@RestControllerAdvicepublic class ApiExceptionHandler { @ExceptionHandler(Exception.class) public Result exceptionHandler(Exception e, HandlerMethod hm) { ApiException ce = hm.getMethodAnnotation(ApiException.class); if (ce == null) { return Result.errorWithArgs(Status.INTERNAL_SERVER_ERROR_ARGS, e.getMessage()); } return Result.error(ce.value()); }}
Swagger接口文档
系统集成Swagger2和SwaggerBootstrapUI,自动生成API文档:
访问路径:/swagger-ui.html
支持在线测试接口
完整的参数说明和示例
实时更新的接口文档
典型接口示例
创建项目接口:
@PostMapping()@ApiOperation(value = "create", notes = "CREATE_PROJECT_NOTES")@ApiException(CREATE_PROJECT_ERROR)public Result createProject(@RequestAttribute User loginUser, @RequestParam String projectName, @RequestParam(required = false) String description) { Map<String, Object> result = projectService.createProject(loginUser, projectName, description); return returnDataList(result);}
启动工作流实例:
@PostMapping("start-process-instance")@ApiOperation(value = "startProcessInstance", notes = "RUN_PROCESS_INSTANCE_NOTES")public Result startProcessInstance(@PathVariable long projectCode, @RequestParam long processDefinitionCode, @RequestParam FailureStrategy failureStrategy, @RequestParam WarningType warningType) { // 业务逻辑处理}
public class WorkflowCreator { private static final String API_BASE = "http://dolphinscheduler-api:12345/dolphinscheduler"; private static final String TOKEN = "your-auth-token"; public String createDailyETLWorkflow(long projectCode, String tenantCode) { // 构建任务定义JSON String taskDefinitionJson = buildTaskDefinitions(); // 构建任务关系JSON String taskRelationJson = buildTaskRelations(); // 构建请求参数 Map<String, Object> params = new HashMap<>(); params.put("name", "daily_etl_pipeline"); params.put("description", "Daily data extraction and loading workflow"); params.put("globalParams", "[{\"prop\":\"biz_date\",\"value\":\"${system.biz.date}\"}]"); params.put("timeout", 120); params.put("tenantCode", tenantCode); params.put("taskRelationJson", taskRelationJson); params.put("taskDefinitionJson", taskDefinitionJson); // 调用API String url = String.format("%s/projects/%d/process-definition", API_BASE, projectCode); return HttpClientUtils.post(url, params, TOKEN); } private String buildTaskDefinitions() { return "[" + "{\"code\":1001,\"name\":\"extract_mysql_data\",\"taskType\":\"SQL\"," + "\"taskParams\":\"{\\\"type\\\":\\\"MYSQL\\\",\\\"sql\\\":\\\"SELECT * FROM source_table WHERE dt='${biz_date}'\\\"}\"," + "\"description\":\"Extract data from MySQL\",\"timeout\":30}," + "{\"code\":1002,\"name\":\"transform_data\",\"taskType\":\"SPARK\"," + "\"taskParams\":\"{\\\"mainClass\\\":\\\"com.etl.Transformer\\\",\\\"deployMode\\\":\\\"cluster\\\"}\"," + "\"description\":\"Transform extracted data\",\"timeout\":60}," + "{\"code\":1003,\"name\":\"load_to_hive\",\"taskType\":\"HIVE\"," + "\"taskParams\":\"{\\\"hiveCliTaskExecutionType\\\":\\\"SCRIPT\\\",\\\"hiveSqlScript\\\":\\\"INSERT INTO target_table SELECT * FROM temp_table\\\"}\"," + "\"description\":\"Load data to Hive\",\"timeout\":30}" + "]"; } private String buildTaskRelations() { return "[" + "{\"name\":\"\",\"preTaskCode\":0,\"postTaskCode\":1001}," + "{\"name\":\"\",\"preTaskCode\":1001,\"postTaskCode\":1002}," + "{\"name\":\"\",\"preTaskCode\":1002,\"postTaskCode\":1003}" + "]"; }}
