Apache DolphinScheduler用的是单机部署,具体操作可以参考官方文档:DolphinScheduler | 文档中心(https://dolphinscheduler.apache.org/zh-cn/docs/3.3.2/guide/installation/standalone).
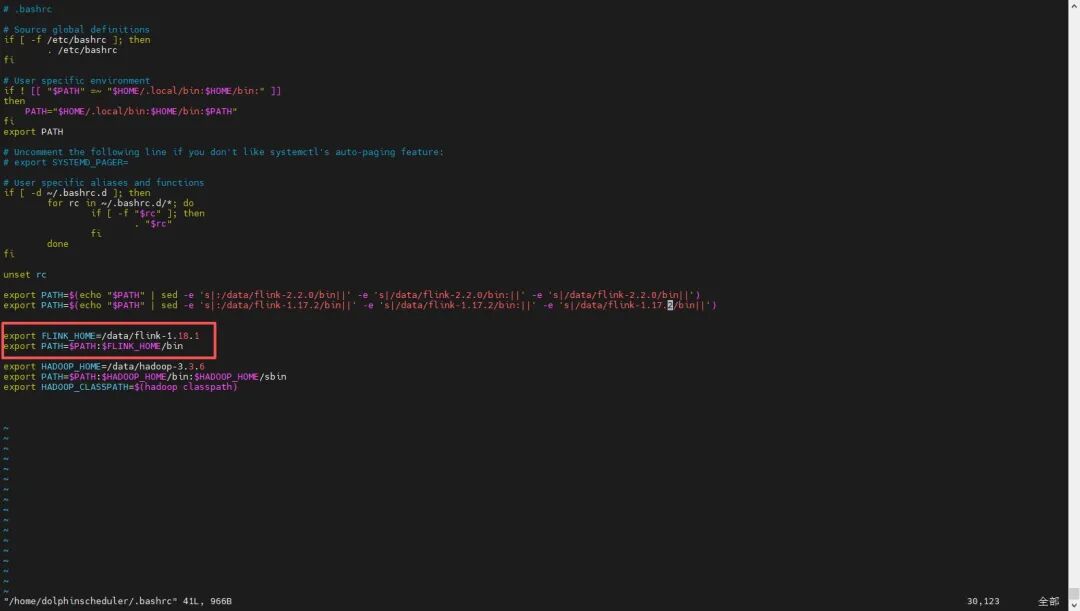
1、编辑环境变量:
增加Flink的路径
2、使环境变量生效:
#使环境变量生效source ~/.bashrc#查看环境变量echo $Flink_HOME
修改Kafka、Flink以及DolphinScheduler的配置文件。
因为用的是虚拟机,为了让外面的主机能够访问到虚拟机的网络,需要修改下配置文件
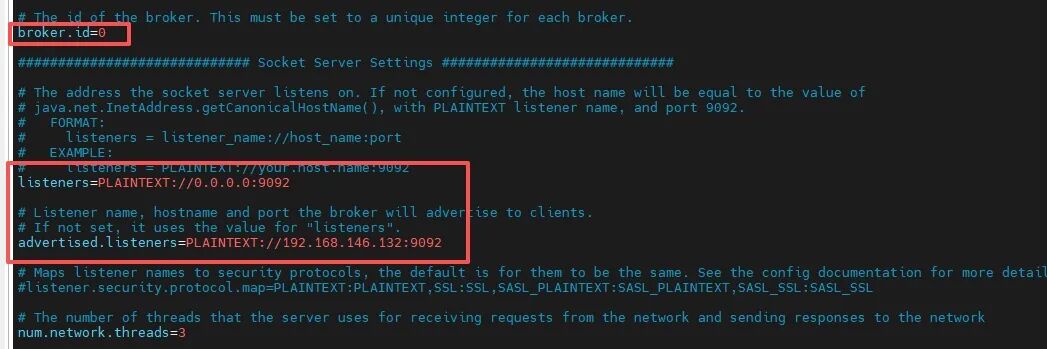
修改Kafka配置:找到Kafka安装包下的config文件夹,修改config下的server.properties文件,修改listeners是为了外面的主机能够访问到虚拟机的Kafka,还有把advertised.listeners改成虚拟机地址,写样例的时候能连上虚拟机的Kafka地址,不然默认连localhost
broker.id=0listeners=PLAINTEXT://0.0.0.0:9092#192.168.146.132修改成虚拟机ipadvertised.listeners=PLAINTEXT://192.168.146.132:9092
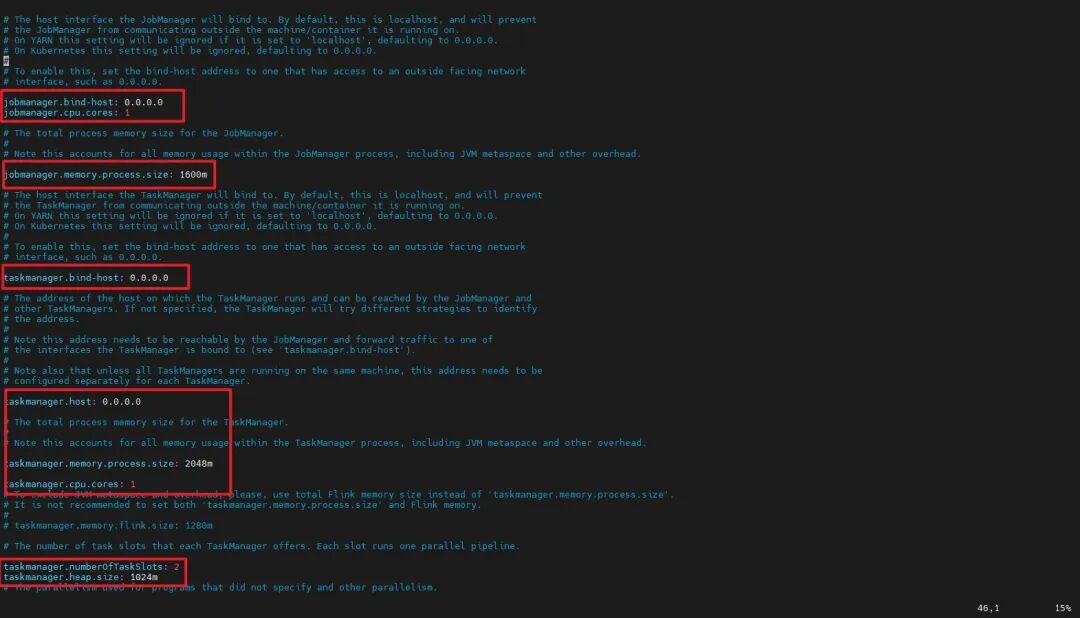
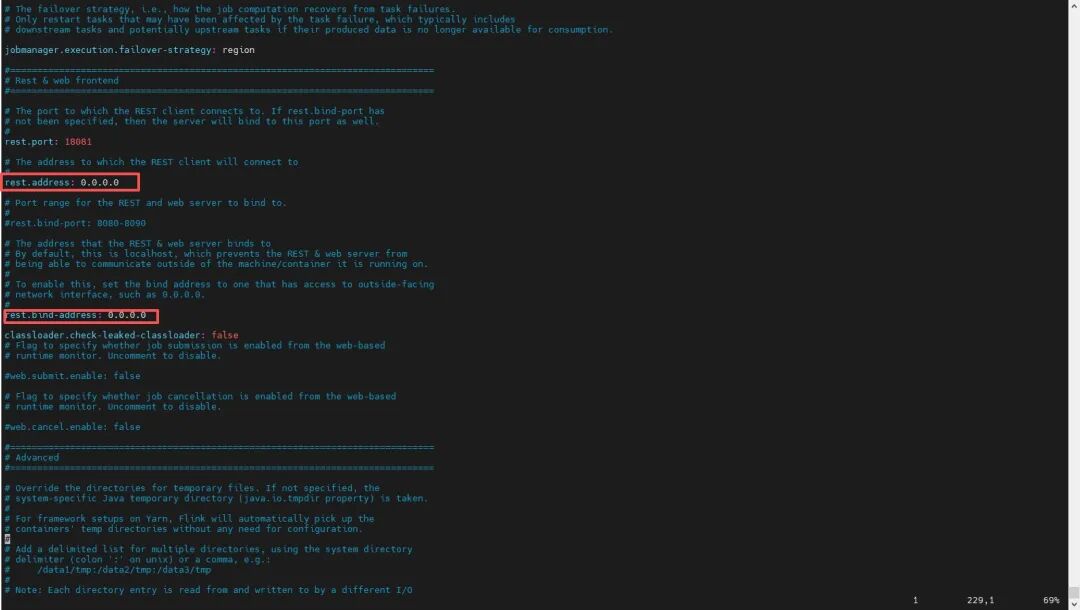
修改Flink配置:找到Flink安装包下的conf文件夹,修改conf下的Flink-conf.yaml文件,把里面所有的localhost地址全部改成0.0.0.0,以便主机能访问到虚拟机的Flink。还有增加jobmanager和taskmanager的内存
jobmanager.rpc.address: 0.0.0.0jobmanager.bind-host: 0.0.0.0jobmanager.cpu.cores: 1jobmanager.memory.process.size: 1600mtaskmanager.bind-host: 0.0.0.0taskmanager.host: 0.0.0.0taskmanager.memory.process.size: 2048mtaskmanager.cpu.cores: 1
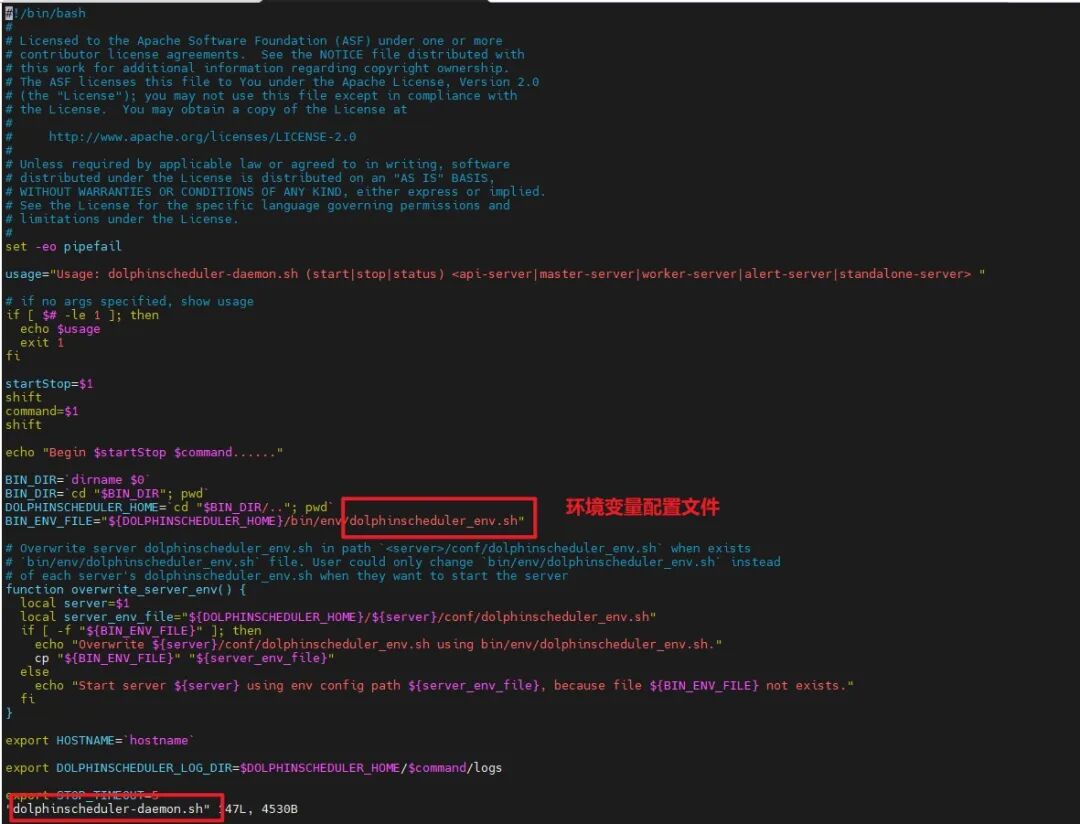
