
TaskExecutionServer 是一个用于执行 Task 的服务,会在每个节点上运行一个实例。 它接收来自 JobMaster 的 TaskGroup 并运行其中的 Task,还维护着 TaskID 到 TaskContext 的映射,具体的 Task 操作封装在 TaskContext 中。
Task 内部持有 OperationService,这意味着 Task 可以通过 OperationService 远程调用并与其他 Task 或 JobMaster 通信。
TaskGroup 中的所有任务都在同一个节点上运行。
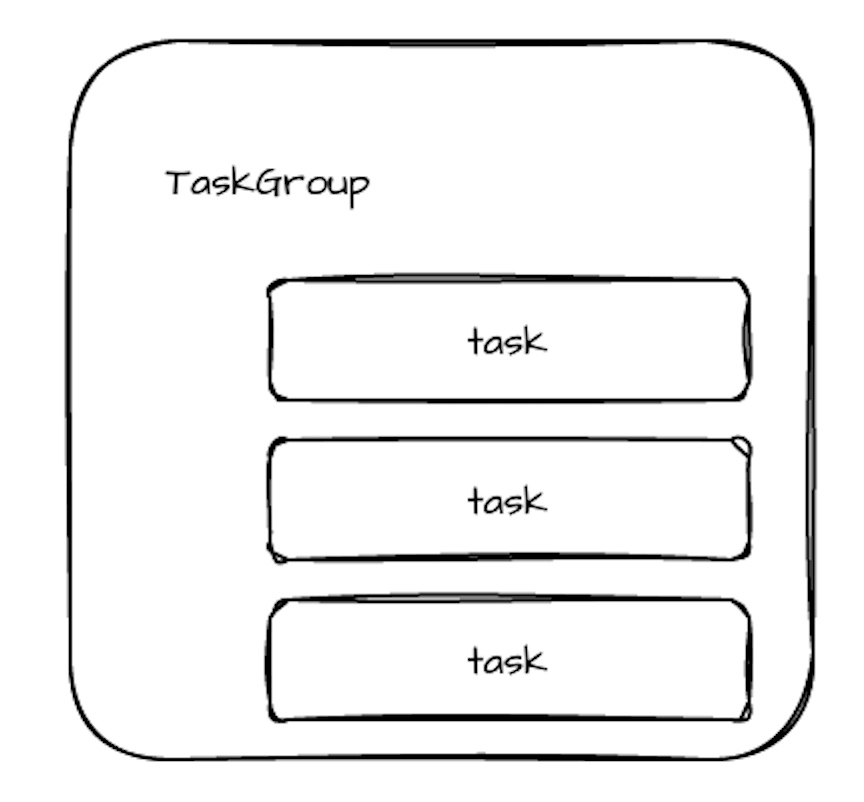
同一个 TaskGroup 中任务之间的数据通道使用本地队列,而不同 TaskGroup 之间可能会使用分布式队列(如 Hazelcast 的 Ringbuffer),因为它们可能被分配到不同节点上执行。
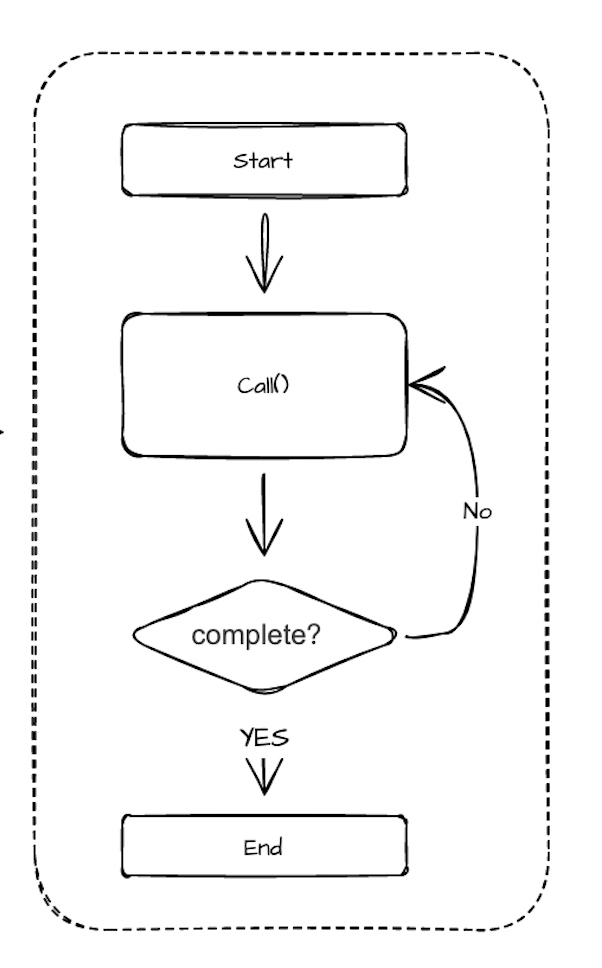
call()的ProgressState 返回Task 中最关键的方法之一是 call(),executor(执行器)通过反复调用 Task 的 call() 方法来驱动任务的执行。
