关注我们
作者 | 贾敏 多点DMALL 资深大数据研发工程师
多点 DMALL 是一个全球零售智能化解决方案提供商,支撑着 430+ 客户的数字化转型。随着业务快速扩张,数据同步的实时性、资源效率和开发灵活性,成为我们必须攻克的三大难题。
多点 DMALL 的数据平台经过四次跃迁,始终围绕“更快、更省、更稳”展开。
在多点 DMALL 的数据平台建设过程中,先是借 AWS-EMR 快速构建云端大数据能力,再回归 IDC 自建 Hadoop 集群 ,以开源内核叠加自研集成、调度、开发组件,把重资产沉淀为可复用的轻服务。当业务需要更低成本、更高弹性,团队用存算分离、容器化重构底座,引入 Apache SeaTunnel 让数据实时入湖;继而以 Apache Iceberg、Paimon 统一存储格式,形成湖仓一体的新架构,为 AI 提供稳态、低成本的数据基座,完成由借云到造云、由离线到实时的闭环。
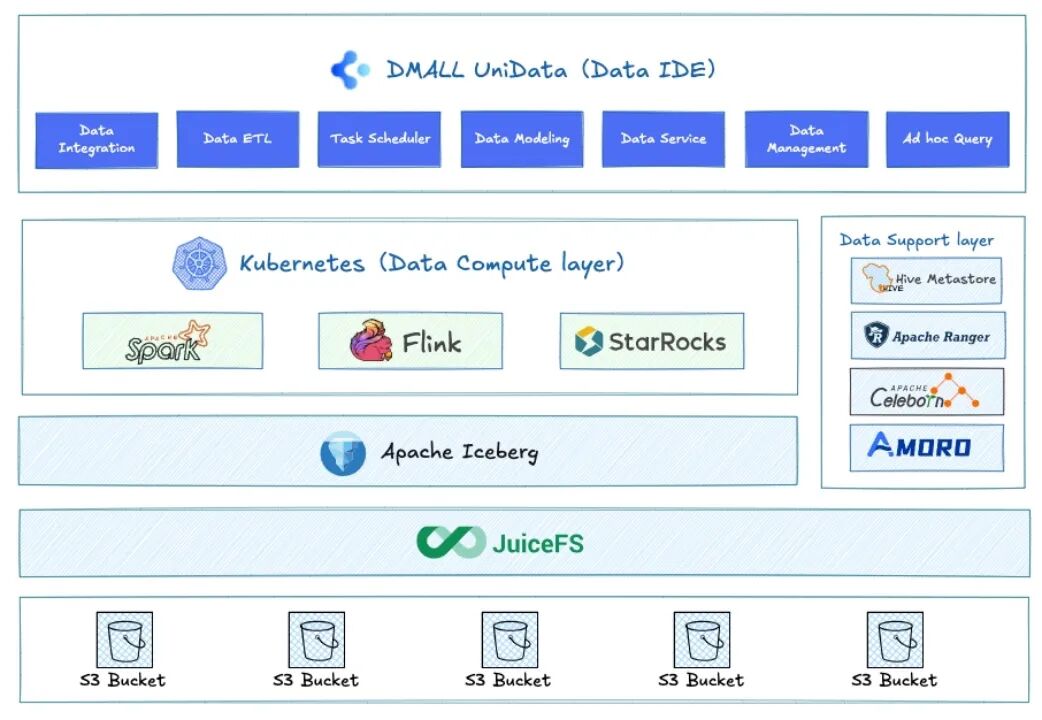
DMALL UniData(Data IDE)的存算分离架构以Kubernetes 为弹性基座,Spark、Flink、StarRocks 按需伸缩,Iceberg+JuiceFS 统一湖存储,Hive Metastore 跨云管理元数据,Ranger 细粒度授权,存算分离、零厂商绑定,技术栈全链路可控。
由此带来的业务收益水到渠成:TCO直降40-75%,资源秒级扩缩,同一套IDE框架覆盖集成、调度、建模、查询与服务,交付快、人力省,多云畅行且安全。
在引入 Apache SeaTunnel 之前,多点 DMALL 数据平台数据互导已支持 MySQL、Hive、ES 等十余种存储自助式数据同步,基于 Spark 自研多种数据源,可按需求定制化接入,但仅支持批处理(Batch)模式。