- 修改Apache DolphinScheduler的配置文件,从Apache DolphinScheduler的启动脚本文件
dolphinscheduler-daemon.sh可以看出,配置环境变量用的是bin/env文件夹下的dolphinscheduler_env.sh。
查看dolphinscheduler-daemon.sh文件:
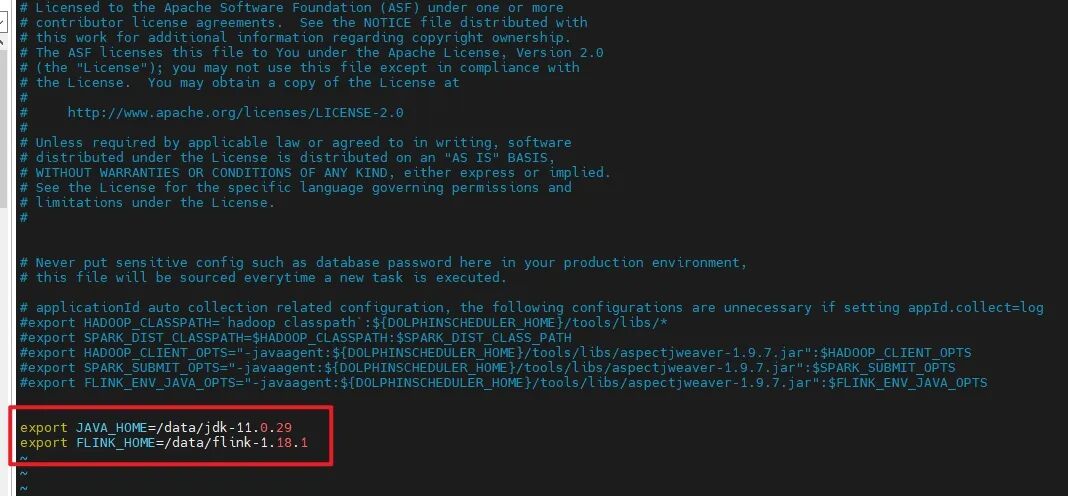
修改dolphinscheduler_env.sh文件,新增JAVA、Flink路径:
#修改成自己的JAVA、Flink路径export JAVA_HOME=/data/jdk-11.0.29export Flink_HOME=/data/Flink-1.18.1
启动应用,包括Zookeeper、Kafka、Flink以及Apache DolphinScheduler。
#关闭防火墙sudo systemctl stop firewalld# 在 Flink 根目录下,执行以下命令启动 Flink 集群bin/start-cluster.sh# 启动 ZooKeeperbin/zookeeper-server-start.sh config/zookeeper.properties &# 启动 Kafka 服务器bin/Kafka-server-start.sh config/server.properties &#创建 Kafka 主题bin/Kafka-topics.sh --create --topic test --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1#使用命令行生产者发送消息bin/Kafka-console-producer.sh --topic test --bootstrap-server localhost:9092#消费bin/Kafka-console-consumer.sh --topic test --from-beginning --bootstrap-server localhost:9092# 启动 Standalone Server 服务bash ./bin/dolphinscheduler-daemon.sh start standalone-server
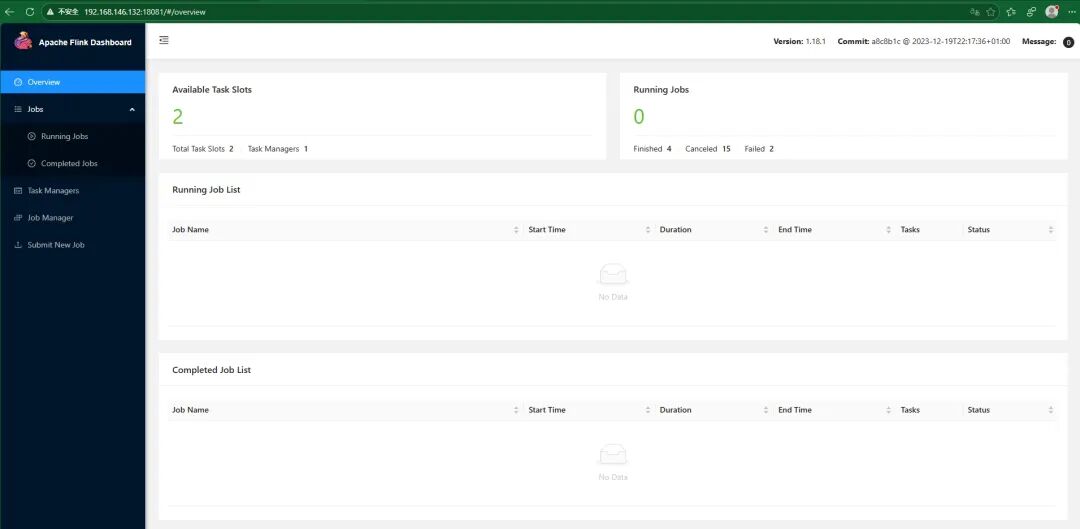
测试Flink、Apache DolphinScheduler是否能访问成功。
- Flink访问地址:http://localhost:8081/,localhost改成自己虚拟机地址