该 call() 方法会返回一个 ProgressState,执行器可以通过它判断任务是否已经结束,或者是否还需要继续调用。如下图所示:
线程共享在需要同步大量小任务的场景中,会产生大量的任务。如果每个 Task 都使用一个线程,那会导致大量线程运行,造成资源浪费。
此时,如果能让一个线程运行多个 Task,就能大幅优化资源使用。
但问题在于,一个线程如何能执行多个任务?
由于 Task 是通过反复调用 call() 来驱动的,因此一个线程可以轮流调用它负责的多个 Task 的 call() 方法来实现并发执行。如下图所示: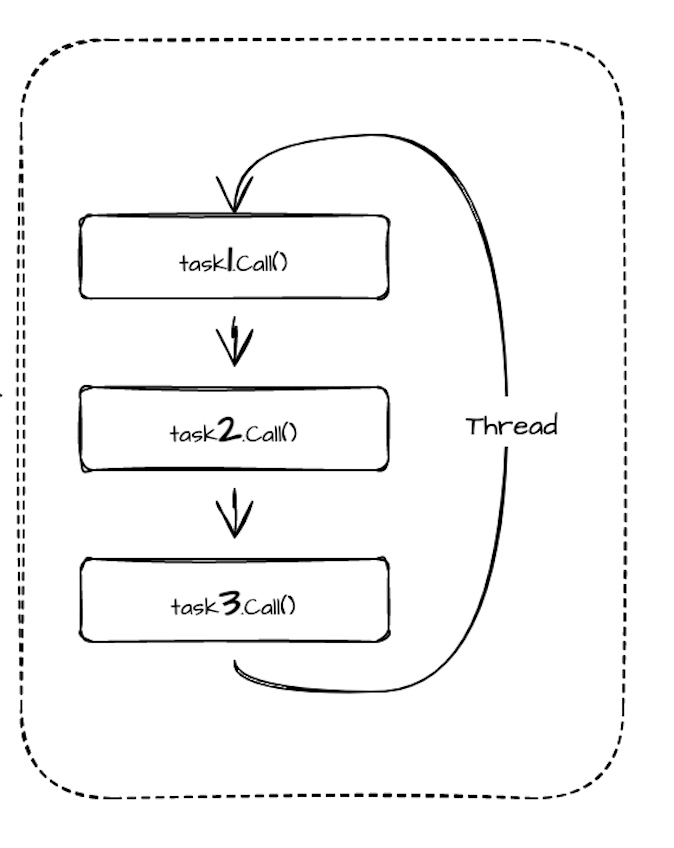
但这也会带来一个问题:如果某个任务的 call() 执行时间非常长,该线程会被这个任务长时间占用,从而导致其它共享该线程的任务延迟严重。
为了解决这个问题,我想到以下两个优化策略:
为 Task 提供一个标记,用于指示该任务是否支持线程共享。
在具体任务的实现中,由开发者评估和标记这个 Task 是否支持线程共享。