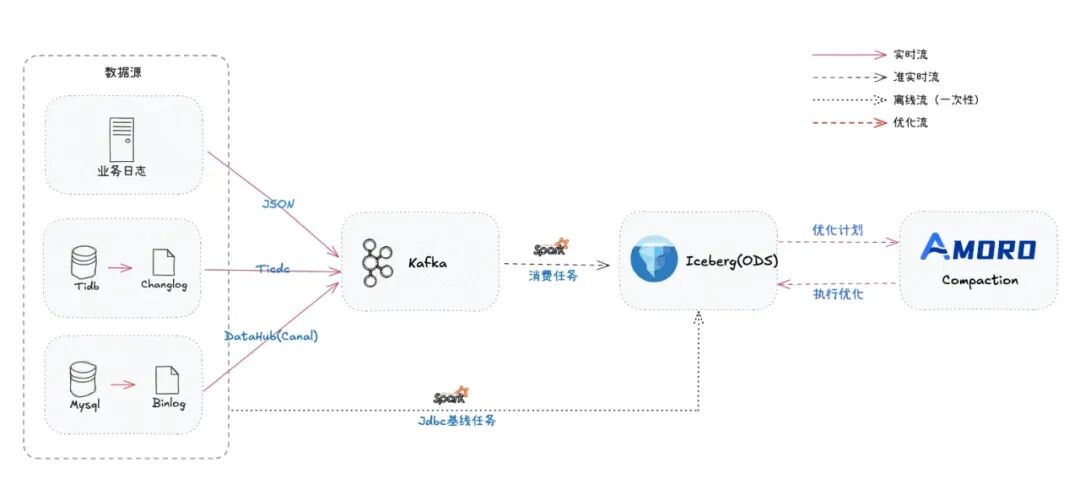
在数据导入方面,多点 DMALL 数据平台统一承载公司 ODS 数据入湖,采用 Apache Iceberg 作为湖仓格式,支持小时级数据下游可用 ,数据复用率高,数据质量有保障。
过去我们依赖 Spark 自研同步工具,虽然稳定,却面临“启动慢、资源重、扩展难”的痛点。
“不是 Spark 不好,而是它太重了。”
在降本增效的大背景下,我们重新审视了原有的数据集成架构。Spark 批任务虽然成熟,但在处理中小规模数据同步时显得“杀鸡用牛刀”。启动慢、资源占用高、开发周期长,成为团队效率的瓶颈。更重要的是,面对越来越多实时性业务需求,Spark 的批处理模式已难以为继。
现阶段仍需要开发人员用 Java/Flink 自行实现
直到我们遇见了 Apache SeaTunnel,一切开始改变。
“我们不是在选工具,而是在选未来五年的数据集成底座。”
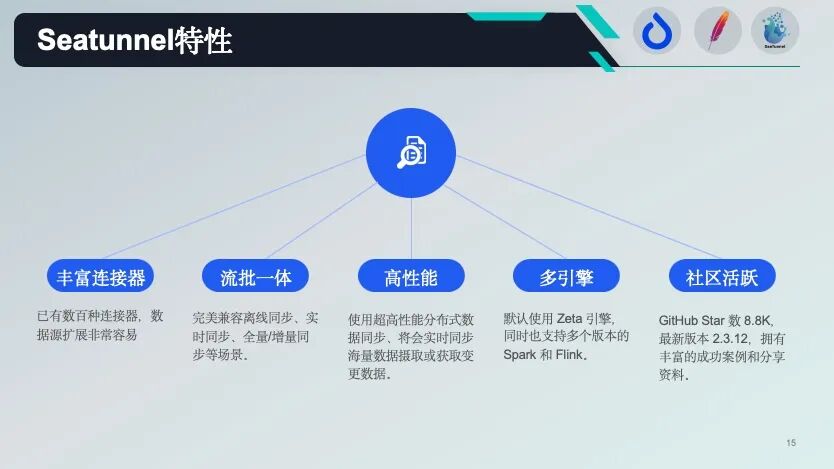
面对多样化的数据源、实时性需求和资源优化压力,我们需要一个“批流一体、轻量高效、易扩展”的集成平台。SeaTunnel 以其开源、多引擎支持、丰富的连接器和活跃社区,成为我们最终的选择。它不仅解决了 Spark 的“重”问题,还为未来的湖仓一体和实时分析打下了基础。
引擎中立:内置 Zeta,同时兼容 Spark/Flink,可随数据量自动切换。 连接器官网已 200+,且插件化:新增数据源只写 JSON,零 Java 代码。 社区活跃:GitHub 8.8k star,PR 周合并 30+,我们提的 5 个 Patch 均在 7 天内合入主干。 “开源不是拿来就用,而是站在巨人肩膀上继续造轮子。”
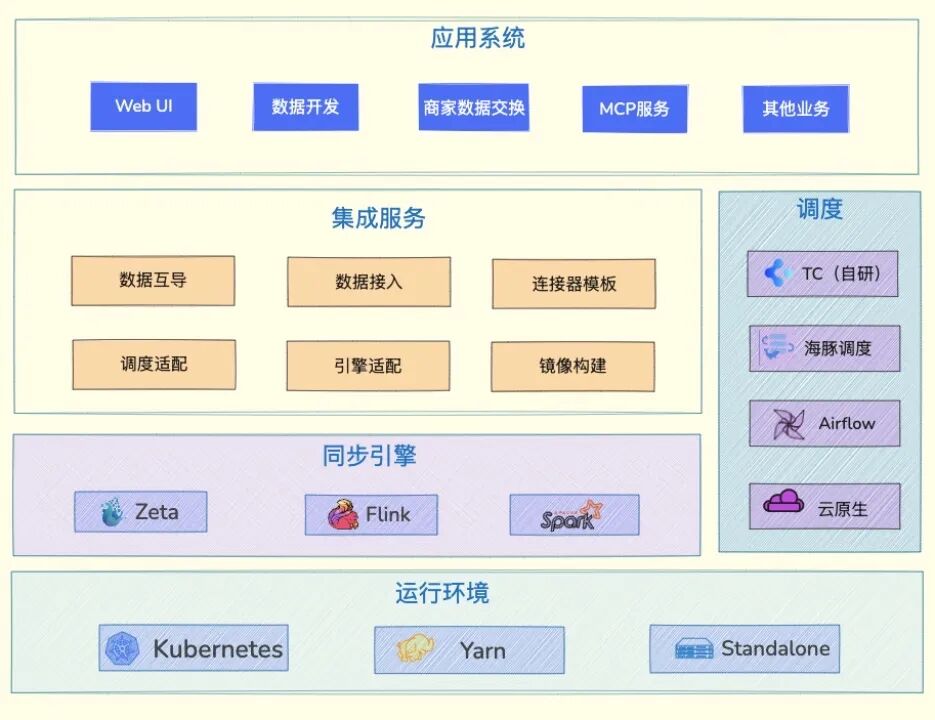