工作流管理操作API
除了创建工作流,DolphinScheduler 还提供了完整的管理API:
查询工作流列表
@GetMapping()public Result queryProcessDefinitionListPaging( @RequestAttribute(value = Constants.SESSION_USER) User loginUser, @PathVariable long projectCode, @RequestParam(value = "searchVal", required = false) String searchVal, @RequestParam(value = "pageNo") Integer pageNo, @RequestParam(value = "pageSize") Integer pageSize)
更新工作流定义
@PutMapping(value = "/{code}")public Result updateProcessDefinition( @RequestAttribute(value = Constants.SESSION_USER) User loginUser, @PathVariable long projectCode, @RequestParam(value = "name", required = true) String name, @PathVariable(value = "code", required = true) long code, // ... 其他参数与创建API类似 @RequestParam(value = "releaseState", required = false) ReleaseState releaseState)
发布/下线工作流
@PostMapping(value = "/release")public Result releaseProcessDefinition( @RequestAttribute(value = Constants.SESSION_USER) User loginUser, @PathVariable long projectCode, @RequestParam(value = "code") long code, @RequestParam(value = "releaseState") ReleaseState releaseState)
批量操作支持
对于大规模工作流管理场景,DolphinScheduler 提供了批量操作API:
// 批量复制工作流@PostMapping(value = "/batch-copy")public Result copyProcessDefinition( @RequestAttribute(value = Constants.SESSION_USER) User loginUser, @PathVariable long projectCode, @RequestParam(value = "codes", required = true) String codes, @RequestParam(value = "targetProjectCode", required = true) long targetProjectCode) // 批量移动工作流 @PostMapping(value = "/batch-move")public Result moveProcessDefinition( @RequestAttribute(value = Constants.SESSION_USER) User loginUser, @PathVariable long projectCode, @RequestParam(value = "codes", required = true) String codes, @RequestParam(value = "targetProjectCode", required = true) long targetProjectCode) // 批量删除工作流@DeleteMapping(value = "/batch-delete")public Result batchDeleteProcessDefinition( @RequestAttribute(value = Constants.SESSION_USER) User loginUser, @PathVariable long projectCode, @RequestParam(value = "codes", required = true) String codes)
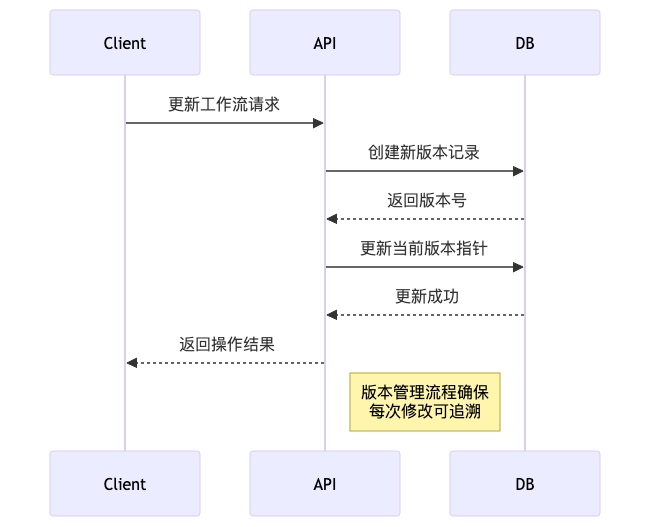
工作流版本管理
DolphinScheduler 支持工作流版本控制,每次修改都会生成新的版本:
版本查询API示例:
@GetMapping(value = "/{code}/versions")public Result queryProcessDefinitionVersions( @RequestAttribute(value = Constants.SESSION_USER) User loginUser, @PathVariable long projectCode, @RequestParam(value = "pageNo") int pageNo, @RequestParam(value = "pageSize") int pageSize, @PathVariable(value = "code") long code)