- Apache DolphinScheduler访问地址:http://localhost:12345/dolphinscheduler/ui ,localhost改成自己虚拟机地址即可登录系统 UI。默认的用户名和密码是 admin/dolphinscheduler123
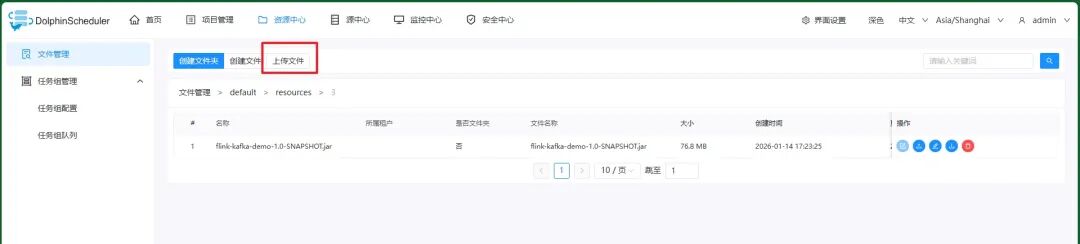
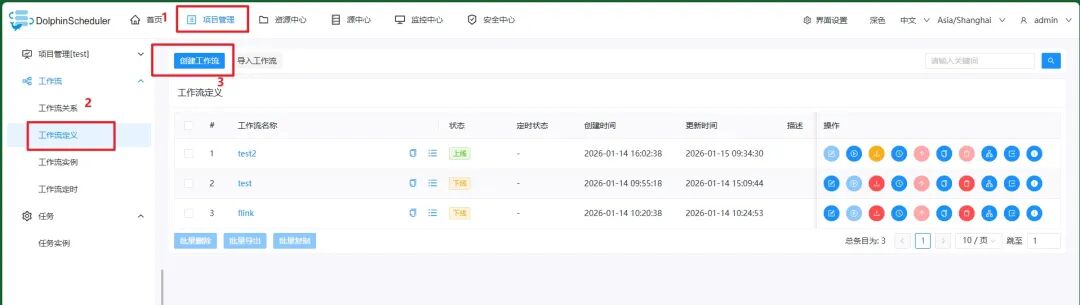
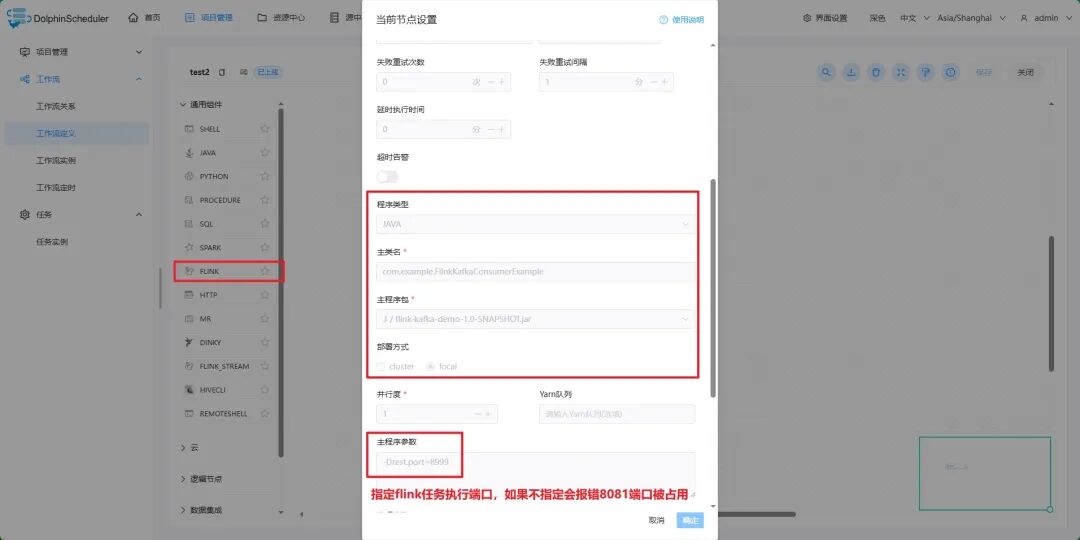
用Flink消费Kafka数据,然后打包上传到Apache DolphinScheduler,启动Flink任务:
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.example</groupId> <artifactId>Flink-Kafka-demo</artifactId> <version>1.0-SNAPSHOT</version> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> <Flink.version>1.18.1</Flink.version> <scala.binary.version>2.12</scala.binary.version> <Kafka.version>3.6.0</Kafka.version> </properties> <dependencies> <!-- Flink核心依赖 --> <dependency> <groupId>org.apache.Flink</groupId> <artifactId>Flink-java</artifactId> <version>${Flink.version}</version> </dependency> <dependency> <groupId>org.apache.Flink</groupId> <artifactId>Flink-streaming-java</artifactId> <version>${Flink.version}</version> </dependency> <dependency> <groupId>org.apache.Flink</groupId> <artifactId>Flink-clients</artifactId> <version>${Flink.version}</version> </dependency> <!