概述
Apache 作为现代化的数据编排平台,在实际部署和使用过程中可能会遇到各种故障和问题。本文将从架构层面深入分析常见故障类型,提供详细的排查思路和解决方案,帮助运维人员和开发者快速定位并解决问题。
系统架构与核心组件
在开始故障排查前,首先需要了解DolphinScheduler的核心架构:

常见故障分类与排查
1. 服务启动失败
症状描述
排查步骤

解决方案
端口冲突:修改对应服务的端口配置
# Master服务端口server.port=5678# API服务端口 server.port=12345properties
内存不足:调整JVM参数
# 在启动脚本中增加内存参数export JAVA_OPTS="-Xms2g -Xmx4g"
依赖服务未启动:确保Zookeeper和数据库服务正常运行
2. UI无法登录或访问异常
症状描述
排查表格

详细排查流程
检查API服务连通性
curl http://localhost:12345/dolphinscheduler/users/get-user-info
验证Session配置
# 检查application.properties配置server.servlet.session.timeout=3600server.context-path=/dolphinschedulerproperties
前端资源检查
# 确认静态资源文件存在ls -la /path/to/ui/static/
3. 任务调度异常
症状描述
任务无法正常调度
任务状态卡在"提交中"
工作流实例无法生成
故障排查矩阵

具体解决方案
MasterServer检查
# 检查Master服务状态jps | grep MasterServer# 查看ZK注册状态echo stat | nc localhost 2181
WorkerServer资源监控
# 调整Worker资源配置worker.max.cpuload.avg=10worker.reserved.memory=0.3properties
ZK连接优化
# 增加ZK超时时间zookeeper.session.timeout=60000zookeeper.connection.timeout=30000properties
4. 数据库连接问题
症状描述
性能优化配置
# 数据库连接池配置spring.datasource.druid.initialSize=5spring.datasource.druid.minIdle=5spring.datasource.druid.maxActive=20spring.datasource.druid.maxWait=60000spring.datasource.druid.timeBetweenEvictionRunsMillis=60000spring.datasource.druid.minEvictableIdleTimeMillis=300000properties
排查步骤
连接池监控
-- 查看数据库连接数SHOW PROCESSLIST; -- 查看最大连接数配置SHOW VARIABLES LIKE 'max_connections';
慢查询分析
-- 启用慢查询日志SET GLOBAL slow_query_log = 'ON';SET GLOBAL long_query_time = 2;
索引优化
-- 分析常用查询的索引情况EXPLAIN SELECT * FROM t_ds_process_instance WHERE state = 1;
5. 网络与IP地址问题
症状描述
IP地址配置策略
DolphinScheduler支持多种IP获取策略:
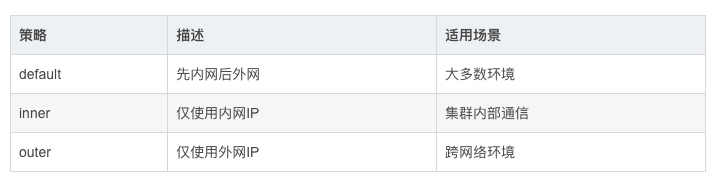
配置示例:
# 网络IP获取优先级策略dolphin.scheduler.network.priority.strategy=default# 指定网卡获取IPdolphin.scheduler.network.interface.preferred=eth0properties
网络连通性测试
# 测试节点间网络连通性ping worker-node-iptelnet worker-node-ip 12345 # 检查防火墙设置iptables -L -n
6. 资源管理与调度优化
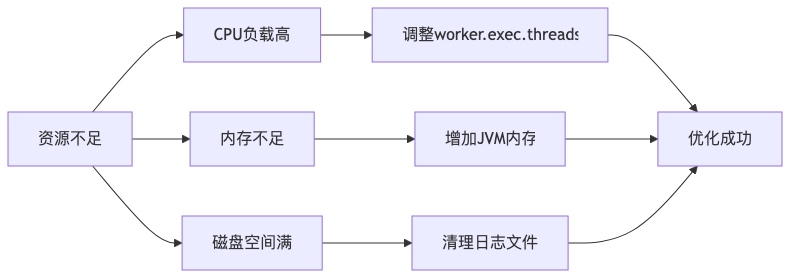
# Master并发控制master.exec.threads=100master.exec.task.number=20# Worker并发控制 worker.exec.threads=100# 资源预留配置master.reserved.memory=0.1worker.reserved.memory=0.1properties
7. 日志分析与监控
关键日志文件位置

日志分析技巧
错误模式识别
# 查找ERROR级别的日志grep "ERROR" logs/master-server.log # 查找特定时间段的日志sed -n '/2024-01-15 10:00:00/,/2024-01-15 11:00:00/p' logs/*.log
性能监控指标
# 监控服务CPU和内存使用top -p $(pgrep -f MasterServer) # 监控数据库连接数watch -n 5 "netstat -an | grep 3306 | wc -l"
8. 高可用与故障转移

# Zookeeper集群配置zookeeper.quorum=zk1:2181,zk2:2181,zk3:2181# 服务检测间隔master.heartbeat.interval=10worker.heartbeat.interval=10properties
总结
通过系统化的故障排查方法,可以快速定位和解决DolphinScheduler运行中的各种问题。关键要点包括:
预防优于治疗:建立完善的监控体系,提前发现潜在问题
日志为王:熟练掌握日志分析技巧,快速定位问题根源
资源配置:根据实际业务需求合理配置系统资源
高可用设计:采用集群部署确保系统稳定性
定期维护:建立定期检查和维护机制
遵循这些最佳实践,可以显著提高DolphinScheduler的稳定性和可靠性,确保数据工作流的高效运行。
原文链接:https://blog.csdn.net/gitblog_00253/article/details/151215102