判断标准可以是 call() 方法的执行时间:如果始终在毫秒级以内,则可以将该任务标记为支持线程共享。
上述静态标记方案存在一个根本问题:call() 方法的执行时间通常不可预测,Task 自身也难以判断。
因为任务在不同阶段、处理的数据量不同,会直接影响 call() 的耗时。
因此,用固定标记来区分是否支持线程共享不够准确。
一旦某个标记为“可共享”的任务出现了长时间运行,就会严重影响其它任务。而不共享线程又会造成资源浪费的问题依然存在。
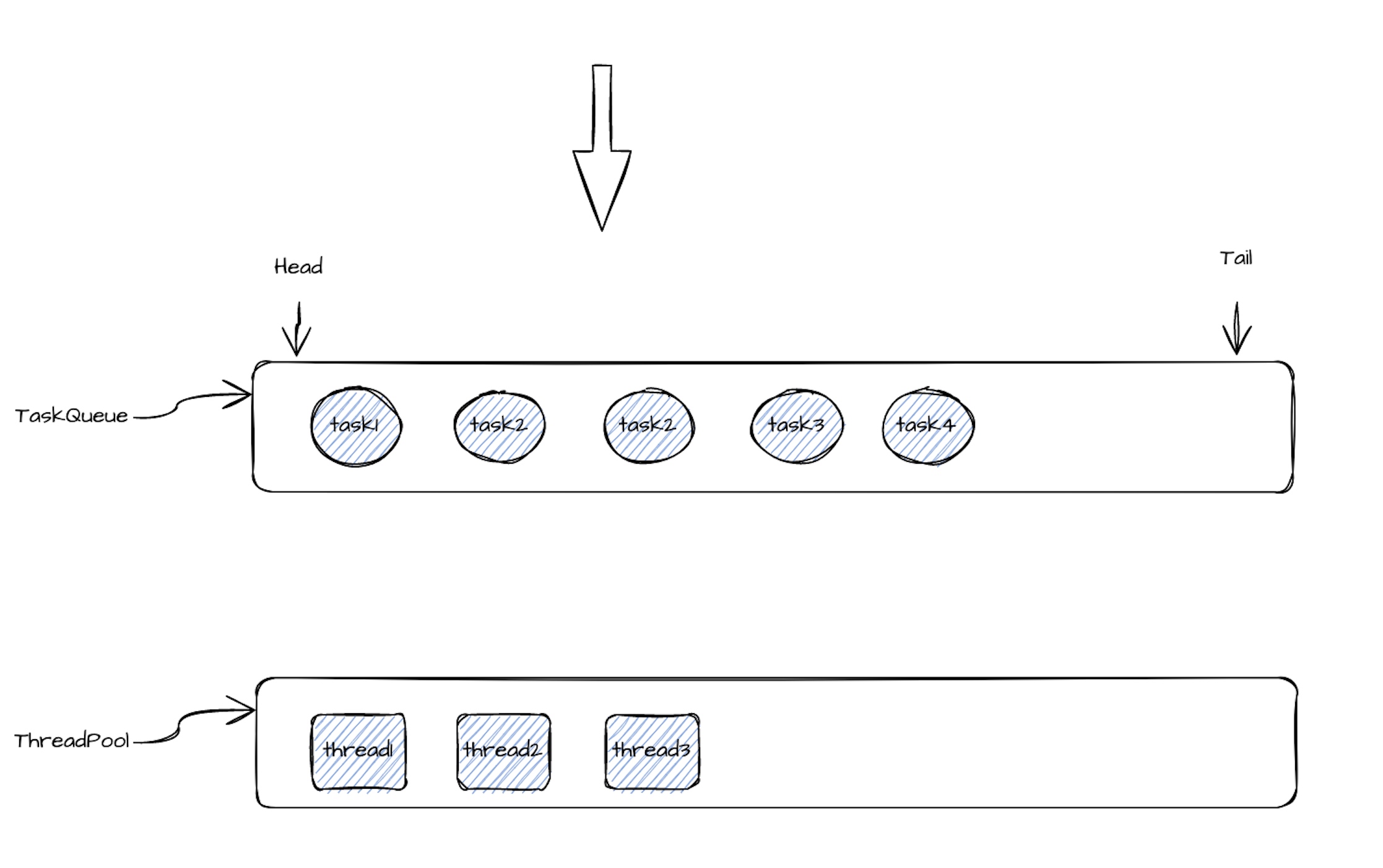