-- 连接器基础依赖 --> <dependency> <groupId>org.apache.Flink</groupId> <artifactId>Flink-connector-base</artifactId> <version>${Flink.version}</version> </dependency> <!-- Kafka连接器(关键修改点) --> <dependency> <groupId>org.apache.Flink</groupId> <artifactId>Flink-connector-Kafka</artifactId> <version>3.1.0-1.18</version> </dependency> <dependency> <groupId>org.apache.Kafka</groupId> <artifactId>Kafka-clients</artifactId> <version>${Kafka.version}</version> </dependency> <!-- 日志依赖 --> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-simple</artifactId> <version>1.7.36</version> <scope>runtime</scope> </dependency> </dependencies> <repositories> <repository> <id>aliyun</id> <url>https://maven.aliyun.com/repository/public</url> <releases> <enabled>true</enabled> </releases> <snapshots> <enabled>false</enabled> </snapshots> </repository> <repository> <id>apache-releases</id> <url>https://repository.apache.org/content/repositories/releases/</url> </repository> </repositories> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.8.1</version> <configuration> <source>${maven.compiler.source}</source> <target>${maven.compiler.target}</target> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>3.2.4</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <artifactSet> <excludes> <exclude>org.apache.Flink:force-shading</exclude> <exclude>com.google.code.findbugs:jsr305</exclude> <exclude>org.slf4j:*</exclude> </excludes> </artifactSet> <filters> <filter> <artifact>*:*</artifact> <excludes> <exclude>META-INF/*.SF</exclude> <exclude>META-INF/*.DSA</exclude> <exclude>META-INF/*.RSA</exclude> </excludes> </filter> </filters> </configuration> </execution> </executions> </plugin> </plugins> </build></project>FlinkKafkaConsumerExample.java
import org.apache.Flink.api.common.functions.FlatMapFunction;import org.apache.Flink.api.java.tuple.Tuple2;import org.apache.Flink.api.java.utils.ParameterTool;import org.apache.Flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.Flink.streaming.api.datastream.DataStream;import org.apache.Flink.streaming.api.functions.ProcessFunction;import org.apache.Flink.streaming.api.functions.sink.RichSinkFunction;import org.apache.Flink.util.Collector;import org.apache.Flink.streaming.connectors.Kafka.FlinkKafkaConsumer;import org.apache.Flink.api.common.serialization.SimpleStringSchema;import org.apache.Kafka.clients.consumer.ConsumerConfig;import