SeaTunnel 虽然强大,但要真正落地企业级场景,还需要一层“外壳”——统一的管理、调度、权限、限流、监控等能力。我们围绕 SeaTunnel 构建了一套可视化、可配置、可扩展的数据集成平台,让它从一个开源工具,成长为多点数据平台的“核心引擎”。
3.1 全局架构 以 Apache SeaTunnel 为底座,平台向上透出统一 REST API,Web UI、商家交换、MCP 服务等任何外部系统都可一键调用;内置连接器模板中心,新存储只需填参数即可分钟级发布,无需编码。调度层同时适配 Apache DolphinScheduler airflow
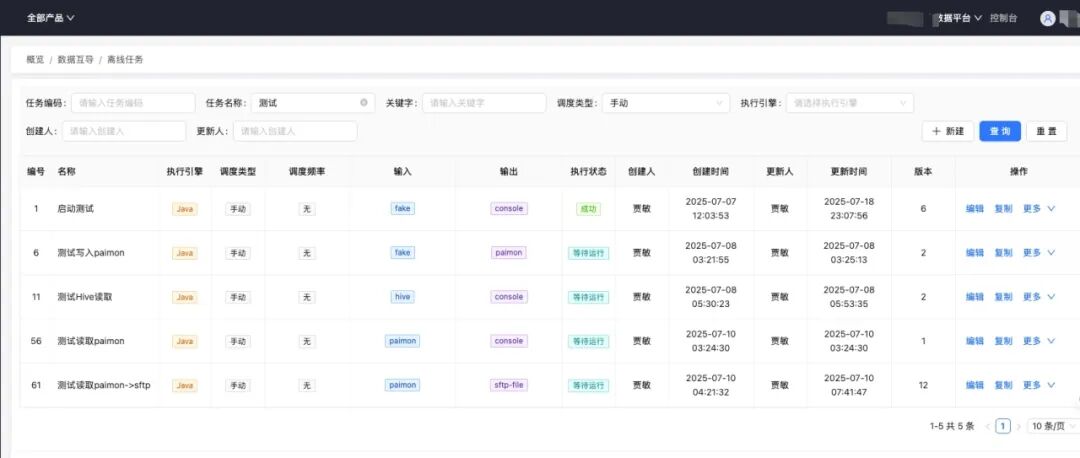
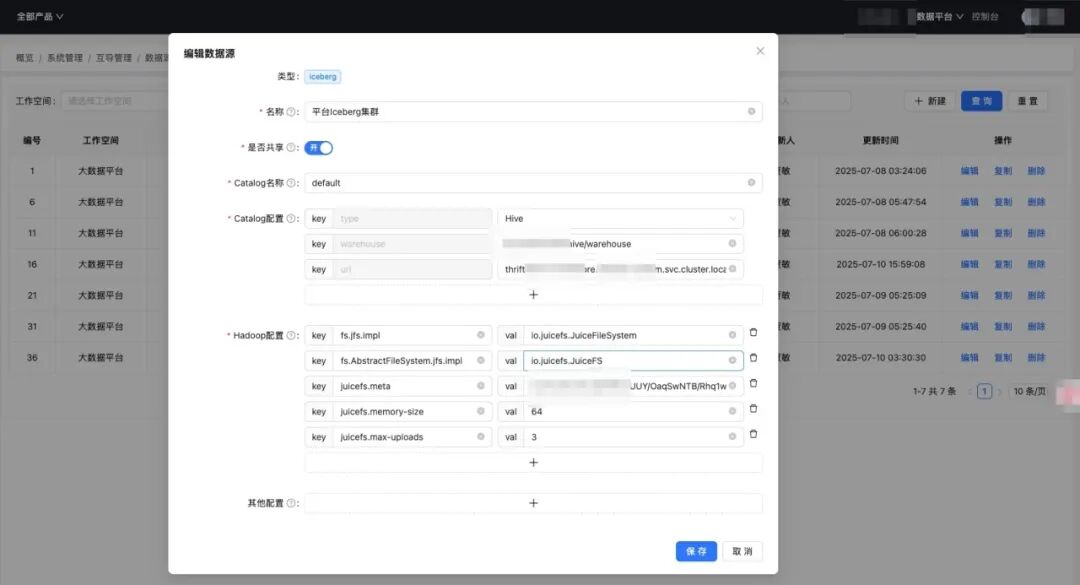
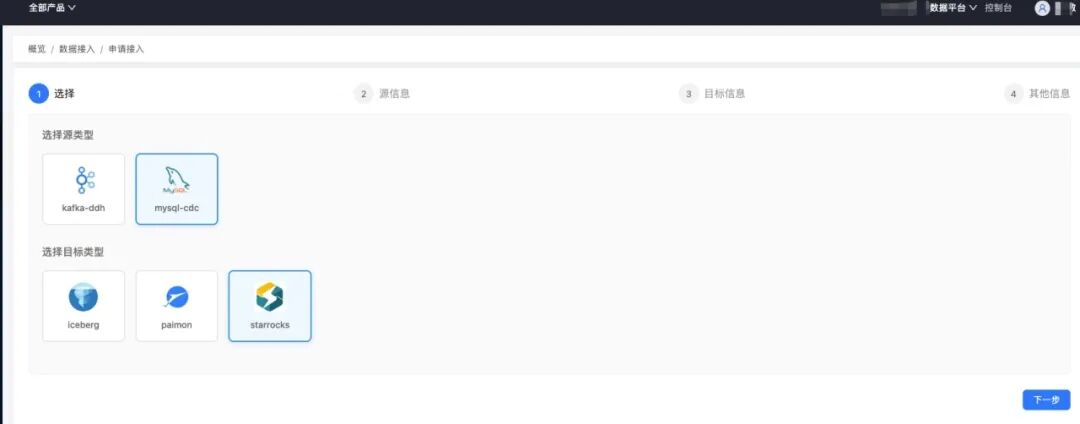
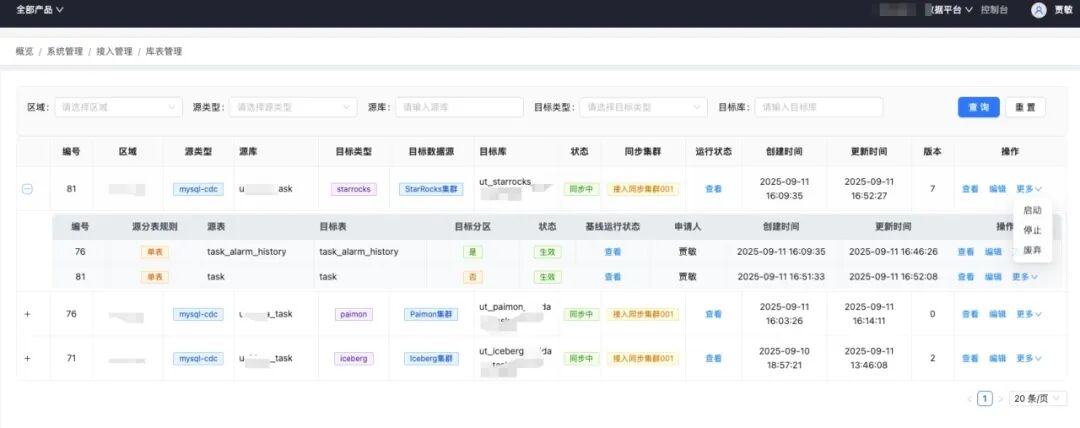
3.2 互导功能 数据源注册:地址、账号、密码一次录入,敏感字段加密,公共数据源(如 Hive)全租户可见。 连接器模板:通过配置新增连接器,定义 SeaTunnel 配置生成规则,控制任务界面 Source、Sink 显示 离线任务:运行批任务支持 Zeta 和 Spark 引擎,通过 DAG 图描述同步任务,支持通配符变量注入 实时任务:运行流任务支持 Zeta 和 Flink 引擎,通过 S3 协议存储 Checkpoint,可进行 CDC 增量同步 接入功能 接入申请:用户提交同步表申请工单;管理员审批,以保障数据接入质量 库表管理:按库同步,避免同步链路过多;统一管理链路,数据质量有保障;支持分表合并成一张表 基线拉取:通过批任务进行自动建表和初始化;超大表可按照规则拆分拉取;数据缺失可基于条件拉取补齐 数据同步:同步任务通过REST API提交到集群;支持限流、打标特性保证重要同步;CDC增量写入多种湖仓 “再优秀的开源项目,也听不懂你业务的‘方言’。”