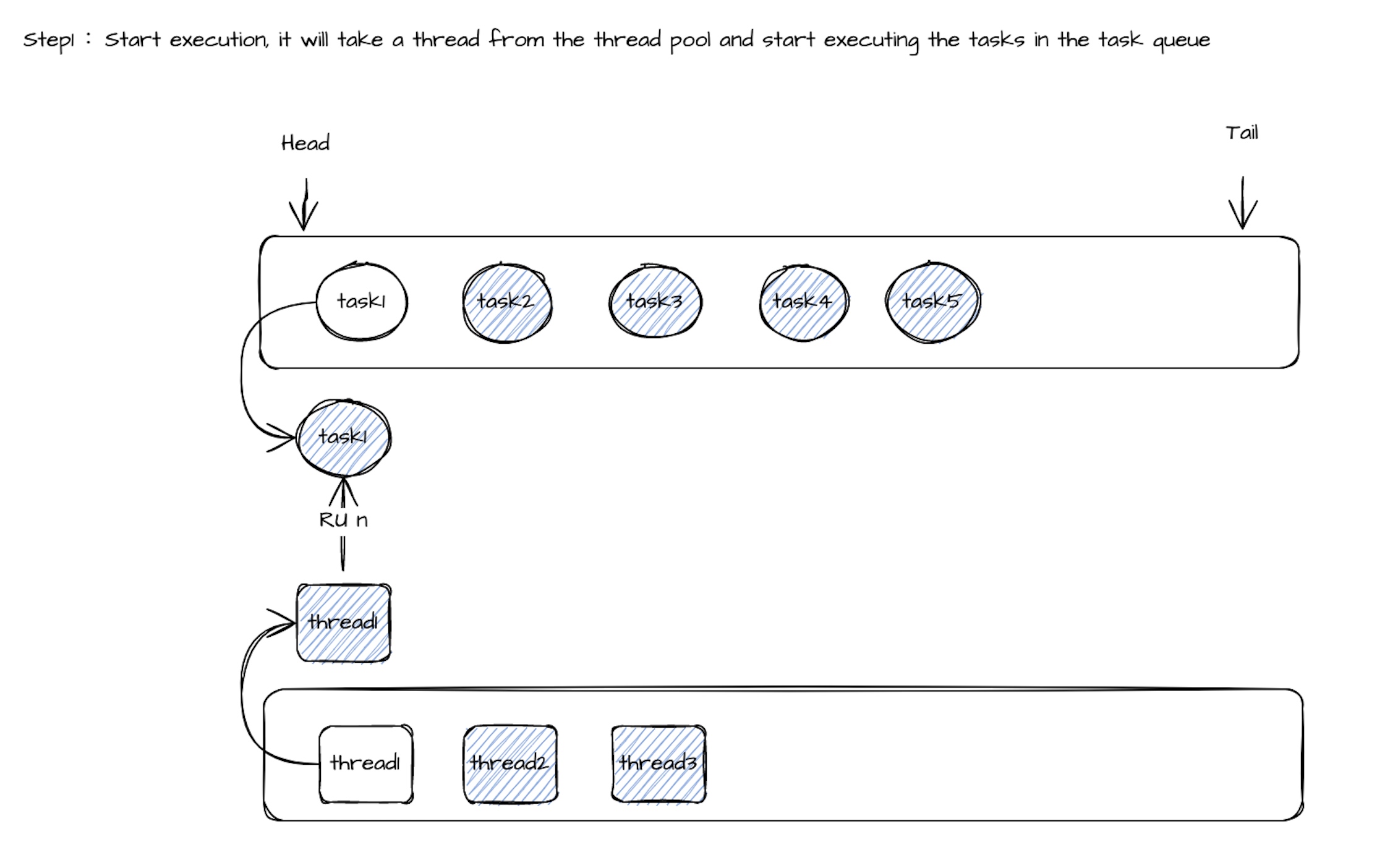
因此,建议采用动态线程共享机制:让一组任务通过一个线程池来调度执行(任务数 >> 线程数)。
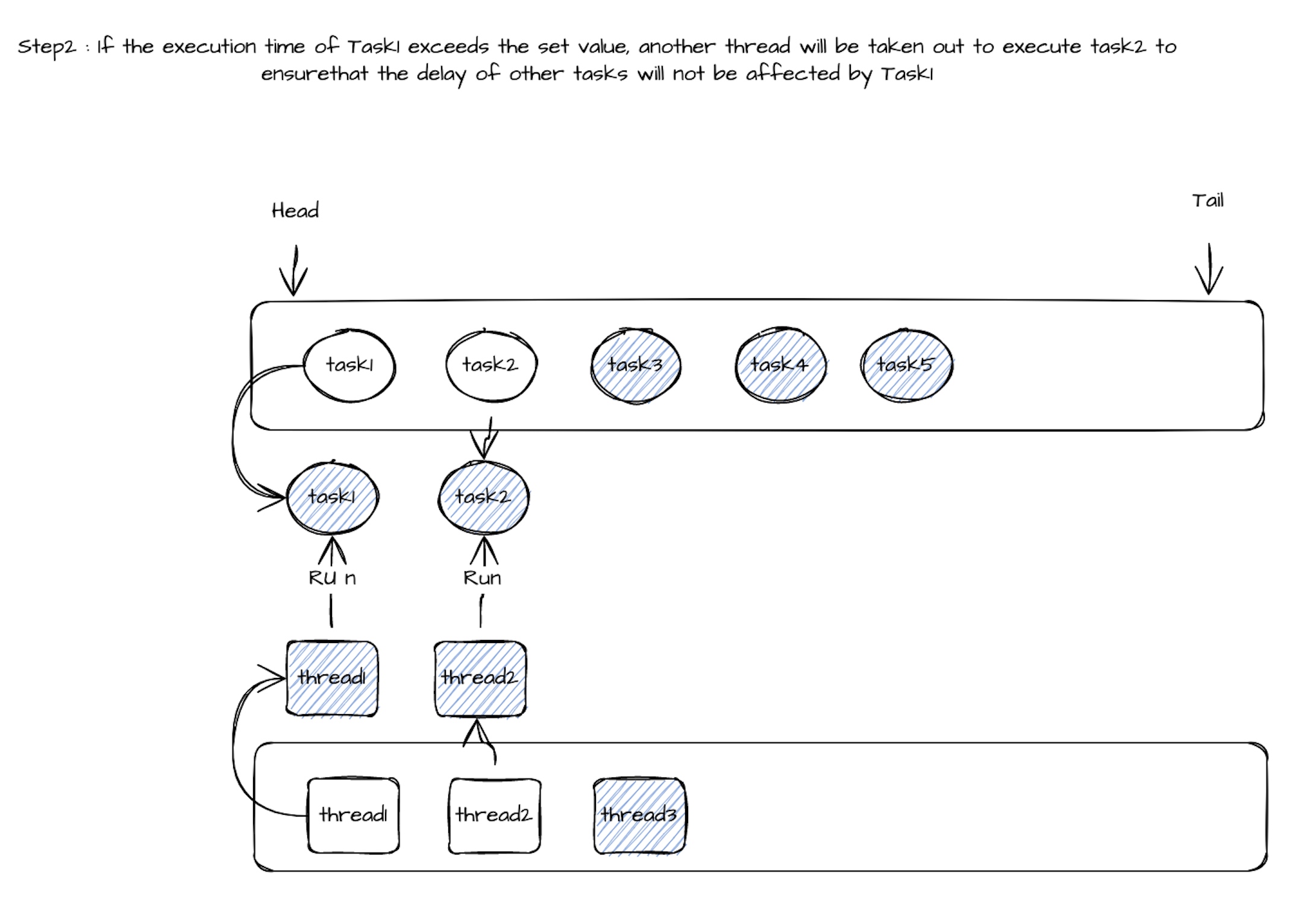
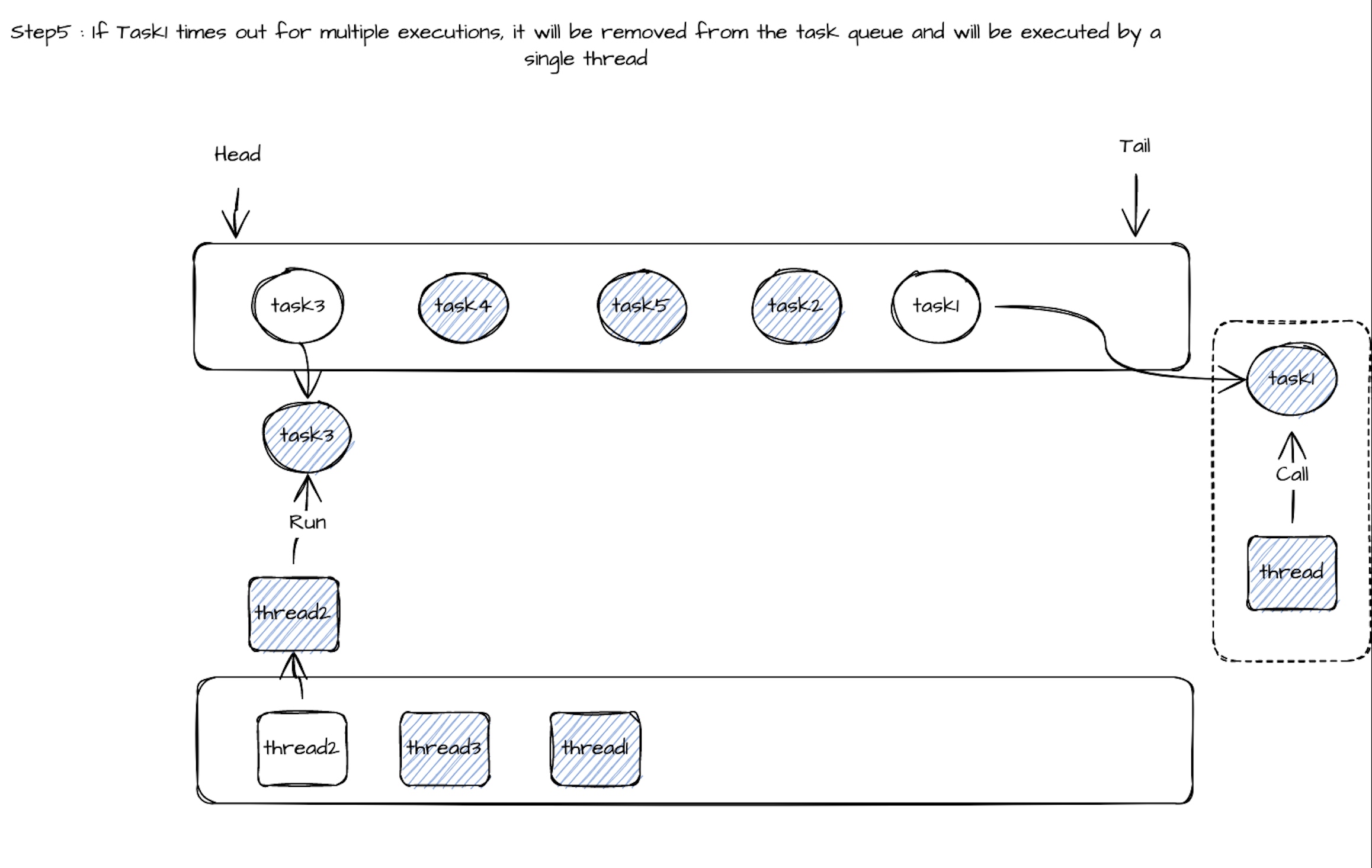
当线程 thread1 执行 Task1 的 call() 方法时,如果执行时间超过设定值(如 100ms),就从线程池中取出 thread2 来执行 Task2 的 call()。