org.apache.Kafka.common.serialization.StringDeserializer;import java.util.Properties;import java.util.concurrent.CompletableFuture;public class FlinkKafkaConsumerExample { private static volatile int messageCount = 0; private static volatile boolean shouldStop = false; public static void main(String[] args) throws Exception { // 设置执行环境 final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // Kafka 配置 Properties properties = new Properties(); properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.146.132:9092"); // Kafka broker 地址 properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "test-group"); // 消费者组 properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); // 创建 Kafka 消费者 FlinkKafkaConsumer<String> KafkaConsumer = new FlinkKafkaConsumer<>("test", new SimpleStringSchema(), properties); KafkaConsumer.setStartFromEarliest(); // 从最早的消息开始消费 DataStream<String> stream = env.addSource(KafkaConsumer); // 处理数据:分词和计数 DataStream<Tuple2<String, Integer>> counts = stream .flatMap(new Tokenizer()) .keyBy(value -> value.f0) .sum(1); counts.addSink(new RichSinkFunction<Tuple2<String, Integer>>() { @Override public void invoke(Tuple2<String, Integer> value, Context context) { System.out.println(value); messageCount++; // 检查是否达到停止条件 if (messageCount >= 2 && !shouldStop) { System.out.println("Processed 2 messages, stopping job."); shouldStop = true; // 设置标志位,表示应该停止 } } }); // 执行作业并获取 JobClient CompletableFuture<Void> future = CompletableFuture.runAsync(() -> { try { // 启动作业并获取 JobClient org.apache.Flink.core.execution.JobClient jobClient = env.executeAsync("Flink Kafka WordCount"); System.out.println("Job ID: " + jobClient.getJobID()); // 监测条件并取消作业 while (!shouldStop) { Thread.sleep(100); // 每100毫秒检查一次 } // 达到停止条件时取消作业 if (shouldStop) { System.out.println("Cancelling the job..."); jobClient.cancel().get(); // 取消作业 } } catch (Exception e) { e.printStackTrace(); } }); // 在主线程中等待作业结束 future.join(); // 等待作业完成 } // Tokenizer 类用于将输入字符串转化为单词 public static final class Tokenizer implements FlatMapFunction<String, Tuple2<String, Integer>> { @Override public void flatMap(String value, Collector<Tuple2<String, Integer>> out) { String[] tokens = value.toLowerCase().split("\\W+"); for (String token : tokens) { if (token.length() > 0) { out.collect(new Tuple2<>(token, 1)); } } } }}- 打包上传到Apache DolphinScheduler
