本文介绍了基于 的离线数据治理平台,解决了任务依赖黑洞和扩展性瓶颈问题。通过 YAML 动态编译和血缘自动捕获,实现了高效的任务依赖管理和数据追踪。平台使用 Neo4j 图数据库进行血缘存储,支持秒级影响分析和根因定位。此外,结合自研高性能导入工具,大幅提升数据传输效率。
背景与挑战
在日均处理PB级数据的背景下,原有调度系统面临两大核心问题:
任务依赖黑洞:跨系统任务(Hive/TiDB/StarRocks)依赖关系人工维护,故障排查耗时超30分钟
扩展性瓶颈:单点调度器无法支撑千级任务并发,失败重试机制缺失导致数据延迟率超5%
技术选型
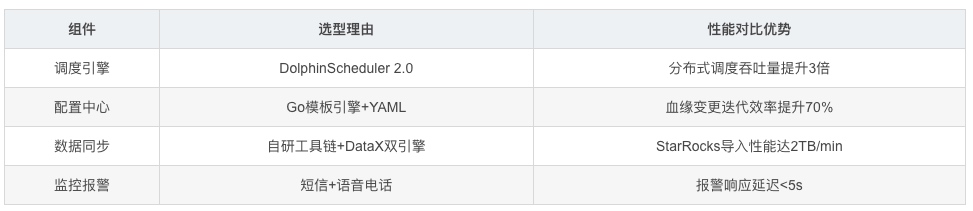
核心架构设计
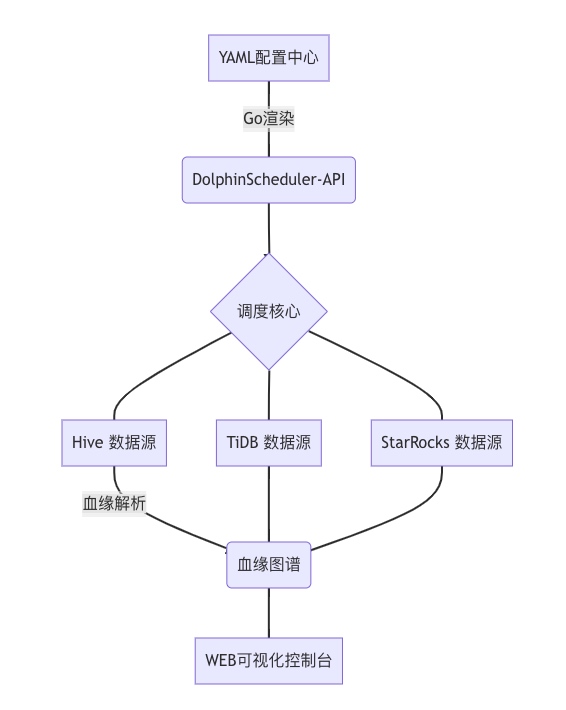
关键技术实现:
YAML动态编译
type TaskDAG struct { Nodes []Node `yaml:"nodes"` Edges []Edge `yaml:"edges"`}func GenerateWorkflow(yamlPath string) (*ds.WorkflowDefine, error) { data := os.ReadFile(yamlPath) var dag TaskDAG yaml.Unmarshal(data, &dag) // 转换为DolphinScheduler DAG结构 return buildDSDAG(dag) }血缘自动捕获
通过拦截SQL执行计划解析输入/输出表
非SQL任务通过Hook捕获文件路径
# StarRocks Broker Load血缘捕获def capture_brokerload(job_id): job = get_job_log(job_id) return { "input": job.params["hdfs_path"], "output": job.db_table }核心难题解决方案
零事故迁移方案
自研高性能导入工具

核心优化点:
func (w *StarrocksWriter) batchCommit() { for { select { case batch := <-w.batchChan: w.doBrokerLoad(batch) // 动态调整batchsize w.adjustBatchSize(len(batch)) } }}血缘管理实现
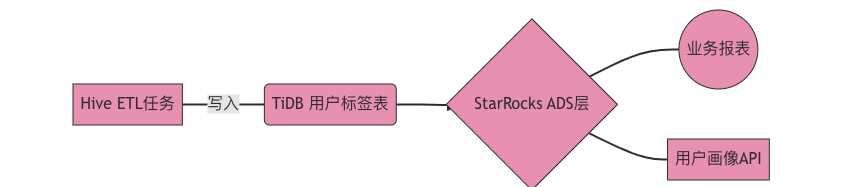
血缘存储采用图数据库Neo4j,实现:
影响分析:表级变更秒级定位影响范围
根因定位:故障时30秒内追踪问题源头
合规审计:满足GDPR数据溯源要求
性能收益

原文链接:https://blog.csdn.net/guichenglin/article/details/149216068