SeaTunnel 的插件机制虽然灵活,但面对多点自研的 DDH 消息格式、分库分表合并、动态分区等需求,仍需我们“动手改代码”。幸运的是,SeaTunnel 的模块化设计让二次开发变得高效且可控。以下是我们重点改造的几个模块,每一项都直接解决了业务痛点。
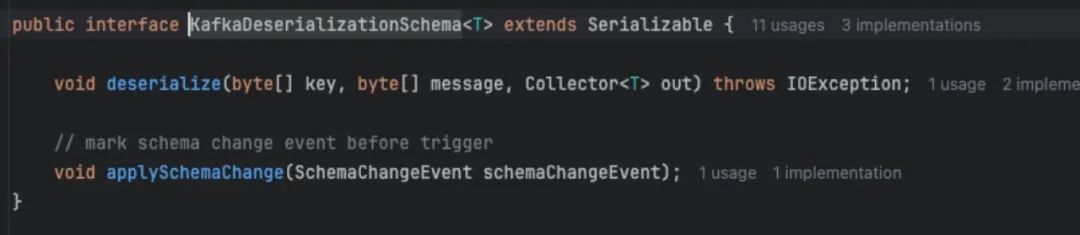
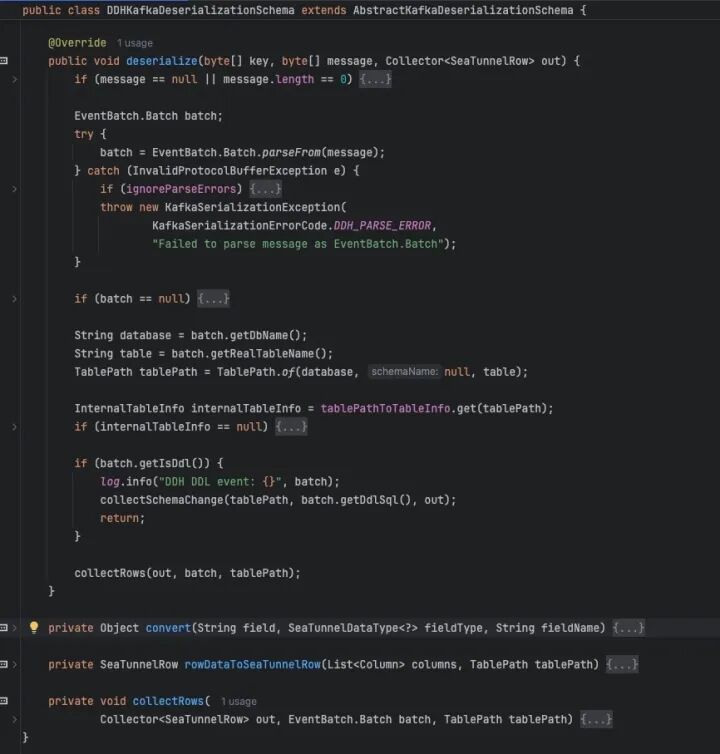
4.1 定制DDH-Format CDC 多点自研 DDH 采集 MySQL binlog,以 Protobuf 推 Kafka。我们实现了
KafkaDeserializationSchema: 解析 Protobuf → SeaTunnelRow; DDL 消息直接构建 CatalogTable,自动在 Paimon 侧加列; DML 打标“before/after”,下游 StarRocks 做部分列更新。
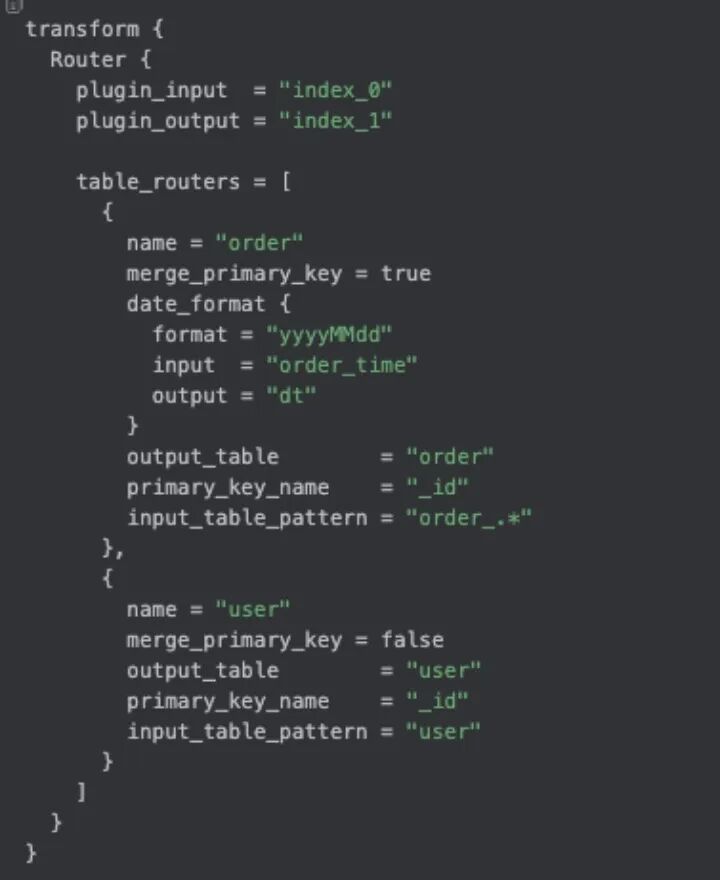
4.2 Router Transform:多表合并+动态分区 场景:1200 张分库分表 t_order_00…t_order_1199 → 一张 paimon 表 dwd_order。 选基准 Schema(字段最多的一张表),其余表缺失字段补 NULL; 主键冲突用 $table_name + $pk 生成新 UK; 分区字段 dt 从字符串 create_time 截取,支持 yyyy-MM-dd 与 yyyyMMdd 两种格式自动识别。 配置片段:
4.3 Hive-Sink支持Overwrite 社区版只有 append,我们基于 PR #7843 二次开发:
任务提交前,先根据分区值调用 FileSystem.listStatus() 拿到旧路径; 已贡献回社区,预计 2.3.14 发布。
4.4 其他补丁 JuiceFS 连接器:支持 mount 点缓存,listing 性能提升 5 倍; Kafka-2.x 独立模块:解决 0.10/2.x 协议冲突; 升级 JDK11:Zeta 引擎 GC 时间下降 40%; 新增 JSON UDF json_extract_array / json_merge ,日期 UDF date_shift() ,已合入主干。 “每一个坑,都是通往稳定的必经之路。”
开源项目再成熟,落地到真实业务场景也免不了踩坑。我们在使用 SeaTunnel 的过程中,也遇到了版本冲突、异步操作、消费延迟等问题。以下是我们踩过的几个典型“坑”,以及最终的解决方案,希望能帮你少走弯路。
Spark 3.3.4 与 SeaTunnel 默认内置 Hadoop 3.1.4 冲突 排除 Spark 的 hadoop-client,改用 SeaTunnel uber jar 在 sink 中轮询 SHOW ALTER TABLE STATE ,FINISHED 后再恢复写入 提 PR #7821 ,支持“空轮询不 sleep”模式,吞吐量提到 12w/s
“技术价值,最终要用数字说话。”
我们用了 Apache SeaTunnel 不到三个月时间,完成了 3 套商家生产环境的割接。结果不仅“跑得更快”,还“跑得更省”。
Oracle、云存储、Paimon、StarRocks 等源端需求被一次性覆盖,实时同步不再靠手写 Flink;模板化“零代码”接入,让新增连接器从过去的 N 周压缩到 3 天,资源消耗仅为原 Spark 的 1/3,同样数据量跑得更轻更快。