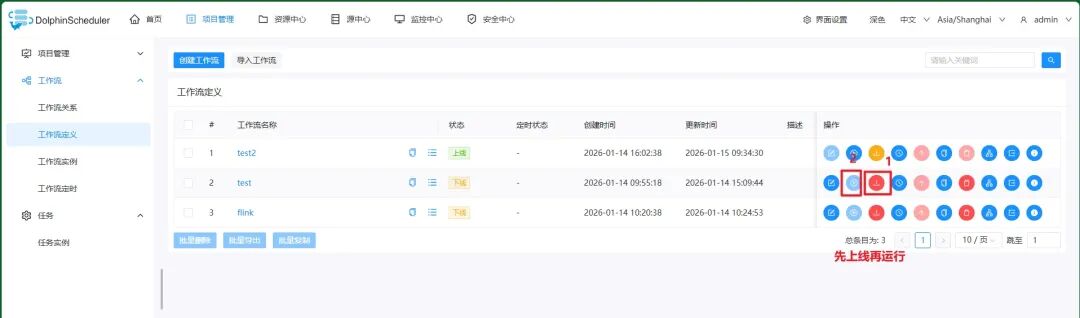
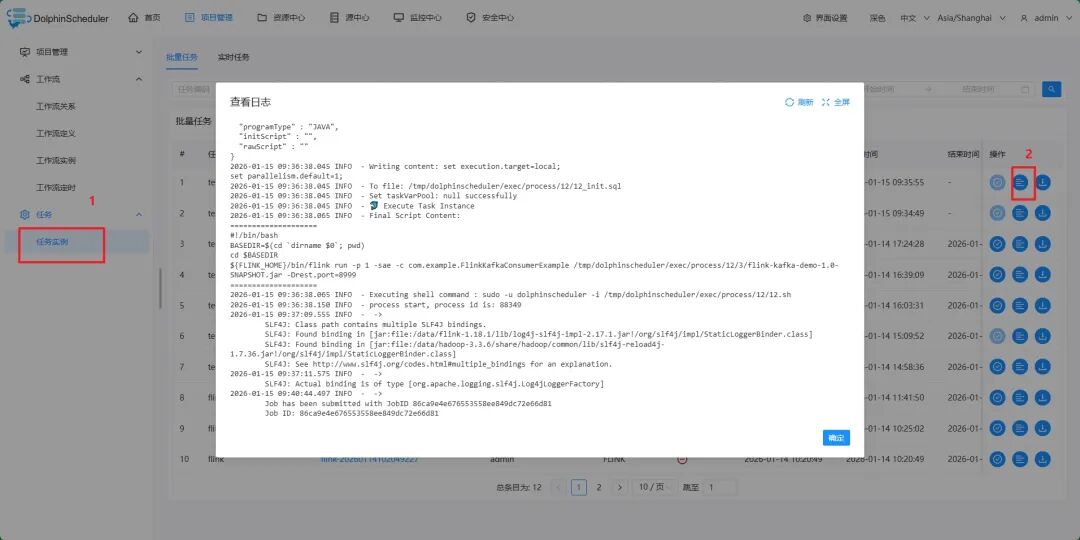
在Apache DolphinScheduler的任务实例看启动日志:
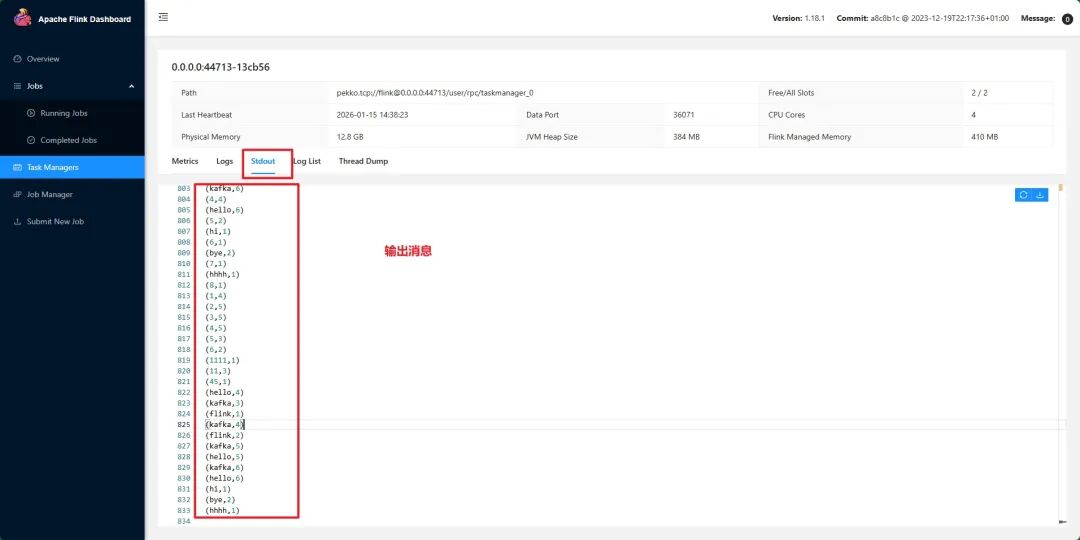
在虚拟机启动生产者,输出字符串,然后可以在Flink查看输出Kafka生产的消息:
原文链接:https://blog.csdn.net/Analyze_ing/article/details/156940553
- GitHub: https://github.com/apache/dolphinscheduler
- 官网:https://dolphinscheduler.apache.org/en-us
- 订阅开发者邮件:dev@dolphinscheduler@apache.org(向邮箱发送任意内容,收到邮件后回复同意订阅即可)
- YouTube:https://www.youtube.com/@apachedolphinscheduler
- Slack:https://join.slack.com/t/asf-dolphinscheduler/shared_invite/zt-1cmrxsio1-nJHxRJa44jfkrNL_Nsy9Qg
同样地,参与Apache DolphinScheduler 有非常多的参与贡献的方式,主要分为代码方式和非代码方式两种。
非代码方式包括:
完善文档、翻译文档;翻译技术性、实践性文章;投稿实践性、原理性文章;成为布道师;社区管理、答疑;会议分享;测试反馈;用户反馈等。
代码方式包括:
查找Bug;编写修复代码;开发新功能;提交代码贡献;参与代码审查等。
贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/pulls?q=is%3Apr+is%3Aopen+label%3A%22first+time+contributor%22优先级问题列表:https://github.com/apache/dolphinscheduler/pulls?q=is%3Apr+is%3Aopen+label%3Apriority%3Ahigh如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/docs/3.2.2/%E8%B4%A1%E7%8C%AE%E6%8C%87%E5%8D%97_menu/%E5%A6%82%E4%BD%95%E5%8F%82%E4%B8%8E_menuhttps://github.com/apache/dolphinscheduler