache-seatunnel-* 7.3 安装 Connector 插件 (重要!) 这是新手最容易忽略的一步 。默认包不包含所有 Connector,你需要运行脚本自动下载。
7.4 快速运行第一个任务 创建一个简单的配置文件 config/quick_start.conf ,将数据从 Fake 源生成并打印到控制台:
env { execution.parallelism = 1 job.mode = "BATCH" } source { FakeSource { result_table_name = "fake" row.num = 100 schema = { fields { name = "string" age = "int" } } } } transform { Sql { source_table_name = "fake" result_table_name = "sql_result" query = "select name, age from fake where age > 50" } } sink { Console { source_table_name = "sql_result" } } 运行任务 (Local 模式) :
./bin/seatunnel.sh --config ./config/quick_start.conf -e local 如果看到控制台输出了数据表格,恭喜你,你已经成功掌握了 SeaTunnel 的基本用法!
8. Zeta 引擎原理深度学习路径 如果你希望深入了解 Zeta 引擎的内部运作机制,或者想参与社区贡献,可以按照以下路径进行源码阅读和调试。
8.1 核心模块概览 Zeta 引擎的代码主要集中在 seatunnel-engine 模块下:
seatunnel-engine-core: 定义了核心数据结构(如 Job , Task )和通信协议。 seatunnel-engine-server: 包含了 Coordinator 和 Worker 的具体实现逻辑。 seatunnel-engine-client : 客户端提交逻辑。 8.2 源码阅读推荐路径 1. 作业提交与解析 (Coordinator 侧) 从 JobMaster 类开始,了解作业是如何被接收和初始化的。
入口 : org.apache.seatunnel.engine.server.master.JobMaster 逻辑: 关注 init 和 run 方法,了解 LogicalDag 到 PhysicalPlan 的转换过程。 2. 任务执行 (Worker 侧) 了解 Task 是如何被调度和执行的。
服务入口: TaskExecutionService.java 该类负责管理 Worker 节点上的所有 TaskGroup。 执行上下文: org.apache.seatunnel.engine.server.execution.TaskExecutionContext 3. Checkpoint 机制 (核心难点) Zeta 的快照机制是保证数据一致性的关键。
协调器: CheckpointCoordinator.java 重点阅读 triggerCheckpoint 方法,了解 Barrier 是如何分发的。 计划:CheckpointPlan.java 了解 Checkpoint 涉及的任务范围是如何计算的。 8.3 调试技巧 修改日志级别: 在 config/log4j2.properties 中,将 org.apache.seatunnel 的级别调整为 DEBUG ,可以看到详细的 RPC 通信和状态变更日志。 本地调试: 在 IDE 中直接运行 org.apache.seatunnel.core.starter.seatunnel.SeaTunnelStarter 类,传入 -c config/your_job.conf -e local 参数,即可断点调试整个流程。 Apache SeaTunnel Apache SeaTunnel是一个云原生的多模态、高性能海量数据集成工具。北京时间 2023 年 6 月1 日,全球最大的开源软件基金会ApacheSoftware Foundation正式宣布SeaTunnel毕业成为Apache顶级项目。目前,SeaTunnel在GitHub上Star数量已达9.1k+,社区达到7000+人规模。SeaTunnel支持在云数据库、本地数据源、SaaS、大模型等170多种数据源之间进行数据实时和批量同步,支持CDC、DDL变更、整库同步等功能,更是可以和大模型打通,让大模型链接企业内部的数据。
https://github.com/apache/seatunnel https://seatunnel.apache.org/ https://seatunnel.apache.org/download 我们相信,在 「 Community Over Code 」 (社区大于代码)、 「Open and Cooperation」 (开放协作)、 「Meritocracy」 (精英管理)、以及「 多样性与共识决策」 等 The Apache Way 的指引下,我们将迎来更加多元化和包容的社区生态,共建开源精神带来的技术进步! 我们诚邀各位有志于让本土开源立足全球的伙伴加入 SeaTunnel 贡献者大家庭,一起共建开源! https://github.com/apache/seatunnel/issues https://github.com/apache/seatunnel/pulls dev-subscribe@seatunnel.apache.org https://join.slack.com/t/apacheseatunnel/shared_invite/zt-1kcxzyrxz-lKcF3BAyzHEmpcc4OSaCjQ https://x.com/ASFSeaTunnel