配合全新 UI 和按需开放的数据源权限,商家 IT 自己就能配任务、看链路,交付成本骤降,使用体验直线上升,真正兑现了降本、灵活、稳态三大目标。
“数据集成不是终点,而是智能分析的起点。” *
Apache SeaTunnel 帮我们解决了数据“搬得快”和“搬得省”的问题,接下来我们要解决的是“搬得准”和“搬得智”。随着 Paimon、StarRocks、LLM 等技术的成熟,我们正在构建一个“实时湖仓 + AI 智能”的数据平台,让数据不仅看得见,更用得准。
未来,多点将把“实时”与“智能”写进数据平台的下一行代码:
1)湖仓升级: 全面接入 Paimon + StarRocks,把 ODS 入湖时效从小时级压到分钟级,为商家提供准实时的数据底座。
2)AI Ready: 通过 MCP 服务调用 LLM 自动生成同步配置,并引入向量化执行引擎,打造 AI 训练可直接消费的流水线,让数据集成环节“零代码、智能化”。
3)社区互动: 跟踪 SeaTunnel 主版本迭代,第一时间引入性能优化;内部通用改进以 PR 形式回馈社区,形成“使用-改进-开源”的闭环,持续放大技术红利。
“如果你也在为数据同步的‘重’和‘慢’头疼,不妨给 SeaTunnel 一个 Sprint 的时间。”
我们用了 3 个月,把数据集成成本降到原来的 1/3,把实时性从小时级提升到分钟级,把开发周期从几周压缩到几天。
SeaTunnel 不是银弹,但它足够轻、足够快、足够开放。
只要你愿意动手,它就能成为你数据平台的“新引擎”。
扫码加入 SeaTunnel 微信交流群