这样就能避免因为 Task1 执行时间太长而影响其它任务的执行延迟。
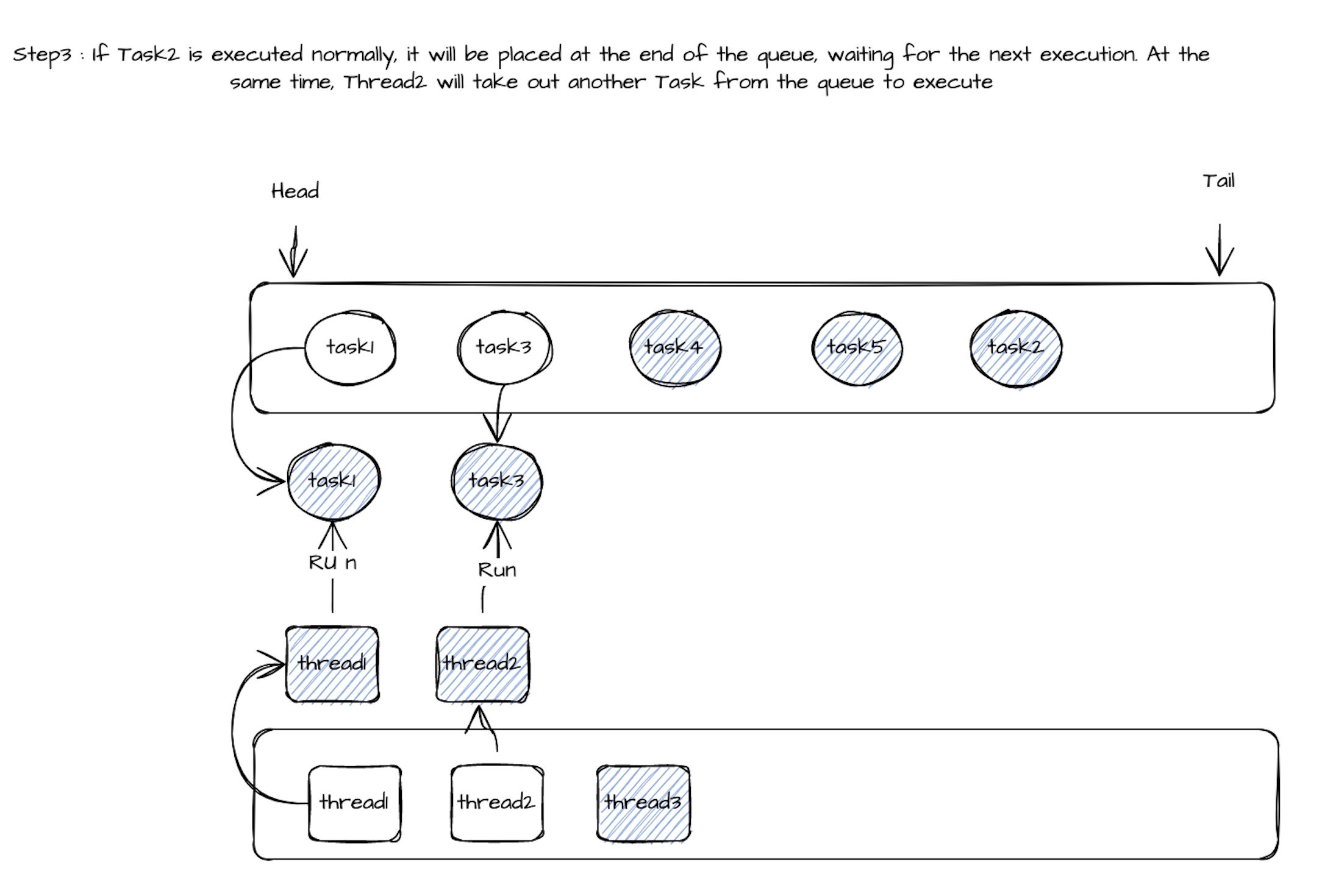
如果 Task2 的 call() 方法在超时时间内正常完成,它会被重新放回队列尾部等待再次调度,thread2 则会继续从队列中取出下一个任务(如 Task3)执行。
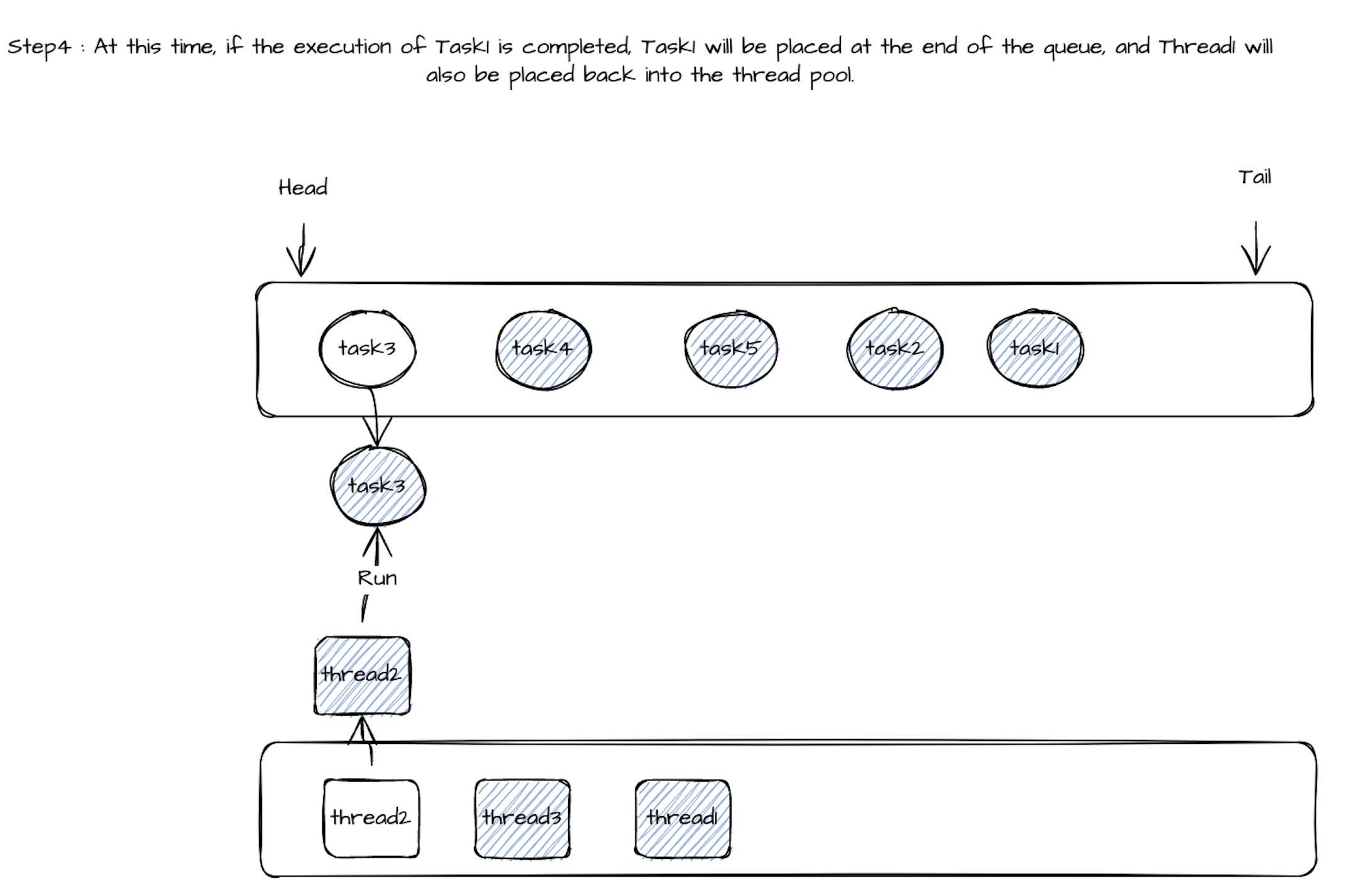
当 Task1 的 call() 执行完后,thread1 会被释放回线程池,同时记录 Task1 的一次“超时”行为。
当一个任务的超时次数达到某个限制后,它将被从共享队列中移除,之后独占一个线程来执行。
相关执行流程如下:
随着任务执行模型的不断演进,Apache SeaTunnel 在高并发、小任务场景下的资源调度能力也在持续优化中。本文档提出的线程共享机制,既提升了执行效率,又保障了任务的响应性能,是Apache SeaTunnel Zeta 引擎性能比同类产品更快、性能复更高的重要因素。
如果你还有更好的想法,真诚欢迎你来 GitHub,提出你的 idea,参与共建更高效、更稳定的数据集成引擎!