Apache SeaTunnel Apache SeaTunnel是一个云原生的多模态、高性能海量数据集成工具。北京时间 2023 年 6 月1 日,全球最大的开源软件基金会ApacheSoftware Foundation正式宣布Apache SeaTunnel毕业成为Apache顶级项目。目前,SeaTunnel在GitHub上Star数量已达8k+,社区达到6000+人规模。SeaTunnel支持在云数据库、本地数据源、SaaS、大模型等170多种数据源之间进行数据实时和批量同步,支持CDC、DDL变更、整库同步等功能,更是可以和大模型打通,让大模型链接企业内部的数据。
https://github.com/apache/seatunnel https://seatunnel.apache.org/ https://seatunnel.apache.org/download 我们相信,在 「 Community Over Code 」 (社区大于代码)、 「Open and Cooperation」 (开放协作)、 「Meritocracy」 (精英管理)、以及「 多样性与共识决策」 等 The Apache Way 的指引下,我们将迎来更加多元化和包容的社区生态,共建开源精神带来的技术进步! 我们诚邀各位有志于让本土开源立足全球的伙伴加入 SeaTunnel 贡献者大家庭,一起共建开源! https://github.com/apache/seatunnel/issues https://github.com/apache/seatunnel/pulls dev-subscribe@seatunnel.apache.org https://join.slack.com/t/apacheseatunnel/shared_invite/zt-1kcxzyrxz-lKcF3BAyzHEmpcc4OSaCjQ https://x.com/ASFSeaTunnel